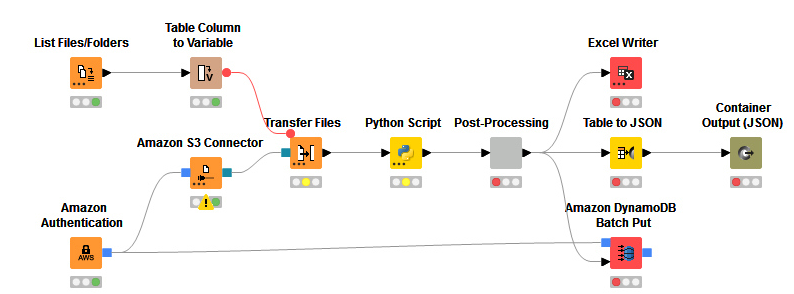
So far, this workflow uploads the files to S3 and then processes them, but my files are already in S3, I can’t find a way to use Amazon textract without downloading the pdf files to my pc.
Hi @Cristian1235,
Welcome to the KNIME Forum!
I don’t believe there’s a way to do this without downloading the pdf files in some way. I believe in the example workflow you provided the data would still need to be downloaded locally for Python to work with.
A possible workaround could be some sort of loop where you only download and process a few pdfs at a time, then delete them to save space (I’m assuming disk space may be a concern here). I’d also recommend taking a look at the PDF parser and Tika parser nodes if you’re looking for alternative solutions to Amazon textract.
Cheers,
Dash
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.