Hi,
I wanna use word2vec to calculate the similarities between documents. The following is my operation step. I only calculate the similarities between words. Which nodes can be used for calculating the similarities between documents.
Anyone knows?
Thank you all.

See here
1 Like
Hi izaychik63,
Thank you for your suggestion and my research is similar to this topic. However, my aim is to use Word2vec or TF-IDF or doc2vec to caculate the similarities between all documents and i hope to get a matrix.
If you have any further idea i would appreacite it.
Thanks a lot.
Hi @izaychik63
Thanks for this very nice example of how to compare documents by similarity.
In @izaychik63’s example he has added a -Row Filter- node to compare just 1 document to the rest of all others. If your need is to compare All-to-All, then you would just need to remove this -Row Filter- from the workflow:
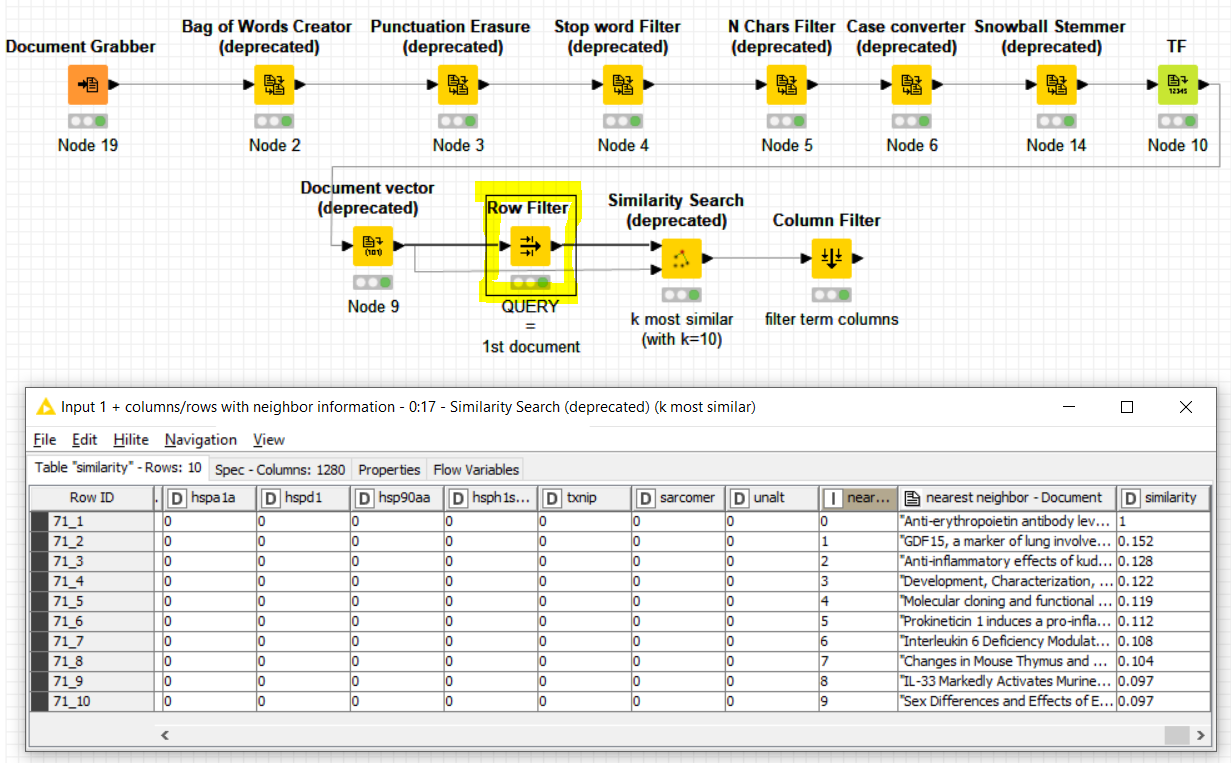
You should get in this case all the values of your Distance Matrix, even if they are not organized as a Matrix but rather as a Table with all the possible distance pairs.
Just be aware too that if you need to have all the pairs of comparisons, the “Neighbour count” parameter in the -Similarity Search- node should be higher than N^2, where N is the total number of documents you have. If you set this parameter huge enough as in the snapshot below, you should not need to care about adapting it to every different case:

Hope this helps.
Best
Ael
1 Like
You can look on other example
and node from Palladian
2 Likes
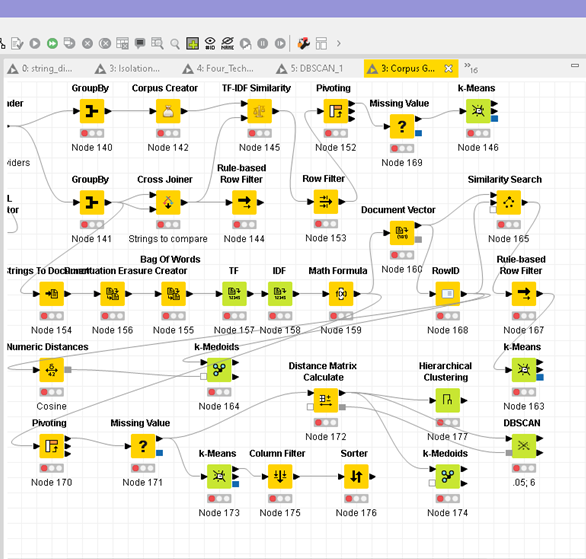
Hi izaychik63,
Thank you very much. These give me a lot of help. I will try these operations.
Hi Ael,
Thank you for your help.
Best Regards
Jean
1 Like
Hello @wangjingjing
We have developed the Redfield NLP nodes that can help you solve your problem. There are 2 ways to do that:
- You can try to use Spacy nodes, there is a special Spacy Vectorizer node that can convert the documents to vectors. This algorithms can run on CPU and do not have special requirements. I have described similar case here: Topic Modeling of the Breaking Bad Series with the Redfield NLP Nodes
- You can use BERT Embedder node, that will extract the embeddings from BERT model of your choice. However this approach requires CUDA-compatible GPU, but it will most likely give you the best results. I have described this case here: Sarcasm Detected with Machine Learning - Redfield Blog
Then you can use the approaches that were suggested here, e.g. using Distance Matrix Calculate and Similarity Search nodes.
Best regards,
Artem.
2 Likes
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.