KNIME Forum
How to split data into training/validation/testing
KNIME Analytics Platform
mlauber71
December 30, 2019, 11:10am
2
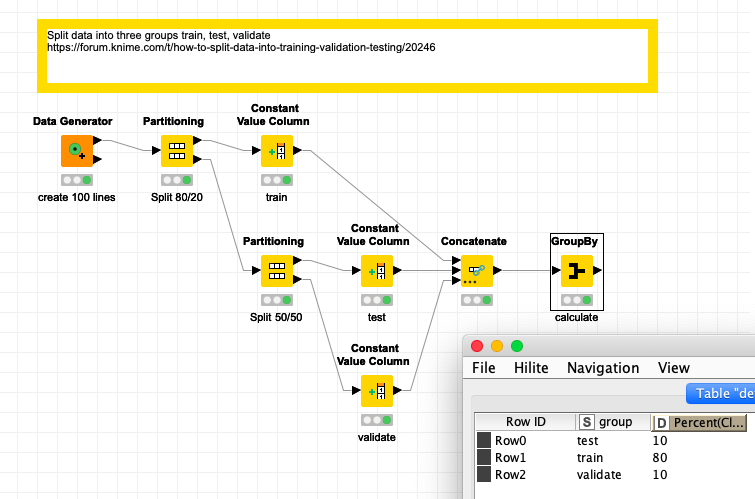
This should be quite easy. Please check out this example
image
755×499 53 KB
4 Likes
show post in topic