Hello, I was trying to understand if there is a smart way for optimize/speed-up the loading of the Spark to Datebase node. Cause I’m trying to import a big dataset to a mysql database. But it’s huge and it seems still loading after a couple of hours.
I’m afraid that probably he is doing a single massive insert stmt… is there such a way to insert n rows at time?
Could you give us a little more context? Spark and Databases is influenced by several factors all of which might play a role:
Spark does lazy execution. Question is how complicated are the tasks you do before storing the data in MySQL - if the Spark nodes in KNIME are green that only means the checks are completed - Spark would only start to work once you force it to actually bring back results (you might check the KNIME log for clues where your workflow actually stands)
then the whole thing might be heavily influenced by the overall performance of you Big Data system (is it running on a cluster or do you use your own machine with the local KNIME big data environment?) - please note Big Data systems need some overhead in starting the various instances, so they initially might be even slower than regular DBs (they later make good on it in being able to -well- perform big data operations )
how is the connection between your Big Data cluster and your MySQL DB? Please keep in mind that whatever data you send there must go thru the network or the IO of the machine. That is while if you are dealing with really huge datasets you do not send it via network cables but use Big Data instead.
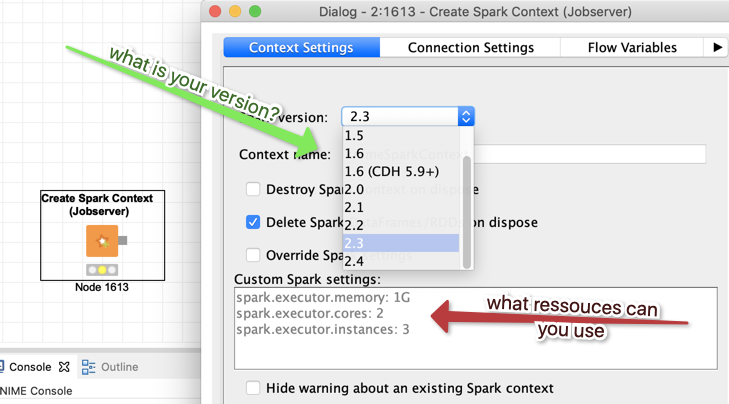
what is the version of Spark you are using? There are very dynamic developments so it might make a huge difference if you use 1.6 or 2.3
what is the power assigned to your user on the Spark Job server. You could configure that in the Create Spark Context node but ultimately the settings on the actual job server would limit your resources (you might have to talks to your admin about that)
If you could provide us with some insight we might get a better idea of what is going on.
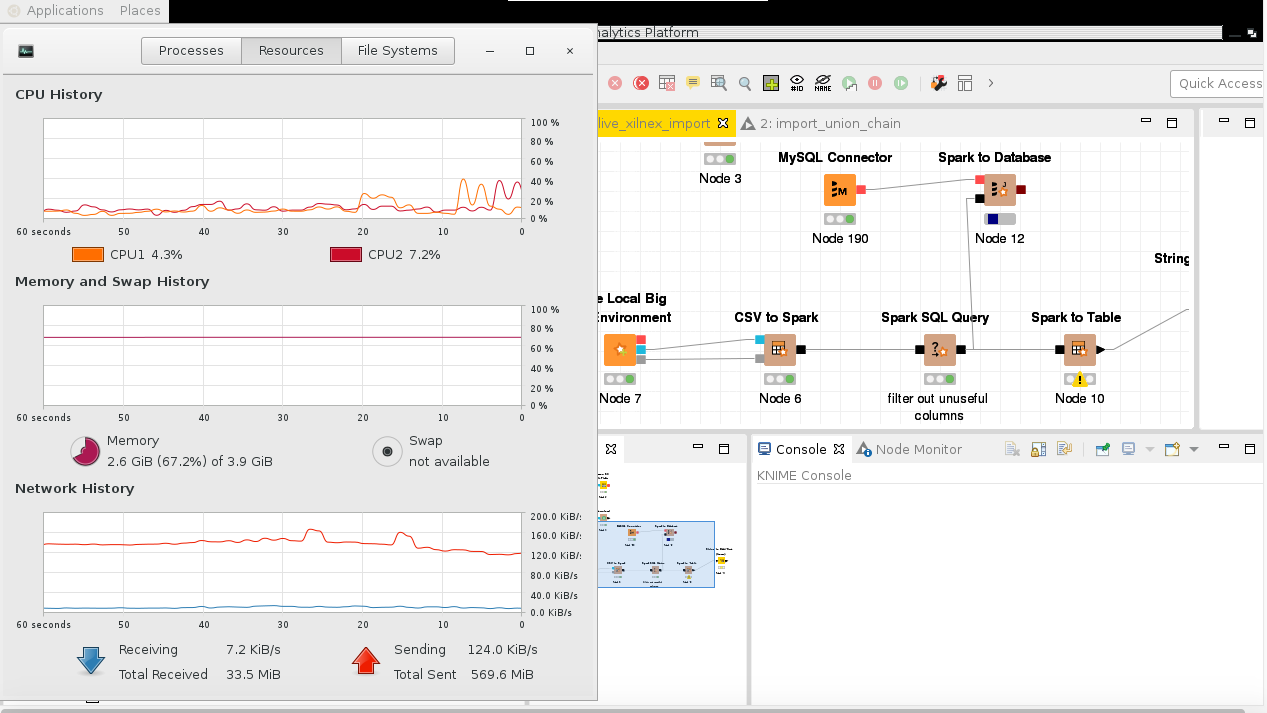
The main problem is that the big data local enviroment is set in an EC2 in europe. While the Mysql database is set in East Asia (Singapore). I think that there could be a latency problem, it is sending data slowly (124kb/s). Considering that I expect to receive GB of data and now we are at 570mb…
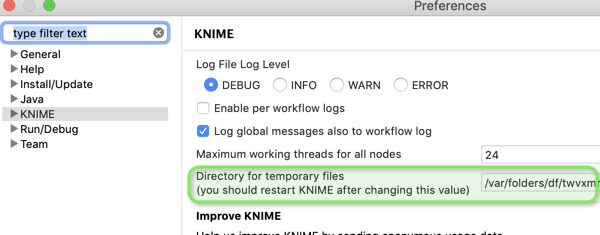
OK then how big is your CSV file and where is the MySQL DB located (on you machine)? Do you have SSD and where is the KNIME temp folder located (since that will be used).
I think the Local Big Data environment of KNIME is mostly there to test and develop Big Data workflows, I do not think you will get any actual performance benefits out of it since as I said Big Data might initially be slower than normal DBs.
You might try to limit your CSV to say 1.000 rows and see if the whole thing works at all. Then I would recommend just using the other features of KNIME to solve your task and use the Big Data environment for development and educational purposes.
BTW you can send tasks to the MySQL FB via KNIME Database nodes.
The size of the csv is around 20GB. The Mysql DB located is on amazon aws east asia (singapore). While the knime platform is executing the task from an amazon aws EC2 in europe. The machine has an ssd.
Hmm Spark tries to do things in memory which makes it faster on Big Data environments than basic Hive or something. I can not see any benefit in trying to bring 20 GB of data to the memory of a 4 GB local/AWS machine with 4 cores for KNIME and then try to send it via Internet to some MySQL on a distant computer.
Have you tried to load it up via other measures without big data? Is there a chance to send the CSV there packed and load it on the local machine?
Big Data environment might even slow you down here. But you could try to limit it to 1.000 lines and see if that works at all.
If you absolutely must send the data you might try something with streaming where you would only do some lines or a chunk at the same time, but I have no extensive experience with that. I would recommend setting up a method to load a small amount of data without Big Data environment and then take it from there - possibly with streaming.
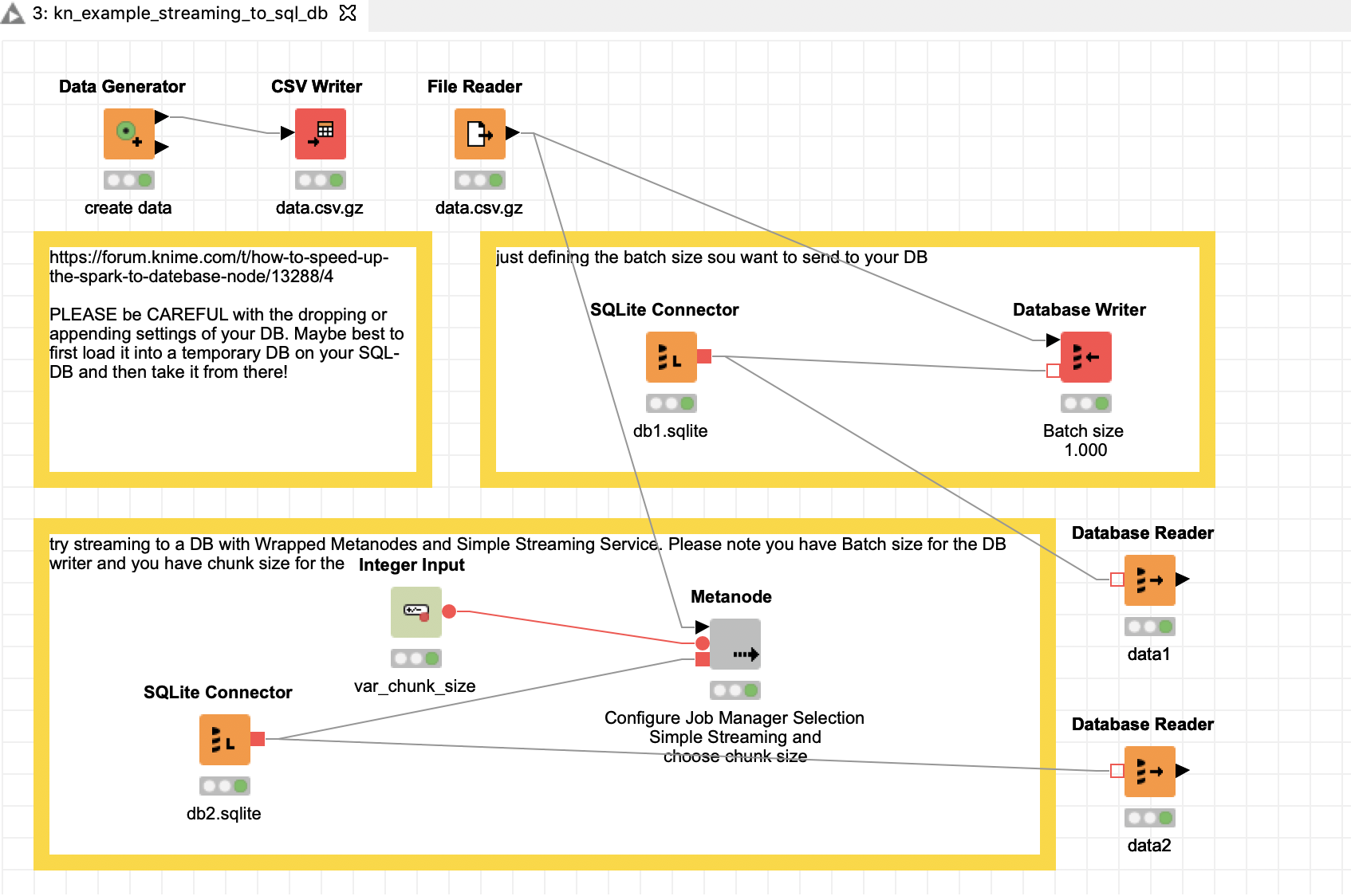
So here is a quick setup with 10.000 lines. Two options. One just to define a Batch size you want to upload at a single time - maybe try that one first.
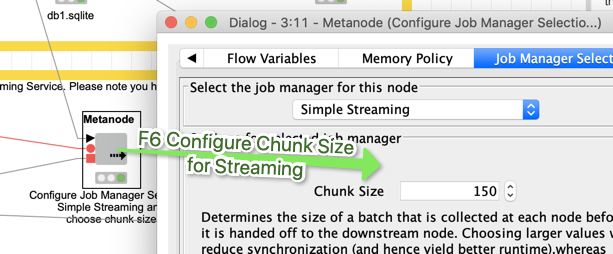
Second option would be to wrap it up into a streaming Metanode where you can define two parameters. Batch size like before, and Chunk size for the streaming. You might want to test that.
And please note you could set up the Database Writer either to append data to an existing DB or drop an existing one and create a new one. The implications obviously are severe and you might want to do extensive testing if your setting does want you want and not accidentally destroy data!
Also with the Database Writers I have seen occasionally that it is necessary to first tell SQL to drop a table if it exists although the writer should take care of that.
I have tested the Streaming node that it would not reset the data2 table at every run of the stream but you might still want to test that in real live an especially with your setting of different machines on different part of the world.
SQLite is a local stand in for you actual MySQL DB. The connection should work either way.
 )
)