How to split all columns at same time by some delimeter like “@”
I know cell split splits the cell by column name
But what to do when I want to apply same rule to all columns.
I tried loop column list and string manipulation but not sure how exactly to use them.
I tried loop column list and string manipulation but not sure how exactly to use them.
Result 1 has 10 col
substr($$CURRENTCOLUMN$$, lastIndexOfChar($$CURRENTCOLUMN$$ , ‘@’)+1 )
Result 2 has 10 col
substr($$CURRENTCOLUMN$$, 0, indexOfChars($$CURRENTCOLUMN$$ , “@”))
Here I am able to split the data but how to keep Result 1 and 2 columns side by side without manual column rearrange.
eg:
Col A | Col B | Col C | Col A_keep | ColB_keep| Col C keep | ColA rem | ColB rem | ColC rem
Col A |Col A_keep | ColA rem | Col B | ColB_keep | ColB rem | Col C | Col C keep |ColC rem
The Cell Splitter node is generally best in for splitting cells based on a delimiter, especially if there can be more than one occurrence of the delimiter within a cell (I didn’t know if this is the case here, although I’m guessing it isn’t based on what you have done so far).
Where you have obviously tried to make something work, but have specific questions about it, it I would recommend that you upload a small workflow showing your example as it is then easier to answer specific questions and suggest where you need to make changes.
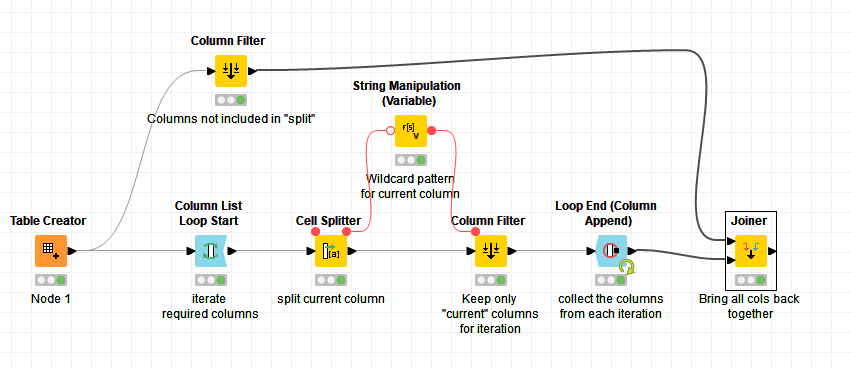
Attached is a workflow using cell splitter, with additional actions to retain only the columns involved, without additional “iteration” columns being retained.
I’m not sure if it does exactly what you want, but it does keep columns in the order they are processed (is that the order you want?). You could add in some column renaming inside the loop if needed. Feel free to ask questions about it, or say where you want it to do something else, or alternatively upload your own small demo workflow, and we can take a look.
Hi, yes I’m appending an asterisk onto the end of the column name, to provide a “wildcard” flow variable for use with the column filter, so if the Column name is ColumnA
the column filter will allow through all columns matching the pattern ColumnA*
during each iteration, allowing all columns through if the name begins with “ColumnA”
There are flaws to this approach, and would need some refinement if you had columns whose names were subsets of each other, but it hopefully gives some ideas
I’m sorry to say I couldn’t make this piece of code compile… a quick tip though: when uploading code fragments, it’s best to highlight the text of the snippet and then press the “Pre-formatted text” button
as this then stops the forum software changing anything.
e.g.
instead of it posting as
indexOfChars($$CURRENTCOLUMN$$ , “@”)
it would post as:
indexOfChars($$CURRENTCOLUMN$$ , "@")
which has left the double-quotes characters alone so that they can be copy-pasted etc.
I’m glad you’ve managed to achieve what you wanted, though. I feel that there is probably a way to achieve what you wanted without requiring code like this, but at the moment, I still don’t fully understand your actual requirement. Maybe if I’d managed to compile your code my understanding of what you are trying to achieve would be clearer to me, but as you say you’ve got it working, I’ll assume for now that you aren’t requiring any additional assistance.
Feel free to upload your now-working workflow though if you do want any further suggestions.