I would like to filter numbers or words with the Rule Engine Node. Everything works fine as soon as I don’t use regular expressions. Then the Rule Engine Node no longer filters out.
But it can’t be because of the regular expressions, as they generate unique hits in https://www.regextester.com/ and do exactly what they are supposed to do, such as (.)\1{9} → returns all identical characters from 9 repetitions onwards (0){9} → returns all 0 from 9 repetitions onwards ^[0]*$ → returns everything that has 0 throughout
OR
\bFOO → returns all words that are FOO
(FOO) → returns all words that contain FOO
I also think that I am using the correct syntax:
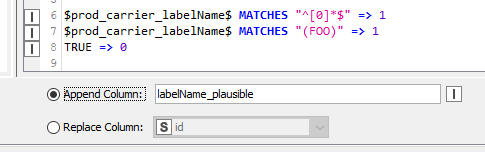
$column-Name$ MATCHES "^[0]*$" => 1
$column-Name$ MATCHES “(FOO)” => 1 // if true, then prints a 1
But at the end there is a 0 in the column to be appended. Everything I map with the syntax $column_name$ = “FOO” => 1 works perfectly. Only the regular expressions do not work. But I need them, because there are often other words after FOO.
What is going wrong here? Why are my regular expressions not working in the Rule Engine Node?
Hey @yogesh_nawale,
thanks for your efforts to help me. But unfortunately I have some bad news: It doesn’t help. Because the regular expressions work. It must be something else, like the behavior of the rule engine node.
Hello @Thoralf
MATCHES() in rule based nodes, woks for the matching of the ‘whole’ sentence. Then, besides that the capturing groups are redundant here; your regex "(foo)" expression, it’s only matching for a fragment of the sentence. This is why it only matches for sentences where ‘foo’ is the whole sentence.
The right matching for any sentence containing “foo” at any part of the text would be:
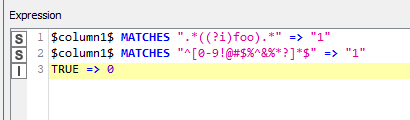
$text$ MATCHES ".*foo.*" => 1
Besides that, as @yogesh_nawale pointed, you can add operators like the one to ignore case "(?i).*foo.*"
Hi @gonhaddock ,
Your answer makes sense to me and your regex works. Thank you! The ignore case from @yogesh_nawale is also a great thing. I used it straight away.
But I still have one problem. What about the regex of ^[0]*$ or (.)\1{9}? I would have to filter out characters that are used repeatedly as placeholders. For example 000000 or 555555555555 or ------------
How does this work in rule based nodes?
Hello @Thoralf
You are using validations displayed in the website you mentioned. These codes match only for part of the sentences, but they do not return a match for the whole sentence; moreover square brackets stands for optional, then they are not doing a real discrimination.
Let’s see, in the same way than before; if you try to identify sentences containing a “0” character (literal)…
$text$ MATCHES ".*0.*" => 1
would be enough. On the top of that you can add quantifiers: ".*0+.*"- (one or more of a “0”), ".*0{3}.*" (exact three of a “0”), ".*0{3,}.*" (three or more of a “0”), … as in your text example: ".*0{6}.*" , ".*5{12}.*" , ".*-{12}.*"
Then, what you are trying to match is literal, so square brackets are just incorrect, and capturing groups (normal brackets) are redundant.
Same thing for the dot character:
$text$ MATCHES ".*\.1{9}.*" => 1
Here the back slash denotes that the “.” is a character, as dot by itself means ‘any single character’. Then you are searching for sentences that contains 'a dot followed by nine “1” ’ at any position in text.
BR
P.S. In the case of any digit [0-9]+, you can replace with \d+ (standing for “digits”)