Hey Knime users! I am pretty new to Knime analytics platform and have completed the self-paced basics course. However, I wanted a challenge and tried to tackle this task I found on Kaggle HR Analytics: Job Change of Data Scientists | Kaggle
It feels like i’m going in circles with this task, and now I’m not even sure how to process the data in order to get a good prediction. All the submissions presented in Kaggle are in Python, which I don’t know. If any of you have done a similar workflow, have some tips or trix and would be willing to share I’d be extremely thankful.
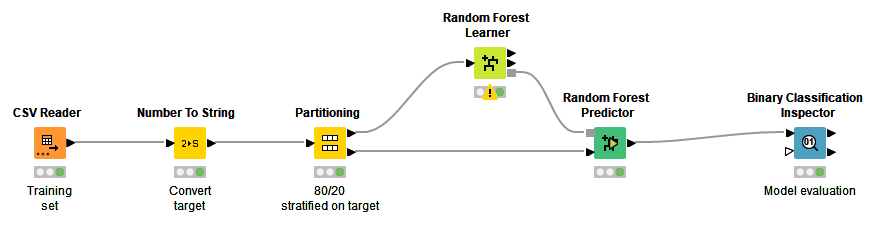
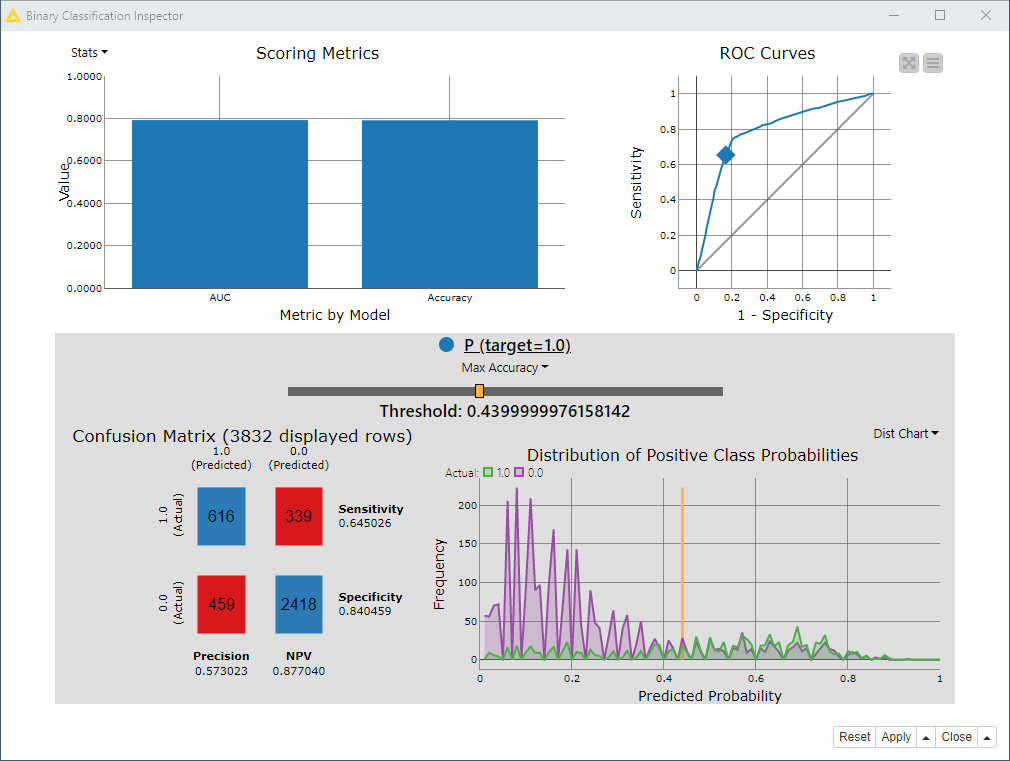
Another user recently asked about this same Kaggle challenge, so maybe you are both exploring this for a class assignment? Anyway, here’s a quick and dirty example of how you might start to approach it:
In case this is for an assignment, I leave the node configuration for you to explore. Note that I have made no attempt here to correct for the imbalance of the target class, or correct for high cardinality, or imputed the data in any way as suggested by the Kaggle page - so there is plenty that could be done here to improve performance. But maybe this gives you a starting point, and ideas of what might be possible.
I actually managed to solve this a couple of days ago. I used the SMOTE node to handle the imbalanced data, the domain calculator node to handle the high cardinality and concatenated the two datasets. I did however use the Decision Tree instead of the Random Forest, since the Decision Tree gave me a AUC score of approx 0.87. I will check out how the Random Forest to see the differences. Thanks again!