Could you give us a little more context? Spark and Databases is influenced by several factors all of which might play a role:
- Spark does lazy execution. Question is how complicated are the tasks you do before storing the data in MySQL - if the Spark nodes in KNIME are green that only means the checks are completed - Spark would only start to work once you force it to actually bring back results (you might check the KNIME log for clues where your workflow actually stands)
- then the whole thing might be heavily influenced by the overall performance of you Big Data system (is it running on a cluster or do you use your own machine with the local KNIME big data environment?) - please note Big Data systems need some overhead in starting the various instances, so they initially might be even slower than regular DBs (they later make good on it in being able to -well- perform big data operations
 )
) - how is the connection between your Big Data cluster and your MySQL DB? Please keep in mind that whatever data you send there must go thru the network or the IO of the machine. That is while if you are dealing with really huge datasets you do not send it via network cables but use Big Data instead.
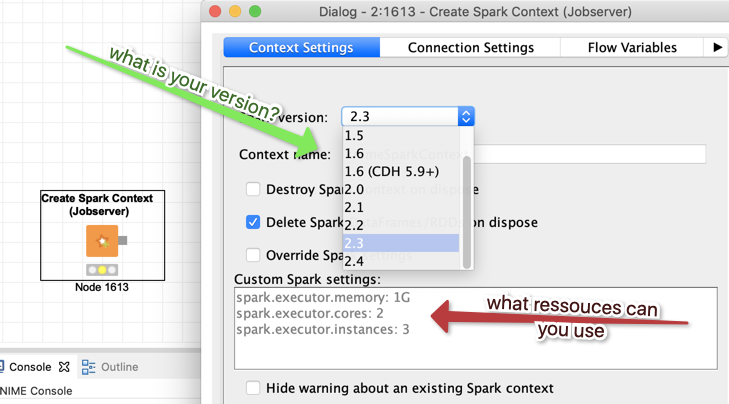
- what is the version of Spark you are using? There are very dynamic developments so it might make a huge difference if you use 1.6 or 2.3
- what is the power assigned to your user on the Spark Job server. You could configure that in the Create Spark Context node but ultimately the settings on the actual job server would limit your resources (you might have to talks to your admin about that)
If you could provide us with some insight we might get a better idea of what is going on.