When I now connect it (choose the url input in the settings and run it) to the HttpRetriever to get all the content of all urls, I get a HTTP status 401.
I dont get this because when I copy one of the urls in my browser it works perfectly fine and I get no error.
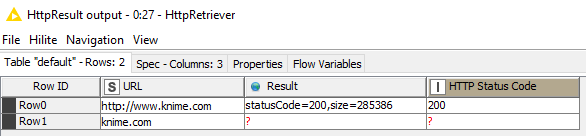
Have you made sure that your input table of URLs contains http:// formatting? Here’s a simple output example of what I see when trying different inputs:
You might try the GET Request node instead - it seems to work. Maybe @qqilihq can shed some light on what’s going on with the #comment parameter in the HttpRetriever node.
We should handle this properly internally (which means, stripping away the #anchor part of the URL before performing the request). I’ll try to supply a fix in the future.
In the meantime, either removing everything behind and including the # will work (the request remains the same, i.e. it’s not transmitted with a browser anyways), or using the GET node will work.