I need to remove the zeros on the data set below but its the 0’s in-between the initials and the numbers. The # of 0’s can fluctuate as long as there are 10 characters total. The 0’s are placed in if the ID initials or number is not long enough to fill in the 10 character slot.
First of all, thank you so much for replying. Since I am new to Knime can you explain what the regex is doing below? It looks like the formula you have is removing the zeros within the numbers such as BNSF474700 (original) with (BNSF4747). In essence, I need the formula to skip the example I have here as there are no zeros between BNSF and the numbers.
I am more than willing to manipulate the formula you have, but honestly have no clue as to where to start.
Hi @Einayyar
if it works for your problem then please mark it as the solution for your post so that others can find it.
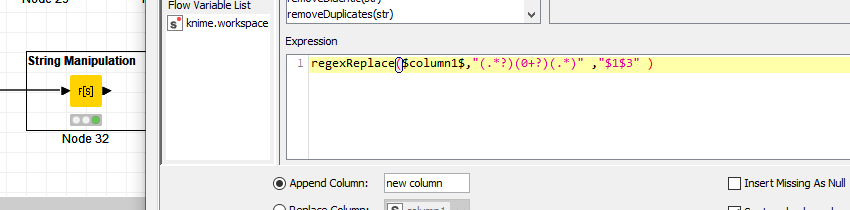
The “()” are groups in regular expressions which capture data. The dot “.” stands for any character. The star “*” is a multiplier and the questionmark makes the group “non greedy”.
So basically the first group catches everything up to the first “0” entry. The second group catches the 0s and the 3rd group catches everything after the 0s.
The $1$3 refers to the first and third group.
So basically split the data into 3 groups and return only the first and third group together.
best regards