I am trying to remove duplicate rows based on the transaction id & charge amount ( IE, while it’s possible to have the same transaction ID, the charge amount will be different. )
Are there any suggested nodes?
I am trying to remove duplicate rows based on the transaction id & charge amount ( IE, while it’s possible to have the same transaction ID, the charge amount will be different. )
Are there any suggested nodes?
Hi @CarishmaM and welcome to the forum.
You can try the Duplicate Row Filter node for this. 
Hi Scott - I tried this option, but it doesn’t seem to help much because I using two tables.
I was using the Reference Row Filter, but it only allows for the one criteria versus both.
Maybe you need to concatenate or join your data first? It’s hard to say without more details.
Can you post some example/dummy input data, along with what you would expect the output to look like?
I have two data sets similar to the image above. The first data set only has data from February 1-14. The second data set has data from February 1-28. I need to identify which rows in the first set have been duplicated into the second set and remove it.
@CarishmaM you could maybe benefit from these discussions:
In that case I would use a Concatenate first to stack your two tables together, followed by a Duplicate Row Filter. There may be more efficient ways to do it, but if I understand you correctly, that should work.
You can add to each table an identifier column, e.g., constant int value → concatenate - > duplicate row filter → row splitter and tou have your table back. Check the proper options in the filter to ensure that e.g. rows are removed and the order of the rows is being maintained
Okay, so I was able to get this method to work. What if I want to remove all the duplicate. IE if line 1&2 is the same, and I want them both gone?
I suppose in that case you could do a count aggregation with a GroupBy node, then afterward filter out results with counts > 1?
Is there a way to use the GroupBy node without changing how the data is formatted as the output?
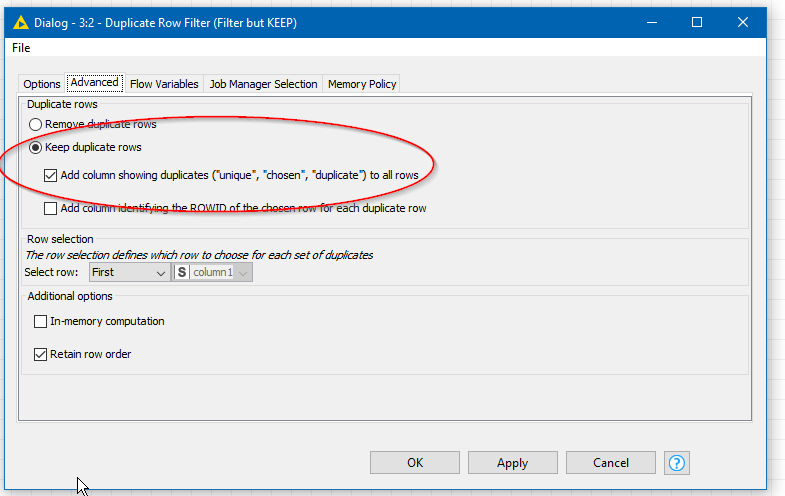
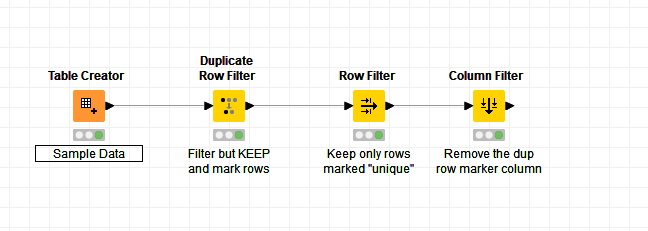
Possibly an easier way if you want to remove ALL duplicate rows is to continue using the Duplicate Row filter but tell it to keep duplicate rows and add a column marking duplicates
This column will then have one of three values in each row:
unique - the row is not seen as duplicated
chosen - the row is duplicated and marked as the one to keep
duplicate - the row is duplicated and is marked as one to discard
As you can see the ones you want to remove are either marked “chosen” or “duplicate” so add a row filter to keep only those marked “unique”. Finally a column filter can be used to remove the additional row marker column.
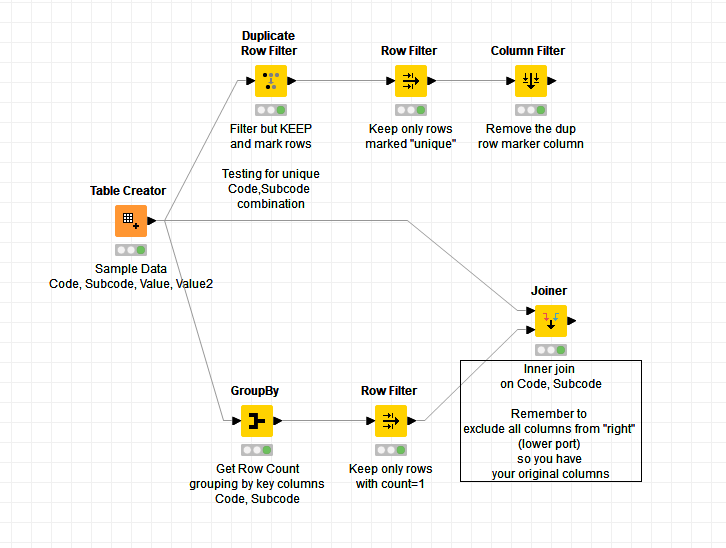
Re the question of retaining formatting (which I took to mean the keeping the original table columns), should you use the Group By route (as this pattern is useful to know for use cases other than just duplicates removal)
It’s basically the same number of nodes, to achieve the same result:
I was able to get this method to mostly work. I have been trying to use the Dates, Transacition # and Amount to filter out for duplicates. However, the Duplicate Row Filter identifies all of the rows as unique when I include the Date as a criteria.
Would you be able to explain more on how to use the GroupBy node?
Hi @CarishmaM,
It sounds like you need to take a step back slightly and define exactly how you are classing your rows as being “unique” or “duplicate”.
If you look at the combination of Transaction#, Amount and Date… are they unique?
If you look at the combination of just Transaction#, Amount (without Date) are they unique?
If you want to find rows with the same Transaction# and Amount, irrespective of the date, then you need to use just Transaction# and Amount as your “duplicate” criteria.
If you include date, and you have two different dates for the same Transaction# and Amount, then the combination of Transaction#, Amount and Date will result in a unique row.
When I look at these problems, I try to think what would I do to solve this if I were having to do it manually (i.e. If I were not using Knime, or any other tool). If I can describe the process manually, then I’m half way (sometimes,  ) to solving it with Knime.
) to solving it with Knime.
Using the Group By node will give you the same results that you are getting with the duplicate rows filter if you specify the same criteria (i.e. if set of columns you group by is the same set you use to determine duplicates).
In terms of explaining more on how to use the GroupBy node… what is it you need to know? I can probably help with specific questions, but for a general “how to” there are better teachers than me, such as:
If you would like to upload a sample workflow, with a small sample data that demonstrates the problem you are having (you can remove or replace any private information), then I, and others will happily try to give guidance on what you need to do.
edit: This is a demo workflow I used for creating the earlier screenshots, if that helps:
KNIME_remove_duplicates.knwf (16.7 KB)
Thanks so much for the information. When filtering out the data, I was hoping I could get knime to first look at the Transaction, then the Amount, and then the Date to decide whether it is a duplicate or unique.
This would reduce the area of maybe identifying a row as duplicate when in fact it is not. I’ll post the example shortly.
Hi @CarishmaM , if you are looking at three fields, (Transaction ID, Amount and Date) , and looking to see if a row is duplicate compared with another row, then with 3 fields there are only 8 possibilities:
In this image we have a baseline row with transaction id, amount and date containing values A, B, C. There are 8 variations of other rows that the test for duplication needs to consider. “x” represents any non-matching value. I’m guessing that a difference in Transaction ID or Amount means it is not a duplication which means cases 1 to 6 are all considered “unique”. Case 8 is all fields the same, so this is clearly a duplicate. This only leaves the question of how to handle case7 (the date differs but ID and Amount are the same). How you want to handle that situation will be the determining factor of whether you include Date in you “grouping” or “duplicate row filter”.
(Unless you have some other rules that mean you want to base your decision on some other factor outside of these three columns).
If maybe, you are wanting to filter out all the case 8 duplications first, and then subsequently test what is left for duplication (case 7) within just the remaining set, then follow one “duplicate row filter” (on ID, Amount, Date) plus “row filter” node, with a second “duplicate row filter” + “row filter” node where this second process checks for just duplicated ID and Amount within the reduced set of rows.
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.