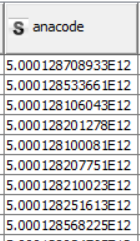
I have a csv file containing a 20 digit Customer Id (e.g. 50000174058809263569) in one column and other customer related information in the remaining colums. After processing the data and doing the necessary calculations, I write the output into a CSV file. But when I write the output, the Customer Id gets converted into scientific notation (e.g. 5.0000174058809264E19). This is incorrect because the customer Id is just an identification number and having it in scienfitic notation makes no sense.
I tried to used the NUMBER TO STRINGnode before writing the final output file but it just puts the quotation marks around the customer id which continues to get written in scientific notation (e.g. "5.0000174058809264E19")
I think when the number of digits exceeds a certain fixed threshold, KNIME automatically converts all numbers to scientific notation. Is there a way to prevent his? I want the output file to have the customer Id as a regular number without the scientific notation. Can anyone please help me?
I'm surprised your Id is not rounded automatically. In a quick experiment, my Knime rounded your example Id to 50000174058809260000. And even if it seems to work, there's always the danger that it will not always work. So maybe use Strings from the start?
For completeness sake, and in case it does work, here's a solution for a Java Snippet:
This option doesn't seem to be working either :(. Come on KNIME, having built such a great product, how can you let this major issue slip through. There should be a simple way to let the user choose if scientific notation is to be used or not.
In which way does it not work? Wrong results, error messages...?
Maybe I should add that I used the regular Java Snippet, not the simple one. In the simple one, the equivalent would be
return String.format("%.0f", $Big Number$);
where $Big Number$ is the reference to your ID column.
But again, your IDs might be rounded right at their creation. The underlying reason is that Knime uses the java primitives, which have physical size restrictions. The double type (which you are probably using, as the others are too small) just cuts off the least significant digits without telling you about it. There would be ways for the Knime developers to get around that behaviour, and to allow arbitrarily sized numbers, but it wouldn't be worth it in 95% of the cases. And in another 4% of the cases, using Strings instead might help. (As in your case. I mean you probably aren't doing computations with your IDs, right? Why would you use numbers, then?)
I agree that the ability to choose formating would be a nice feature. There are a lot of positions where that might be a good addition, but an extension of the Numbers To Strings node seems to be the most important one. It's probably on the radar somewhere, but with a low priority or something..
Nice to meet you. Would it be possible to learn a bit more about why you need Big Number support? This is not something that we have run in to much (ever?) before. If it really is just a matter of keeping track of a (very large) ID, I think it is reasonable to read the data in a String cell to start, no?
Here's what I do for large IDs... read in the number as the RowID data type, then use the RowID node to duplicate the column and rename it (probably to CustomerID).
The initial concern is not really Large Numbers handling but rather turning off the scientific notation when writing a .csv file.
I have the exact same case (ID going through a workflow).
@Aaron : I see your point, it is reasonable but not so practical (the types come from Database, lots of nodes to modify etc... and at some point in the workflow you may need to have it as Double for some reasons.
The root problem is that the number is so large it cannot be represented by an integer (or long) and is therefore read as a floating point number. During this conversion parts of the original number are lost, due to limited precision in floating point numbers (the least significant digits are cut). It doesn't matter what the CSV writer does, in any case it would write a wrong value. The proper solution is to read the ID as a string and not a number in the first place.
If you don't want scientific notation when deliberately writing a double value, use the Number to String node.
I am using Knime version 3.5, and for long doubles scientific notation is being output by the Number to String node, as well as the string values from the Column Rename node (when choosing string as the value type for the renamed column). Prior to the conversion the output renderers for previous nodes do not show the value using scientific notation. Is there a default node which will not insert the scientific notation, or is the only option a java node? Thanks!
Thanks!
but I have a follow-up question. Why is this the default behaviour? I don’t remember any case where I wanted my strings to be in scientific format.
(For the records: There will be a new option in the “CSV Writer” in KNIME 3.8 that allows you to turn off scientific notation – this will also be the default for new instances of the CSV Writer node. Existing nodes will remain to write ‘1.2E-12’ in order to guarantee backward compatibility.)