Hi,
Can you share how to setup cross validation along with hyper parameter tuning and pick the best model from the training to train the model and use it for prediction.
Regars,
Vasudev
Hi,
Can you share how to setup cross validation along with hyper parameter tuning and pick the best model from the training to train the model and use it for prediction.
Regars,
Vasudev
Hi,
I’m new to Knime could you please help me to resolve this issue.
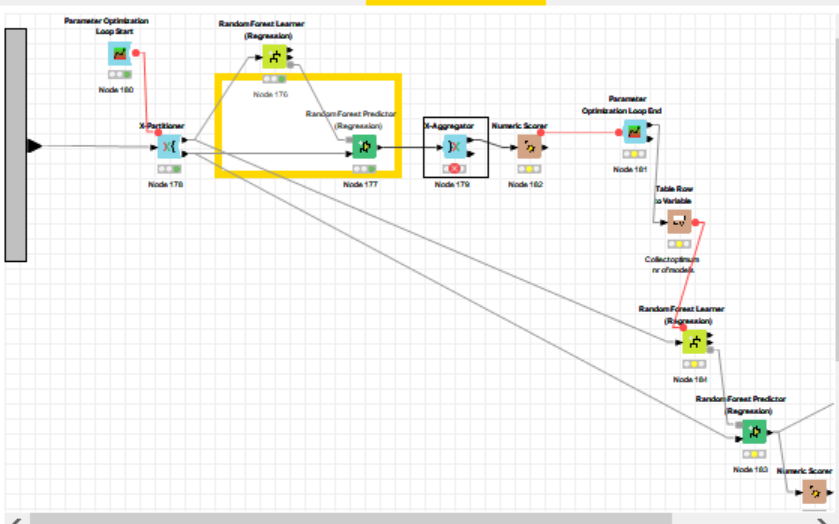
Attaching the error log. I’m running RandomForest Regression. My workflow is failing at X-aggregator step. Could you please suggest the fix for this problem.
Regards,
Vasudev
Hello @Vasudev and welcome to the KNIME community!
It looks like your loops aren’t set up properly. Any connections (table, flow variable, other) have to exit the loop body through the loop end node, they can’t “leave early”.
Have you tried connecting the Random Forrest Learner and Predictor to the X-Aggregator instead? This should fix the error.
Can’t help you with the Parameter optimisation stuff because I don’t know that topic myself.
@Thyme ,
Thank for your reply.
I’m able to setup only Cross Validation loop or only Parameter optimization loop with start and end node independently. The issue that i’m facing is to create an workflow to run cross validation with parameter optimaztion configuration. Can you share a quick solution how to do this setup.
Regards,
Vasudev
As I said, I’m not familiar with machine learning. I could tell from your screenshot though, that your loop setup is wrong. Loop End nodes don’t allow the outputs of any nodes within the loop body to connect to other nodes outside the loop body.
It’s like using the values of variables of the last iteration, which makes sense in programming, but it’s not possible in KNIME.
Since the Learner/Predictor to the right need data as input, you’d need to connect them to the Metanode input? And the incoming dataset should be split with a Partitioner node, to prevent the Predictor using the same data as the Learner.
Also, the numeric scorer gives the result as Column only, not as Flow Variables. You’d need to use a Table Column To Variable node between the scorer and the Parameter Optimisation Loop End.
There is no quick solution and it is rather complex to get right. You are for sure on the right track as most KNIME examples and their components simply ignore this and optimize on single splits (like the AutoML component). This is honestly sub optimal in my opinion. So good choice on not using it!
I have a pretty complex component for this (for binary classification!) with optimizations in it. I do the CV split once because the x-partitioner reruns on every optimization step and takes a considerable amount of time. It make runtime a lot faster to make splits only once. Also for each partition you need to to basic feature selection. I also do that once per precalculated partition.
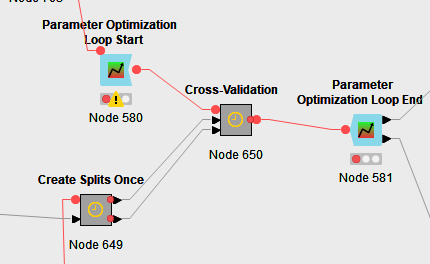
Create Splits Metanode:
The loop end has 2 out ports:
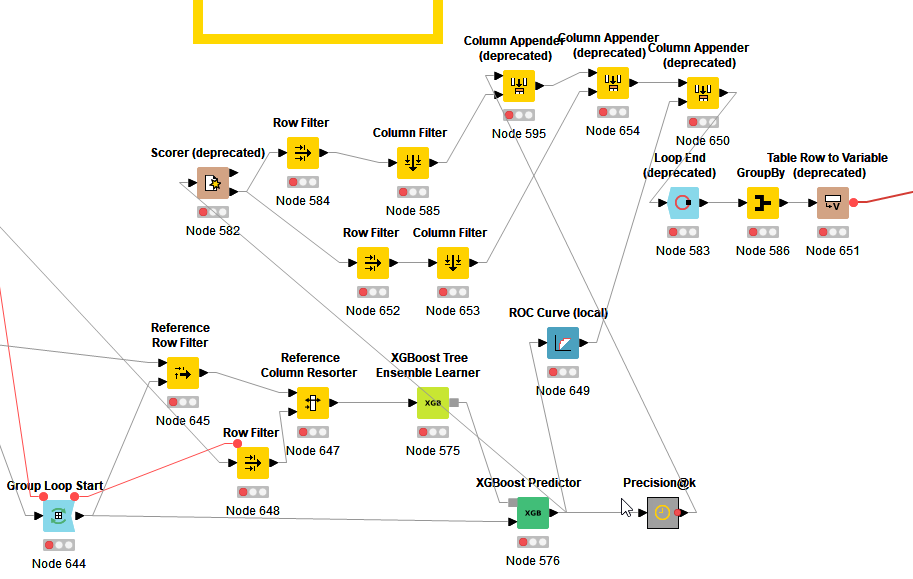
Then the Cross validation metanode is a huge mess I’m actually hesitant to even put a screenshot here. Not the type of person that needs everything to look super neat. Should probably be updated to newest KNIME version nodes:
Group loop start simply groups on the “fold” column. the current fold is used as test set, all others as training set. Which rows and features to use can be achieved form the precomputed folds and feature selection using reference row and reference column nodes.
Then the “big mess” is just getting the metrics of interest from the scorer into the right form to pass to the optimization end node. In fact the full component lets you select the target metrics from a predefined list.
At the end there is a final cv with the best model. The number of folds can differ to what was in the optimization loop. The component output contains flow variable port with the best parameters, a table with a row for each optimization loop and the parameter values and target metric.This is interesting to see if the optimization has any meaningful effect.
And a second output with the cross-validation results of the best chosen parameters.

What I’m not showing in the screenshots is a ton of config nodes for all the possible settings like range of the parameter optimization (shall it test from 50 to 500 tress or only from 80 to 120?), column selections (which is class column, which is the positive class!) and so forth. it’s a huge mess but works!
Conclusion: This should get you started. It is pretty complex but once done you can reuse it for a new problem, click on execute and go get a coffee (well a bit more it can run for hours depending on settings).
If someone can tell me how to completely get rid of initial configuration settings of the Configuration nodes I might clean it up and share it but the config nodes seem to retain initial values used when creating the component and that leaks information what I’m doing (target) which is not acceptable. 
Thanks for putting in lot of effort to put in your thoughts, I have come up with an workflow which look like this. Now I am trying to figure out to use the model best parameter for training and testing on partitioned data set.
Quick Reply: You can’t put the scorer how it in my opinion. You need to score each fold separately. Note that the x-partitioner loop can be closed by any loop end. The x-aggregator honestly isn’t really great for ending that if you want to score each fold separately and get statistics like std. deviation.
@kienerj , can you explain why do you say, why x-aggregator is not the best node and how should I collect the aggregated value. Sorry for the delayed reply.
Regards,
Vasu
That is my personal opinion. It just doesn’t add anything useful over a simple loop end