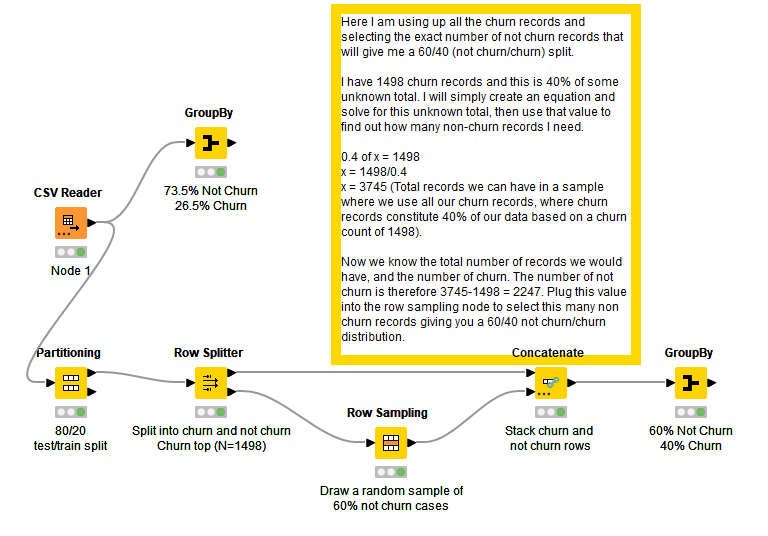
I’m trying to split/separate my dataset/table based in some criteria in order to have, as example, the date is 80% users “A” and 20% users “B”, I need to change it to 60% percentage of users “A” and 40% percentage of users “B”. In SPSS there is a node called “Balance” that allow us to do it, but I didn’t find a node in Knime… Do you guys know if there is a way to do it in Knime?
I don’t believe there is a single node that does the balancing like SPSS Modeler, but you can achieve a similar effect by using a combination of nodes and some light algebra.
Thanks for helping me! This one is pretty close to what I need. In my case, I have several segments (1, 2, 3 etc) and I need to apply this partition by segment, like:
Segment 1: From 100%, select randomly 70%
Segment 2: From 100%, select randomly 30%
Maybe I’ll have to split my dataset and then apply partitioning to each one separately! Thanks!
Hello @fivescar
There’s not a single node that can hold your custom segments configuration.
As commented before Partitioning is your node. You can start with a two columns table: $segment$ (string) and $fraction$ (double), and connect this table to a ‘Table Row to Variable Loop Start’ node.
By using this two variables in every loop iteration; you will control the nodes in your workflow:
$${Ssegment}$$ controlling ‘Row Filter’ your dataset segment.
@fivescar
If I understand correctly you could also try a group loop to iterate your segments and create the split for each segment loop and combine them at the end
(And not exactly what you described but maybe you could check out a stratified sampling in partion by segment. This would give you the same distribution of segments in your train and test split in case this is the direction you are going)
br