Thank You So Much
Thanks It’s Working.
I have a new problem i want to read HTML file data in knime.
The HTML File is containing Table of some data and i want to read the data of HTML file in Excel.
Can you please Help me.
I am also attaching my workflow to you.
1 Like
Thanks for giving me your great time…
Thanks Again
1 Like
Please start a new topic for each of your problems, than they are easier to be tracked. I moved your posts into a new thread.
2 Likes
Hey @Iris it looks like in the end @mythxAHIR created another thread for this:
https://forum.knime.com/t/want-to-open-html-file-in-knime/43468
I think we can close this one here.
Hii All,
Good Afternoon,
I need your help in one problem i am trying to open HTML file data in KNIME and want to perform some task on it i need Help.
I am also submitting my workflow please help me i am a newbie in KNIME.
HTML_READER_Want_to_open_in_Excel_file.knwf (30.4 KB)
Your workflow does not have the html preloaded so it’s difficult to see what you’re doing and what the data looks like.
hi @mythxAHIR ,
this result is a “proxy”, I know, but you only have to type in some headings and format number cells in order to complete it
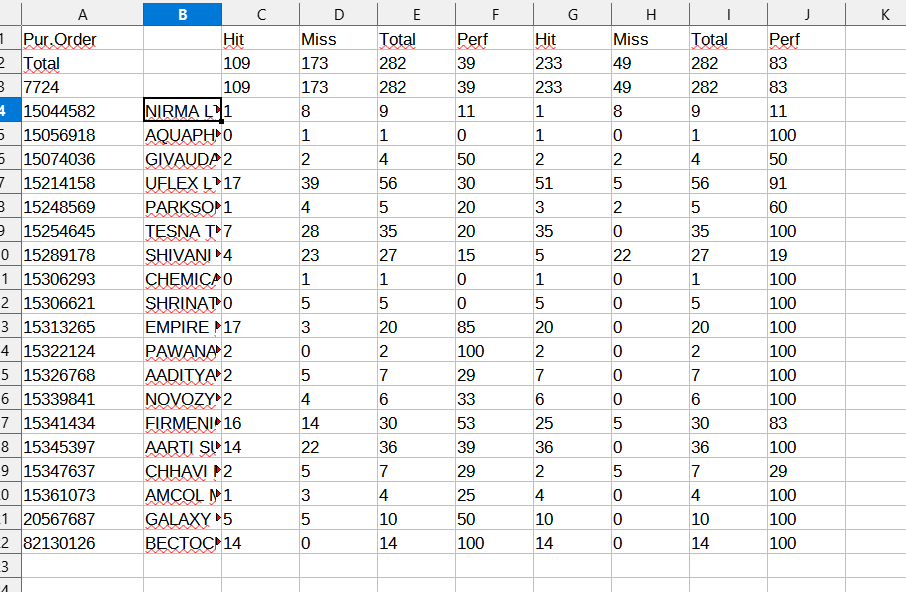
Here’s the workflow
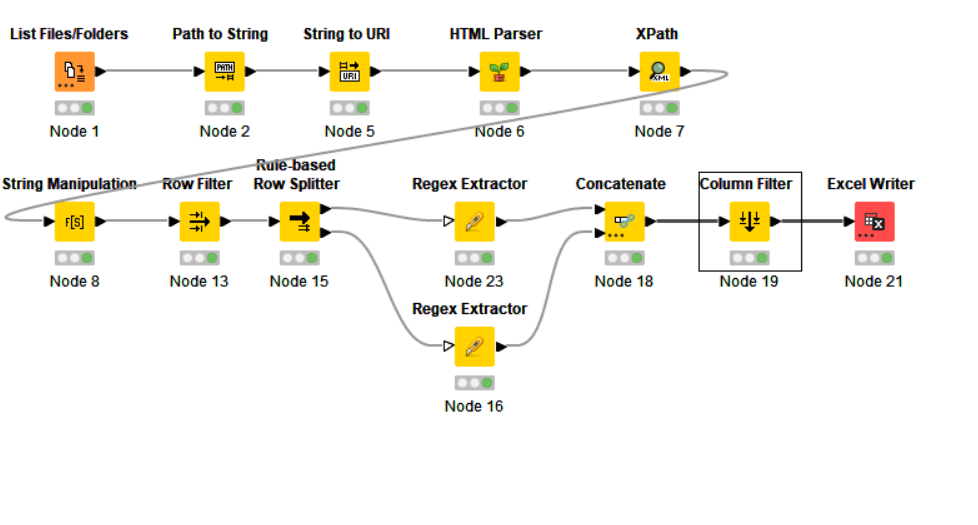
( I’m sorry to tell you, but all the strings are perfectly visible in your workflow - and in mine)
Hope it helps
HTML_READER_Want_to_open_in_Excel_file.knwf (30.3 KB)
4 Likes
Thanks Buddy.
It’s working.
Thanks for help.
It’s Working but want to know about your some code can you explain me.
1).Regex Extractor
^(\d+) ([A-Z 0-9]+?) (\d+) (\d+) (\d+) (\d+) (\d+) (\d+) (\d+) (\d+).*$
2). String Manipulation
strip(regexReplace($row$, “[\u202F\u00A0]+”," "))
Can you please explain me both line.
- this pattern matches a data row:
(\d+) = a group of one or more digits
([A-Z 0-9]+?) = a group of blanks or alpha chars or digits
In the context of the “Regex Extractor” this pattern captures exactly 10 groups of data. If you just want to match a data row, as in the “Rule-based Row Splitter” node, you can use a simpler pattern: “^\d{8}.*?( \d+){8}$” = 8 digits followed by zero or more chars followed by 8 groups consisting in one space and one or more digits each
- XPath returns strings encoded in utf8 and filled with non-breaking spaces, which cannot be easily removed or replaced. The pattern “[\u202F\u00A0]” matches two kinds of unicode non-breaking spaces and the regex replaces every group of them with a single space. “strip” removes trailing and leading spaces, so in the end we have a string with no repeating spaces
As an alternative to this strategy, you could use a “Cell Splitter by Position” node, at least on the data rows, but it’s really boring
4 Likes
Thanks.
Buddy it helped me a lot.
2 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.