I’m pulling data from an API which limits the number of rows I can call each month. To solve for this, I’d like to design a few flows in KNIME to accomplish the following:
Original data pull from API which writes to a local table (Done)
Subsequent data pull from API which only calls rows that have been updated in the last 30 days. Some of these will be completely new rows, and some will be updated rows (Done)
Merge the results from steps 1 and 2 so that any rows in the second pull replace rows from the original pull (This is the step I’m having trouble with).
I have a unique ID in my data, so I’m able to match the two datasets using a full outer join with the joiner tool, but I’m not sure how to consolidate this back into one clean dataset. Right now I have two sets of columns for all my rows.
Also, is there a way for me to append a date field when a row is pulled from the API, or when a node is run? Ideally, I’d like it display it prominently so it’s obvious how long it’s been since the data has been refreshed.
I’m uploading a sample flow with most of the columns removed. Table Join Example.knwf (245.1 KB)
Hi,
can you remove the old rows from your dataset using a Reference Row Filter and then merge the result with the new data pulled from the API using the Concatenate node?
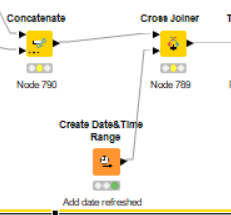
Regarding the date field: You can use a Create Date&Time Range node with execution time as start time and the number of rows set to 1, then add that single row to the dataset using a Cross Joiner.
Kind regards
Alexander
also you could concatenate original and recent data and then follow it with Duplicate Row Filter based on unique ID you have and have option to keep the last row.
can you remove the old rows from your dataset using a Reference Row Filter and then merge the result with the new data pulled from the API using the Concatenate node?
Regarding the date field: You can use a Create Date&Time Range node with execution time as start time and the number of rows set to 1, then add that single row to the dataset using a Cross Joiner.
I added the Create Date&Time Range node and added it to the dataset using Cross Joiner. However, This is a separate node on my workflow. I guess it’s possible that a person could reset and refresh only the nodes they want to get the new dataset, but the Create Date&Time Range won’t be reset unless they reset that node as well. Is there a way I can make this node somehow dependent on the execution of another node?
I’m attaching a screenshot of this part of my flow for reference, where upstream nodes were reset, but the create Date&Time Range node was not.
also you could concatenate original and recent data and then follow it with Duplicate Row Filter based on unique ID you have and have option to keep the last row.
I had initially tried to do it this way. I just hadn’t realized I needed to add a Duplicate Row Filter to get rid of the unwanted rows. I kept thinking this was an option in the concatenate node I didn’t know how to activate.
Hi,
You can right click and select “Show Flow Variable Ports” on the Concatenate and Create Date&time Range nodes. Then you can create a flow var connection between the two nodes to make one dependent from the other. The Show Flow Variables step is not really necessary, because you can even drag the connection without the ports being visible, but it is easier to understand what you are doing that way.
Kind regards
Alexander