Hi ArvenS,
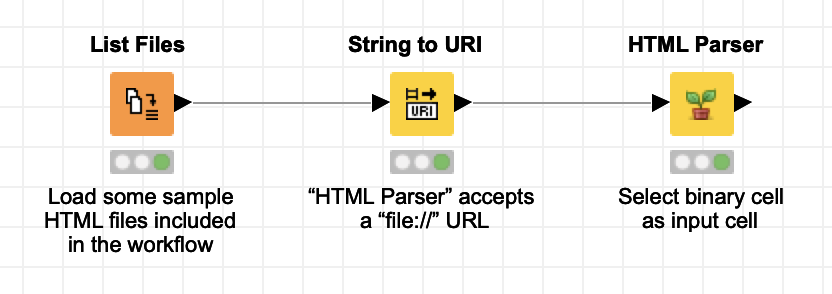
you can parse local data by inputting it as “binary” cell into the HTML Parser. The HTTP Retriever is not necessary in this case:
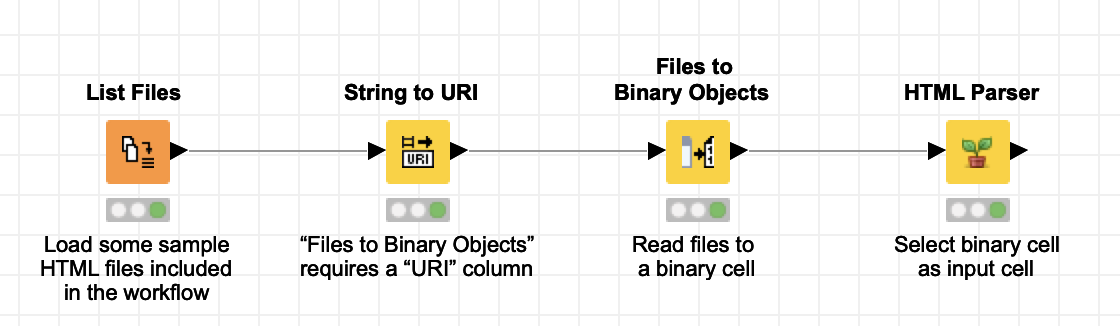
You can find the workflow on my NodePit Space:
Does this help?
Philipp
[edit] Sorry, still early in the UK. Actually, the Files to Binary Objects is not even necessary here – you can simply input the file:// URL which is generated from the String to URI node. One node less