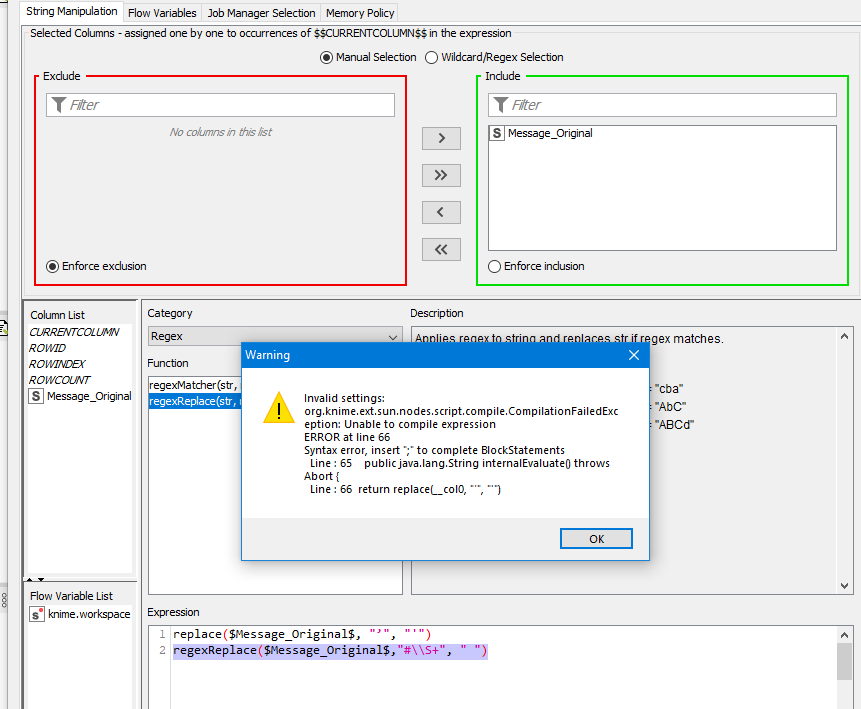
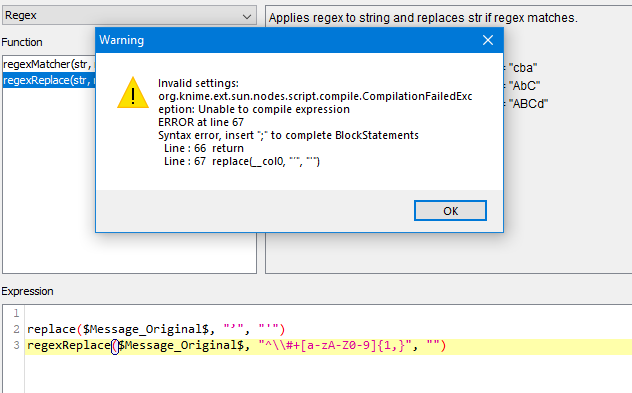
I have a table which has 1000 rows and 1 column (this column data type is string), some of the content has #content, #twitter, #123, etc. I want to remove anything start with hashtag, how should I do it? I tried String Manipulation node, but the regex function inside did not take my code. Any thoughts? I used: regexReplace($Message_Original$,"#\S+", “’”)
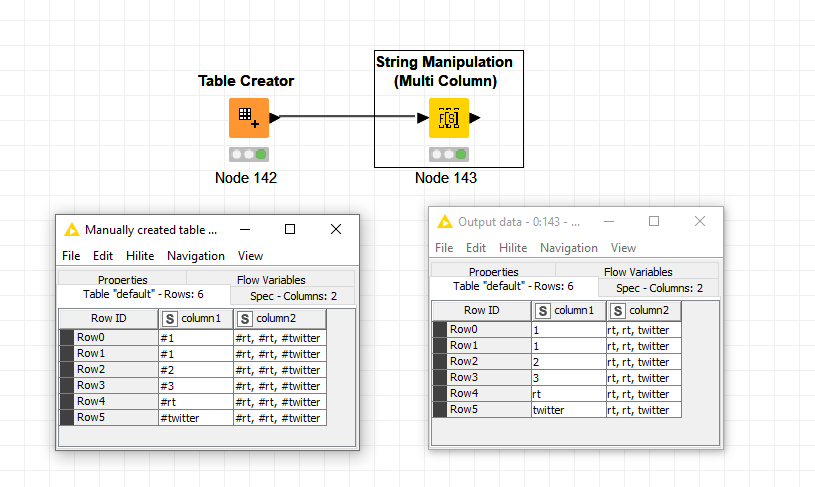
I just used “String Manipulation node (Multi column)” node (just in case your process change in the future, we never know) with : replace($$CURRENTCOLUMN$$,"#", "")
This way, it will sparse all columns at once, easy and fast, right ?
Inside the Text Processing metanode, there is an Extract Hashtags metanode. You can check how the hashtags are being identified and adapt it to your removal procedure. Worst case, you can do it in 2 steps:
Use it to extract the hashtags to a column
Do a replace using the new column - replace(original_column, new_column, “”)
Sorry I didn’t understand you well.
You should use something like that which delete # + letters and numbers that follows : "^\#+[a-zA-Z0-9]{1,}"
Details :
^ looks for everything that “start with” the following char (here the #, the\ is for escaping and avoiding errors),
+[a-zA-Z0-9] captures all letters or numbers following the “^#- start with #”,
EDIT: BTW @kwjKNIME , it’s not the double slash that is creating the error you are getting. The error you are getting is because you are trying to do 2 statements (replace and regexReplace).
The correct way to apply both replace would be like this: regexReplace(replace($Message_Original$, "’", "'"), "#\\w+", "")
Also, why are you using String Manipulation (Multi Column) if you are targeting only the column “Message_Original”? If you are going to target only 1 column, then use String Manipulation. If you are going to target multiple columns, then use “$$CURRENTCOLUMN$$” to manipulate each column via the String Manipulation (Multi Column).
Hi @kwjKNIME , not sure why you need 2 separate nodes here. I think you missed my post. I had actually explained why it was failing, and how to run both statements in the same nodes.
I also pointed out when to use which String Manipulation node (single column vs multi column), depending on what you want to do.
Please review my post if you missed it. You don’t need to use 2 nodes.
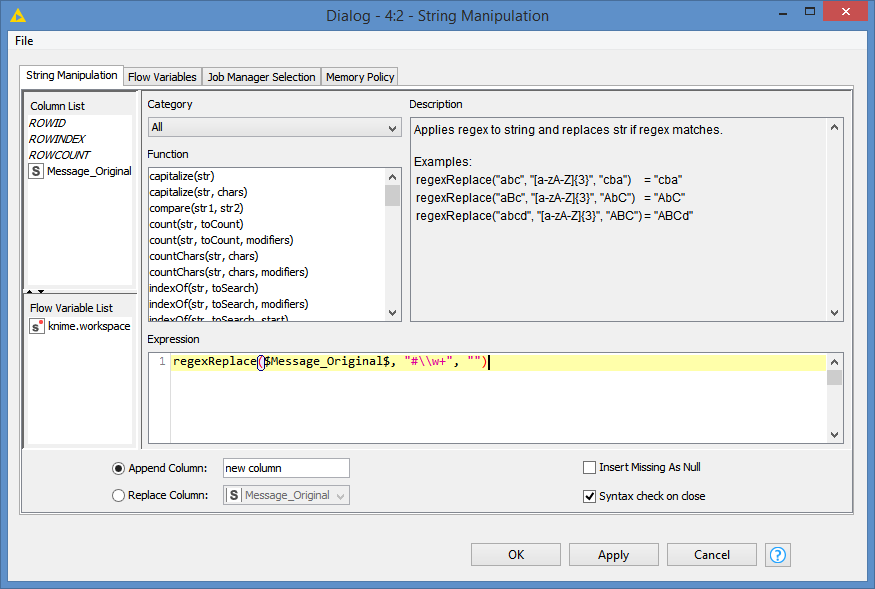
Also, "^\\#+[a-zA-Z0-9]{1,}" identifies hashtags at the beginning of the string only, while the statement I suggested "#\\w+" identifies all hashtags in the string. Not sure which one you need.
Yes you are correct that adding the quantifier will allow it to find all of the characters listed in the class rather than just the first one, but I don’t think that is what @bruno29a was referring to.
I think we can be reasonably agreed that in regex (ignoring any need for double backslash in the node, as I’m just talking plain regex here) [a-zA-Z0-9]{1,}
is almost semantically the same as \w+
in fact I think (if it included underscores) [a-zA-Z0-9_]{1,}
or [a-zA-Z0-9_]+
would be semantically identical to \w+
(I don’t know if the intention is to include underscores or not! )
But I think the main point bruno29a was making was about the use of the ^ at the beginning, so if that is included it will only match from beginning of line, as per the examples bruno29a gave, and as per the following examples:
So really, unless the request is to match only where the # appears at start of line, it shouldn’t include the ^ character.
btw…Lazy is good… I’m lazy too sometimes… when I can be bothered!
Thank you for the time you took to explain. I see. This is indeed tricky.
And, by the way, the shorter, the better, right ? After testing, removing the ^ works better indeed !
Well… I like concise and elegant, but sometimes longer is clearer. Maybe it depends on the target audience, or what you are personally comfortable with.
is * better than {0,} …?
is + better than {1,} …?
is \d better than [0-9] …?
I use them interchangeably, but if I’m giving it to somebody who is new to regex, maybe I’d stick with the [0-9] initially…
\w is useful and powerful, as is \s but I confess I keep having to look them up especially if I haven’t used them in a while, as I always forget which is which between \w and \W or \s and \S (and I often head over to regex101.com to try things out)
btw @SamirAbida , I’m enjoying reading your posts. It’s great to see a new and active contributor to the forum… I was in a similar position to you back in March… none of us knows everything… we’re all on one big learning journey!




 )
)