Hi everyone,
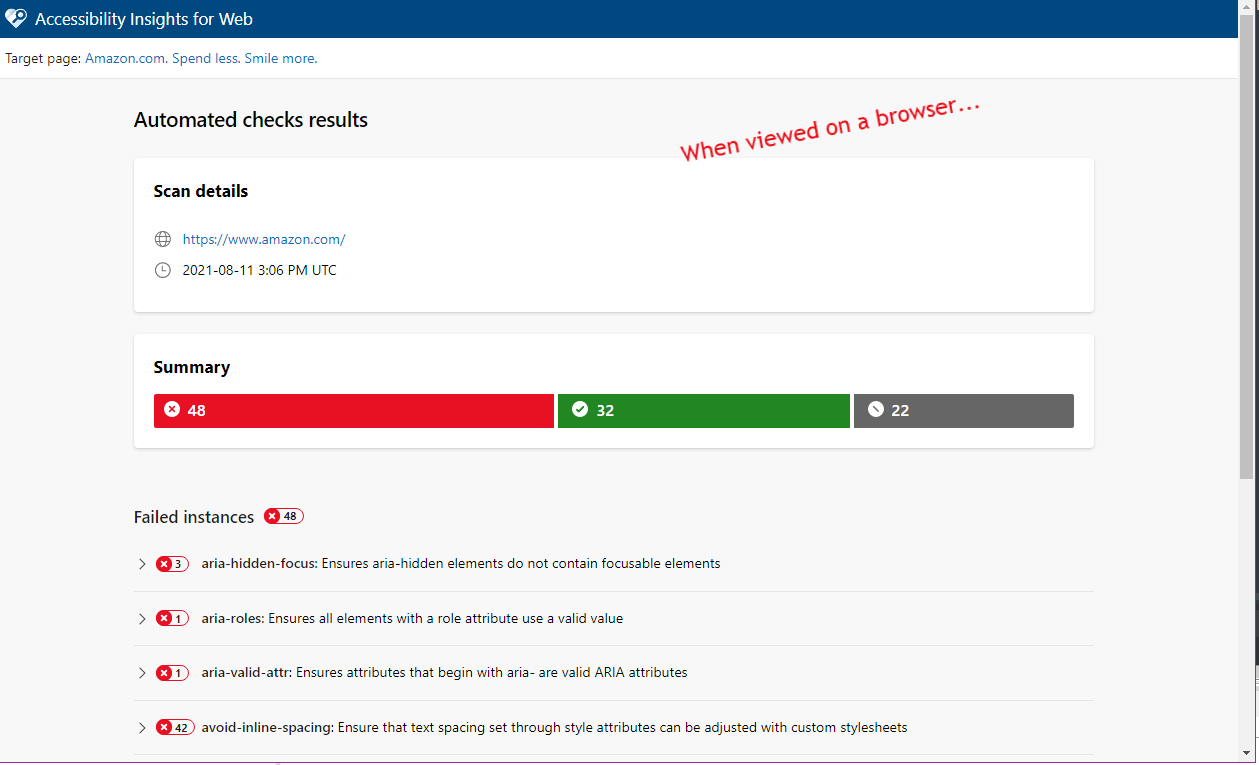
I am trying to parse a large set of HTML files that renders fine when viewing on a browser. Here is the html file. HTML file extension was not allowed for upload so I changed it to txt, hope it works.
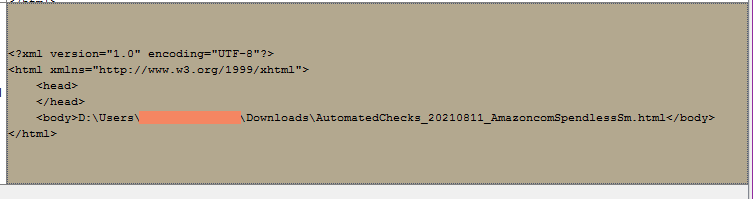
When I open the html file using the text editor, I can see more content in the body tags. Is there a trick or setting or another node I should be using with this HTML file? I have tried different nodes and parser and could not get it to see the content.
Thank you so much in advance for your help and guidance. I appreciate your time and support.
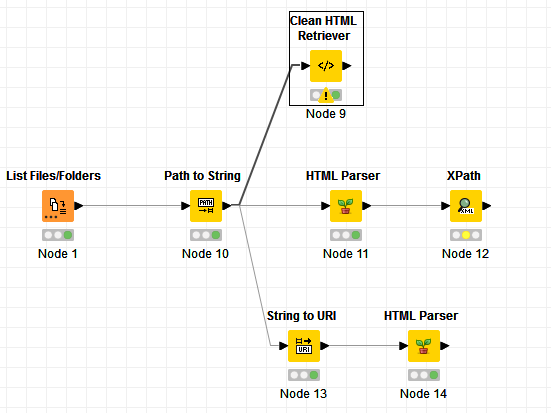
Hi @elsamuel, thank you for taking a look at it. I just list the file, the Path to String and into HTML Parser. I tried different ways but not seeing the content. hhhhmmmm…
Well, as far as I can tell, the problem is that you haven’t read in the HTML content at any point.
Are all of the HTML files that you want to process stored locally?
The HTML Parser node requires one of the following:
HTTP Result cells which you obtained with the “HTTP Retriever” node
Binary data cells
String cells which contain a local file: URL
String cells which contain the raw markup
You got close with using the Path to String > String to URI > HTML Parser approach, but you need to configure the HTML Parser node to use the URI column, not the Location column.
The Clean HTML Retriever node requires URL cells containing http or https URLs, and optionally, String cells containing HTML content. So it’s not a surprise that this didn’t work.
Ahhhhh, I see. I have separate process that downloads the HTML files to local folder. All the .html files are stored locally in a folder (or can be in some share drive). So I have to do one of the above after List Files/Folder? Let me try.

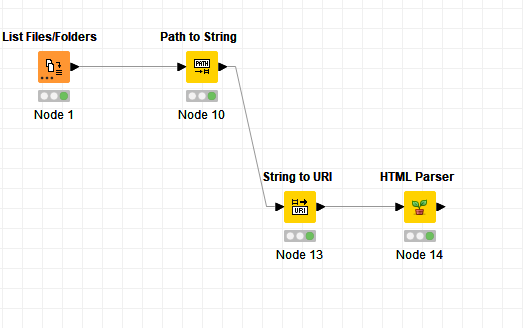
 Thank you and I now need to parse this.
Thank you and I now need to parse this.