If I continuously get data from other source and save the data into a SQL DB, assuming that predictor is ready, then how to realize the following functions:
define a time interval, say 30 secs, read the new data from SQL DB which flow in in the past 30 secs;
then trigger the predictor and send prediction to a file.
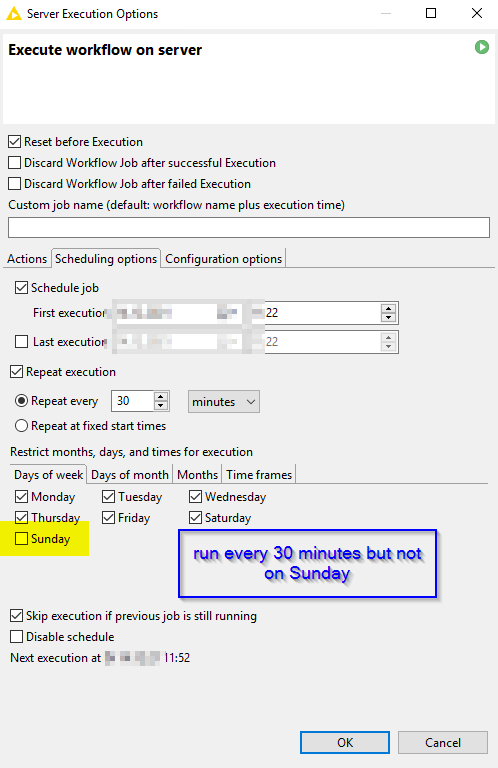
I have constructed a demo that uses a (permanent) loop and executes a job at a certain time. You could also have a version that would so somthing if there is a change. Question is would this be a stable production system. It was meant to demonstrates what can be done.
thanks for the info.
one question: how to only allow the new data which flow in the last 30 secs to be read? I would assume that new data keep on accumulating in the same DB.
you will need some sort of indicator. That might be a timestamp or an ID (or both) that you would store and then make sure that you only transfer the newest ones. One possibility is to use unique Primary Keys (if that is what your database is all about).
Hi @HY_Z@mlauber71 , while the permanent (infinite) loop can be an option, it’s not my preferred option. I would rather have the workflow run every 30 secs. This can be achieve with a Knime server as per @mlauber71 's suggestion, and if you don’t have access to a Knime server as is @HY_Z 's case, you can run the workflow as a command line on your station and schedule the job to be executed via your OS’s scheduler (Windows scheduler, UNIX/Linux/MacOS cron)
The problems I have with running the job via an infinite loop are:
o Your Knime AP has to be opened for it to run
o It can be resource intensive memory-wise, with Knime keeping track of the iterations
o Should there be any problem, such as system running low on resources, and the workflow crashes, you need to manually restart the workflow. Imagine this happening in the middle of the night. The scheduler will run the next schedule automatically