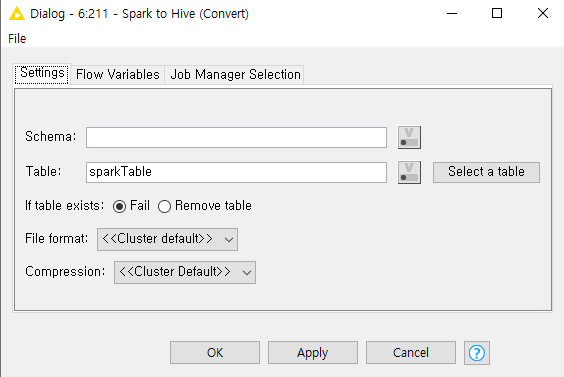
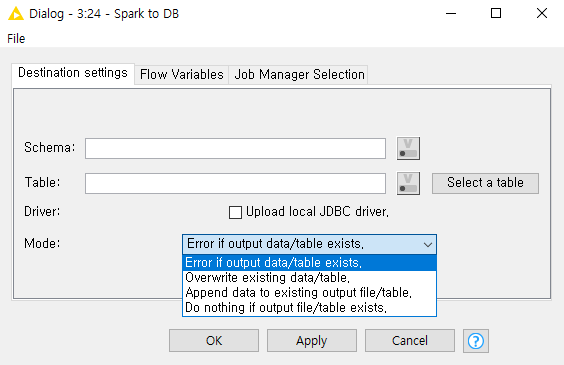
I was wondering if I can update spark data in hive table.
I can’t use spark to table node because a data size is too large.
So I want to update spark data directly in hive table, but I don’t know how.
Please let me know if there is a way to update directly.
With the help of KNIME nodes you can execute various Spark tasks (KNIME Extension for Apache Spark | KNIME) including SparkSQL and later store the result on the Big Data system as a hive file. What format that has is another debate, external table, ORC … and (you might have guessed it … depends on the version of hive (and Cloudera or whatever system you are using) (Load and Write Data into Hive Corporate DB - #4 by mlauber71):
So your task might involve some planning and you might want to decide where you want the task to be executed. This very much will depend on the performance you can allocate on the cluster and the nature of your task. Depending on your settings Hive or Spark (Create Spark Context (Livy) – KNIME Hub) might be configured to allocate resources dynamically in oder to fulfill the task (if the admin would let you).
If you have a Hive cluster, you should use ACID tables that support insert/update/append. Spark does not support these types of tables and requires a warehouse connector to access tables managed by Hive. Cloudera already includes them, and the Spark to Hive Node should you them by default. More information can be found in the Cloudera documentation.
If you use a Databricks cluster, delta tables should support these operations. See Databricks documentation.
If you use the Create Local Big Data Environment Node, don’t use this in production with large data. This is a testing node and the DB output port does not connect to any real Hive cluster, it’s only the Spark Thrift server that emulates this. You might use the DB Loader or, without any DB nodes, use the Spark_to_Parquet node instead that supports appending.