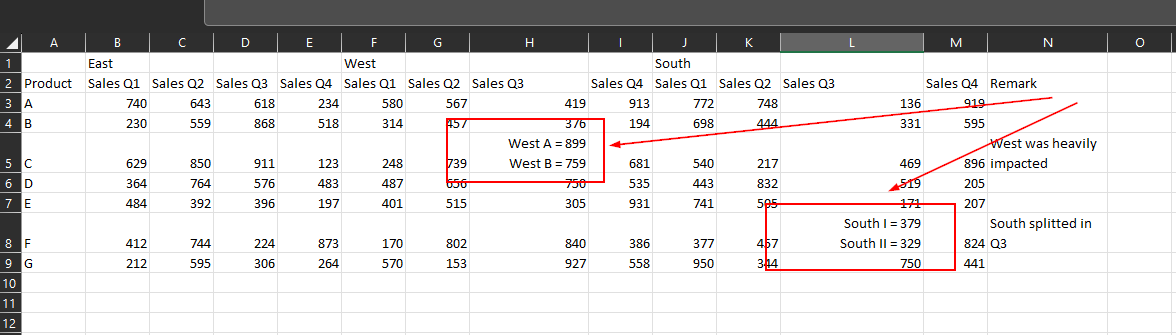
I have a table with some (fake) sales data. Within a few cells, I have some additional text info, e. g. splitting a sales region into 2 subregions (see screenshot)
As I later on want to push these numbers to PowerBI I need to make sure, they are definitely handled as numbers. So I somehow need to split the cells without loosing the information.
For example, I want to have in cell H5 (Sales Q3 for West) the number 899 and the string “West A” maybe added to the Remark column N after the existing comment.
I have provided an example workflow here (where I already have cleaned up the column headers):
I feel like I should know how to do this but somehow can’t make progress (maybe to many xmas cookies )
Hello @kowisoft ,
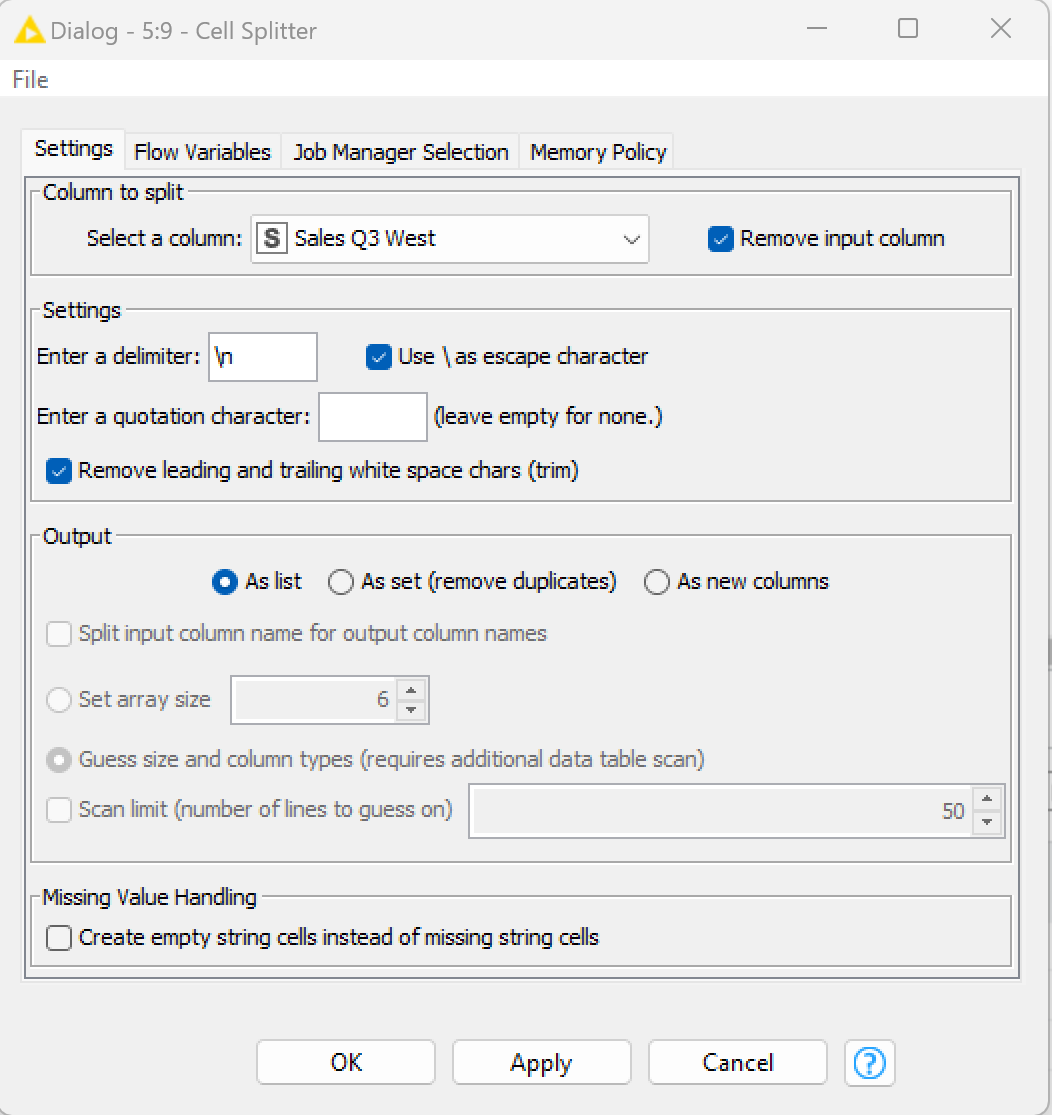
I used a Cell Splitter node with a delimiter “\n” to split that cell and selected “List” as the output column. Once I got the list, I used the Ungroup node, and finally, we can use a rule engine to add it to the Remark column.
Hi,
Additionally, you could add a Regex Split node to get the parts before and after the equal sign so that you can populate the Sales Q3 West column with only the number. And of course you’d need to do this for every column, so a Column List Loop Start node would be necessary, together with a Loop End (Column Append).
Kind regards,
Alexander
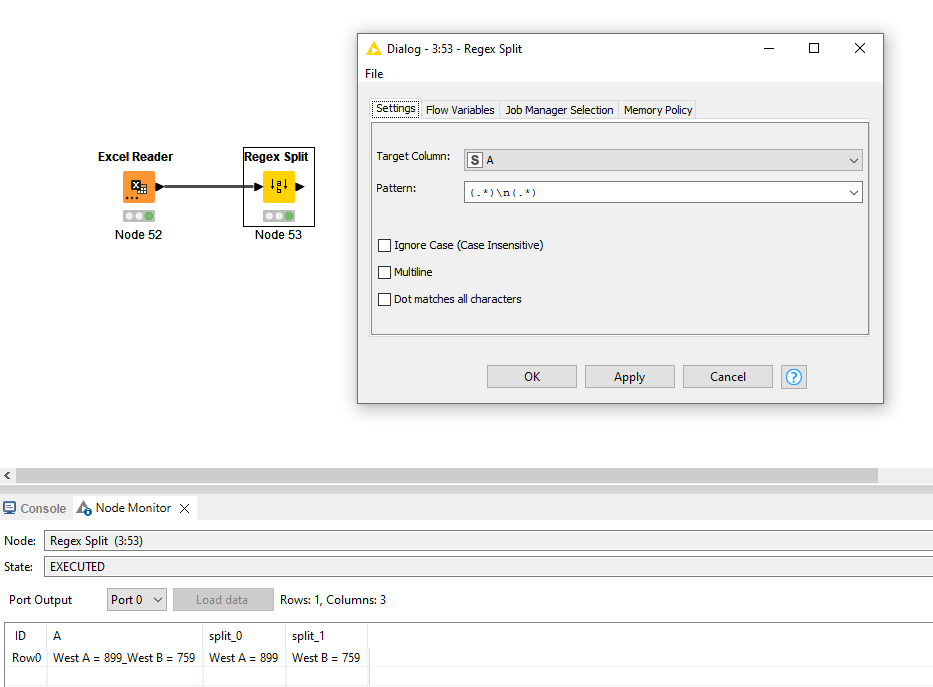
RegexSplit is a difficult node to understand. You have to 1) explicitly define the groups that should be made with the split (.*)\n(.*) and 2) it does not require escaping special chars like other nodes do.
I think I misread that part and said rule engine. But, if we are sure that “=” will be there then we can add one more cell splitter and split it on “=”. In case the data changes, regex is by far the best option.
Hey @kowisoft,
I agree it is sometimes not intuitive to transfer Regex from regex101 to KNIME. However, I think the Regex Split should take the regex as-is from regex101. Only in the String Manipulation node it is a bit different, because there the Regex is treated as a Java String, requiring escaping the backslashes two times.
Kind regards,
Alexander
This seems to be more challenging than I thought but who doesn’t love a good challenge, right?
So I have come this far with the help of @AlexanderFillbrunn and @ArjenEX but if I want to make this dynamic, I am not sure how to set column names in the Rule Engine Node to “dynamically” select the column currently used in the loop.
The Rule Engine per my understanding checks against the value / content stored in the flow variable and not against the column that the flow variable “represents”, right?
How would you do something like this?
Here’s my workflow (adjusted based on prior posts):
Hi,
This is indeed a bit more complex than it needs to be, but the only way to do that is to dynamically create the rule engine expression using a String Manipulation node, then control the whole expression via flow variable. Alternatively, you could use the Column Expression node. Here you can do column(flowVariable(…)).
Kind regards,
Alexander
Hm… this somehow doesn’t work and I don’t know why.
I now replaced all direct references in the Column Expressions with indirect ones using the “column()” function in the Column Expressions Node.
But for whatever reason it now creates a lot of new columns although I explicitly tell the Column Expressions Node to replace and drive the column to be replace via the flow variables tab.
Hi,
I think that is because each iteration creates its own Remark etc. column. Now you need to merge them all with a Column Aggregator node. Select the columns to be merged into one and then use e.g. the Concatenate aggregation to concatenate all the remarks.
I cannot adjust it because it’s inside a loop and a case switch so I need to execute upstream nodes to have some input.
But once I am in the loop, I can also not make adjustments, because the loop is running…
I also do not understand why it creates extra columns. In both column expressions nodes I explicitly state, that I want to replace the columns. Why do the nodes ignore this and create new columns instead?
It seems the Loop End (Column Append) Node is causing this problem. But if I use a standard Loop End Node, now all rows are repeated.
Looking at how convoluted the workflow already is, I guess I have to start over, because that is not something, I can or want to maintain over the next few months.
I split the table so that only the Sales columns go into the loop. The rest I split off and add later again.
I add an ID column to keep track of which row something belongs to, because in-between I use Ungroup, which may generate multiple rows from one row.
Then I loop through the sales columns and split each value by the newline character.
For each line in a cell, I create a new row in the table. The ID of the new rows will be the one from the original row so I can keep track where they come from.
With Column Rename (Regex) I make sure the new column does not have the “weird” name coming from the Cell Splitter and Ungroup combo, but the original column name.
I use the Regex Splitter to get the part before and after the equal sign. To handle cases without equal sign, I use an optional non-capturing group (?:(.*) = )?.
I only keep the split columns and rename them to “Remark” and the other one to the original sales column name.
I use a Duplicate Row Filter to filter out the second lines generated from the split cells. You can handle this differently, but important is that in the end the number of rows is the same for each iteration. If this is not the case, you can also deal with that using a normal Loop End and a subsequent Pivot. Let me know if you are interested in that.
In the end we collect the columns, add the ones we previously split off, and concatenate all the remarks.
Let me know if you have any questions.
Kind regards,
Alexander
highly appreciate your detailed feedback. And this also looks like a major improvement form the “fuzzy” workflow I created (reminds me of Rod and Todd Flanders,
just that my eyes are bleeding and not my ears … but I digress )
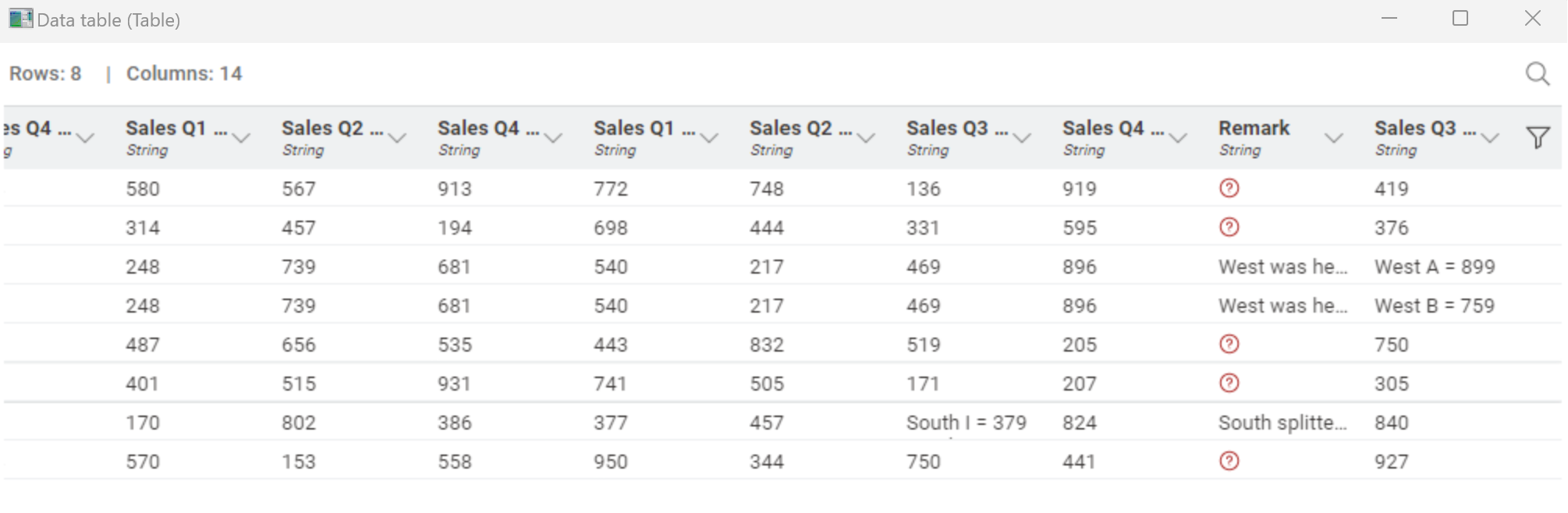
One thing I might be missing in your workflow @AlexanderFillbrunn is the second value…
E. g. in Sales Q3 West, we have 899 for West A and 759 for West B. This second line (West B) seems to have disappeared.
Maybe I phrased my question also the wrong way: Basically I want to keep both:
the stuff before the ‘=’ goes to the remark
the value should be added as a new line whereas all other values stay the same (so e. g. while West B ist 759 for Sales Q3 West, the value for Sales Q3 East stays the same at 911 for Product C)
Hi,
I hinted at that a little bit in my description. What you have to do is use Unpivot inside the loop and then use a normal Loop End so you can produce multiple lines from a single line. Then you can Pivot again after the loop to restore the table. The problem is that for columns where there is no multi-line value, of course only one row will be produced, as this particular iteration does not know that in some other column in the same row there are multiple lines. Because of that, there is now an extra construct with a Group Loop. It goes through each group of rows that were produced from one original row and then imputes missing values. We also now need a Joiner in the end instead of a simple Column Appender because the number of rows coming in is not the number coming out. Please find the modified workflow attached.
Kind regards,
Alexander
So if I understand it right, the first loop iterates through the columns to split them up whereever this is necessary (e. g. we have a multiline entry)
The second loop then “cleans up” all the missing values that were basically created through the first loop by filling them with “previous” values.