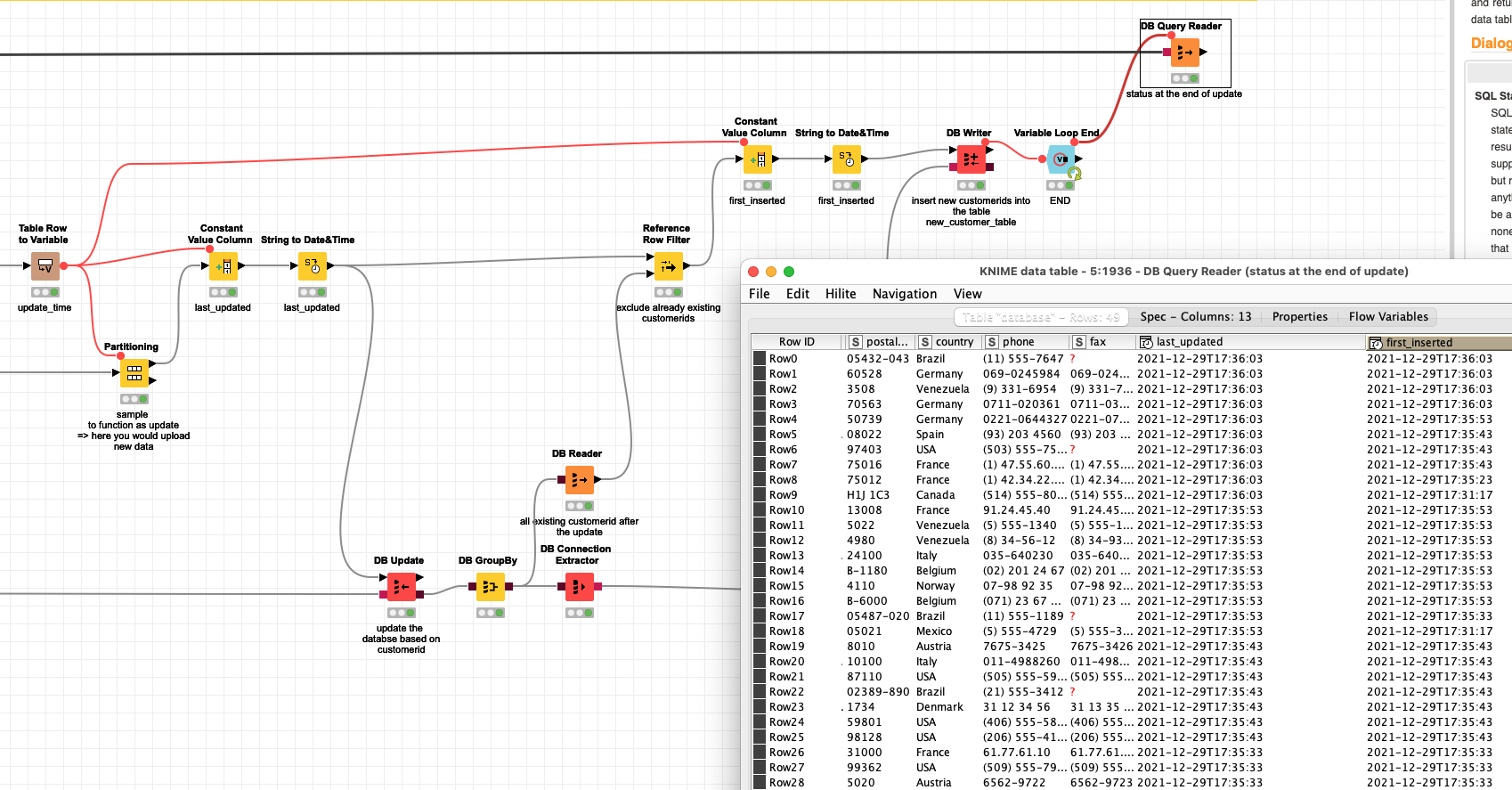
@RIchardC I put together a (hopefully) complete example using H2 and the Northwind database with customerid.
Here we first create a database with a customerid as a primary key (randomly selected from the central DB). Then every 10 seconds another random batch gets drawn. Existing customerid will be updated. Then the workflow determines which customerid are new and would insert them. If a row is inserted initially a timestamp first_inserted will be stored. Then with every update another timestamp last_updated markt the time and update has been performed.
Maybe you can take that example and work with that.