Does anyone know how to partition the dataset into 3 sets: training, validation and testing in Knime?.
In many of the Knime tutorials, I see that they partition the dataset into training and testing, but I still cannot figure how to split it into 3.
I tried dividing the data into 3 sets by using two partitioning nodes in succession but it didn’t work.
My question is how do you split the data into training, testing and validation before you feed it into the neural network. Can you provide me an example.
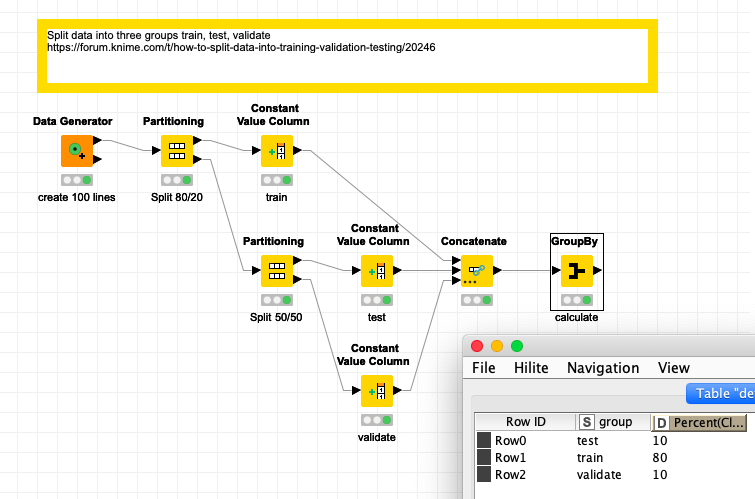
As described in the picture, you divide your dataset into three sets and label them accordingly in several steps.
Now, you may want to use one dataset only for train+test, then attach new, fresh data as validation set. You would have two sources which would need to go through the same processing and differ by only applying a model (cooked algorithm) to the last two sets - test and validation.
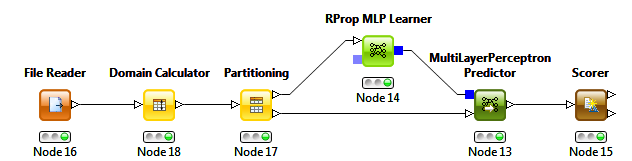
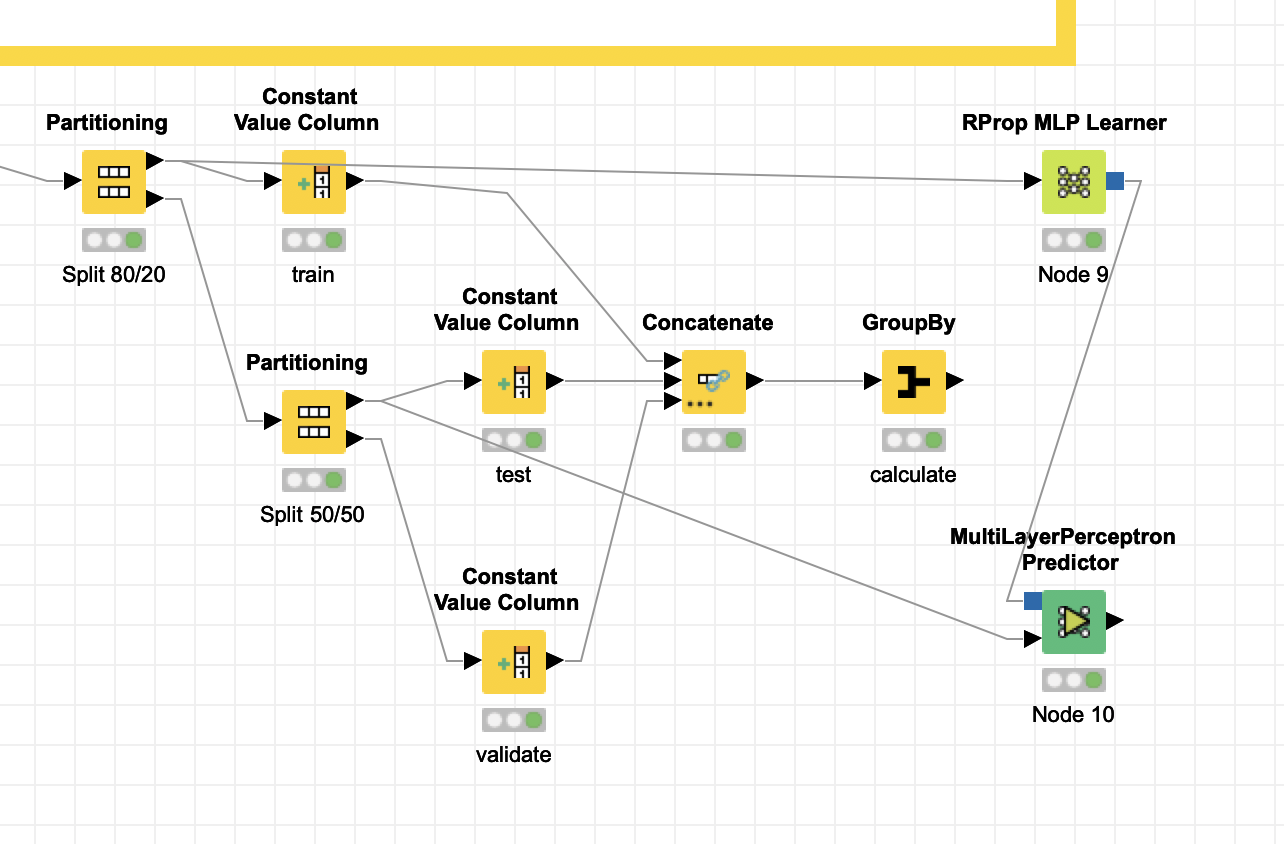
Thanks for your explanation. I am clear now on how the data is partitioned and labeled. My question is how would you connect each of the partitioning nodes to the neural network learner and the predictor nodes. If you look at the example below, the data is first partitioned into training and test set, where the training set is fed into the learner node and the test set into the predictor. How can I accommodate the workflow from this forum into the one below (see attached). Can you give me a hint of how to connect the nodes. Thanks.