Can you provide some detail and the error you’re getting? What version of KAP are you using? If you can share your workflow that would help. Make sure the data is downloaded with the workflow and not stored on your computer.
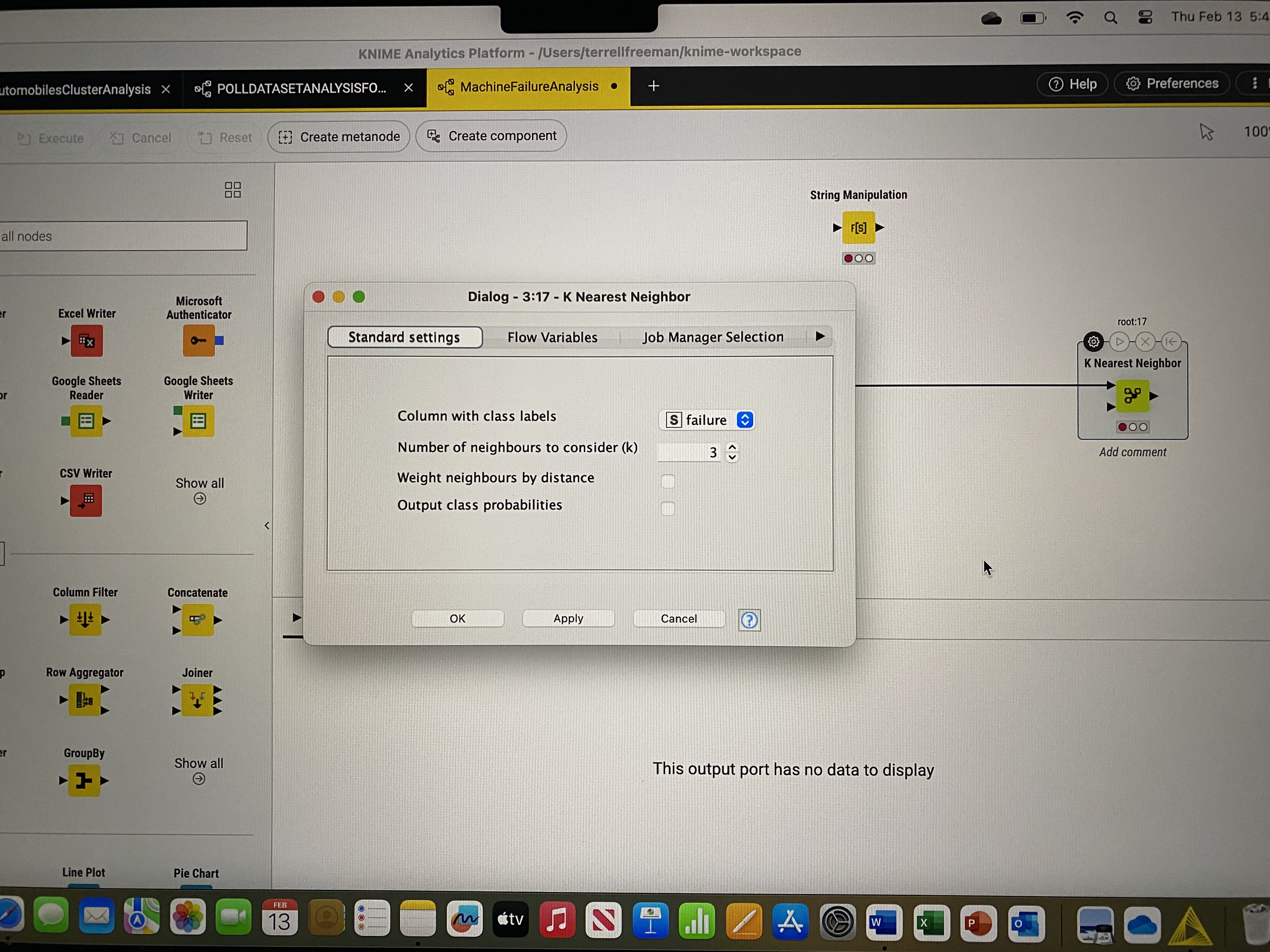
I can immediately see that both input ports of the node are not connected. Both training (top) and test (bottom) sets are required.
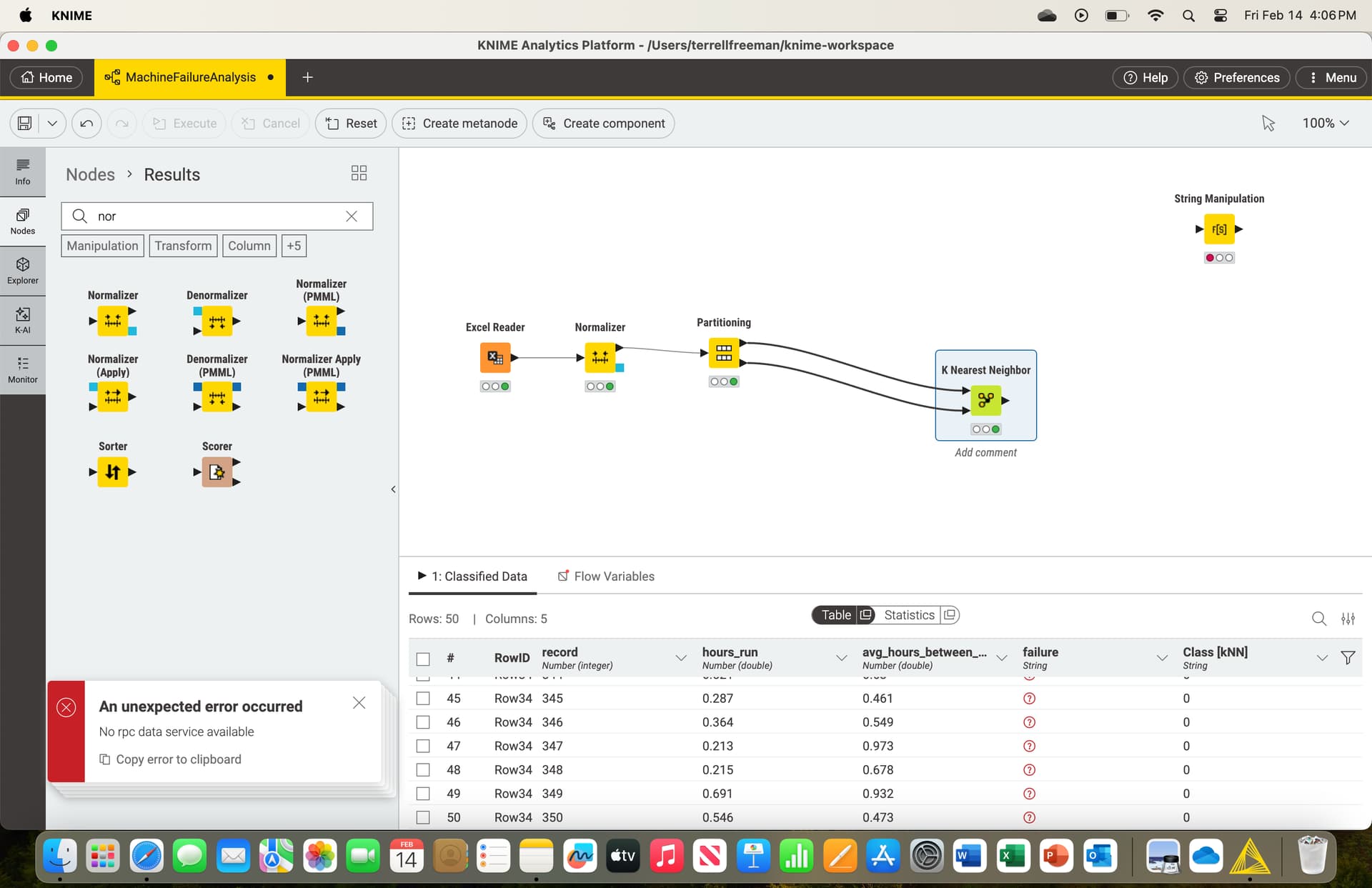
I connected it and it only shows 50 rows. Here’s what I’m trying to accomplish:
You have been asked to build a classification model to help predict machine failure. Using the “Failure Rate” dataset, build a classification model using the k-Nearest Neighbor technique in KNIME. Then, using the model, predict whether machines will failure for 50 records of input data.
Training/Test Model
Use “hours_run” and “avg_hours_between_maint” as the input variables. Use “failure” as the target variable (note that 0 = no failure, and 1 = failure).
For the Excel Reader node, exclude the “model_version” field from the data import operation.
Use a Normalizer node to normalize the “hours_run” and “avg_hours_between_maint” fields to be between 0 and 1.
Use a Partition node with an 70/30 partition (i.e., 70% Training; 30% Test) for records 1-300.
Then, create the model using the Training data from the Partition Node. Use the k-Nearest Neighbor node.
Attach a Scorer node to the k-Nearest Neighbor node in order to evaluate the model’s accuracy (note that this node only evaluates the results of the n=90 Test data). Attach a Table node to the second output port of the Scorer node. Take note of the overall accuracy value. Run the model for k values from 3 to 6. Select the base k value based on the highest accuracy value.
Predictions on the n=50 Data
After running the Training/Test model and ascertaining the optimal k value, create another workflow (in the same KNIME file) to predict machine failure for the rest of the records on the dataset, i.e., for records 301-350. Setup the workflow as shown in the attached “K-Nearest Neighbor Algorithm, Prediction Workflow” document.
Attach a Table node to the k-Nearest Neighbor node to view the predicted results. Sort by the appropriate column to show those records whose machines are predicted to fail at the top of the list.
Youre more likely to get help if you share your current workflow with data. The assignment description is useful but insufficent.
BIT-445-RS-Failure-Rate.xlsx (31.2 KB)
BIT-445-T4K-NearestNeighborAlgorithmPredictionWorkflow.docx (73.5 KB)

Thanks! I really appreciate it. I was really stuck for a while.
Please mark solved if this worked for you.
Dear Sir,
I hope all is well and safe.
I would appreciate it if someone could help me so that the prediction result does not return to its origin (denormalization) (shear strength ). I tried more times but failed
KNIME_project (denormalization ANN).knwf (104.3 KB)
You should move this to a new post.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.