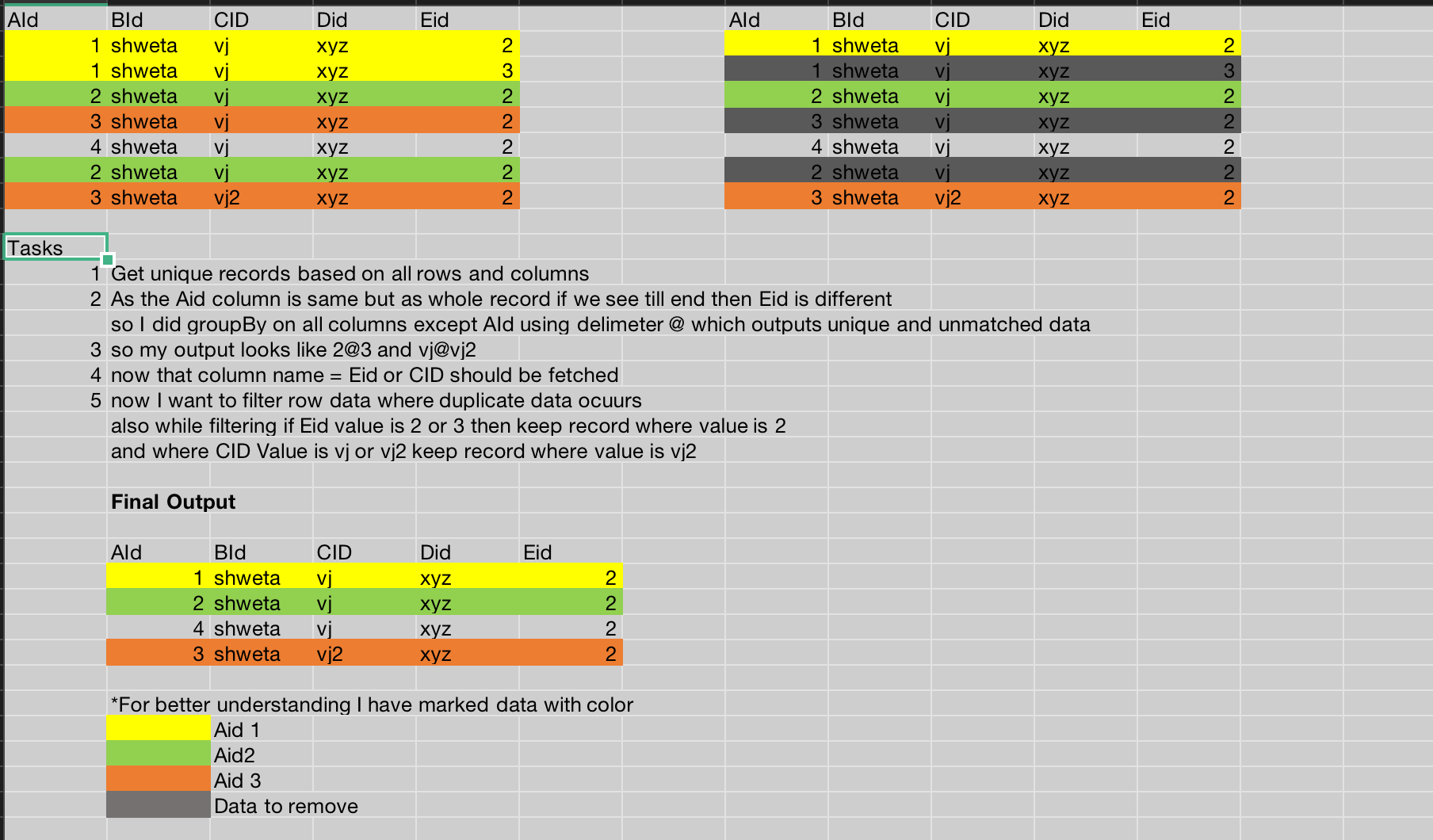
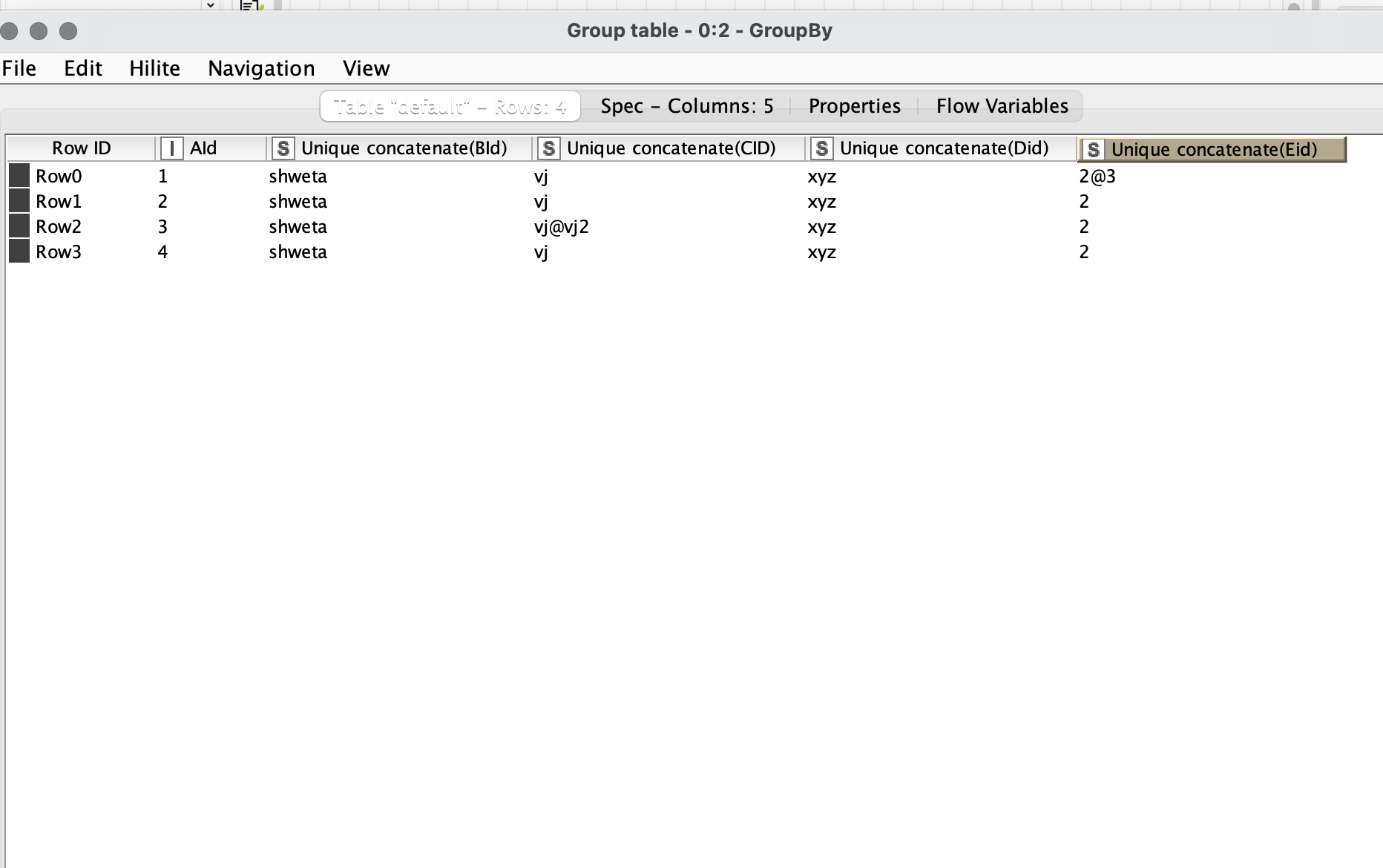
Now I have 2 such columns that are visual that has different data
I want to merge the data with specific value on that specific column
How can I do that?
I am new to KNIME
I am new to KNIME
Hello @shwetaoza,
and welcome to KNIME Community!
Not sure I understand. Can you share how should your output look like?
Br,
Ivan
Hello @shwetaoza,
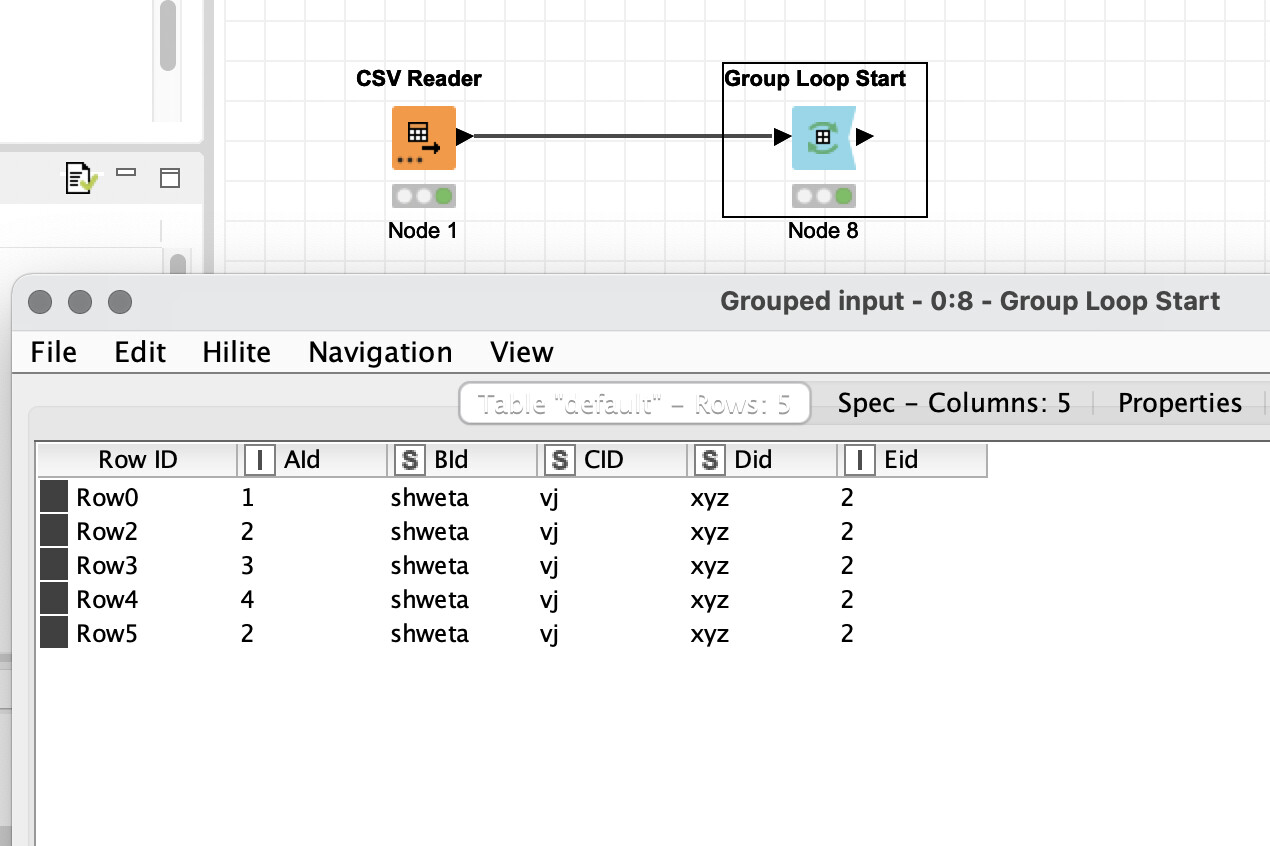
maybe you can get output directly from Duplicate Row Filter node? If not I would go Group Loop Start node and make sure to leave only one row in each iteration.
Br,
Ivan
Thank you for reply!!
Hi @schwetaoza,
I’m assuming that your actual data set is going to be far more than the few rows you have here, but it’s difficult to think how to assist with something that will work for you as the “rules” you have laid out seem very specific to the sample data rather than being more general. i.e. I could write something that does exactly what you request on the sample data but it wouldn’t work if the data differed in any way.
For example,
Are the only options for the CID column “vj” or “vj2”. (Your rule about keeping cj2 in preference to vj implies this. But will that always be the case?
Are the only options for Eid “2” or “3” and again will that always be the case?
Would you choose Eid=“2” rather than “3” because it is the lower value, or are you really expecting a rule to simply state something like " if row A is “3” and row B is “2” then choose the row that says “2”?
You also said (at item 4 in your image) “now that column name = Eid or CID should be fetched”… what did you mean by this? You appear to want all columns fetched…
Trying to understand this at the moment feels like you are giving us an exact recipe for how to deal with the specific sample data rather than a set of generalised rules and I am sure that is not your intention.
I’d like to be able to assist, and it may be just me but unfortunately I’m struggling to picture the actual requirement in a way that I can provide any assistance. Are you able to state your rules without reference to specific data values. That might help.
My apologies if I’m just being a little slow on the uptake today… 
Hello,
Okay let me try and write the scenario as much as I can? Sorry I cannot generalize as my problem is specific.
I need a correct approach of thinking and executing.
similar for other column.
Hello @shwetaoza,
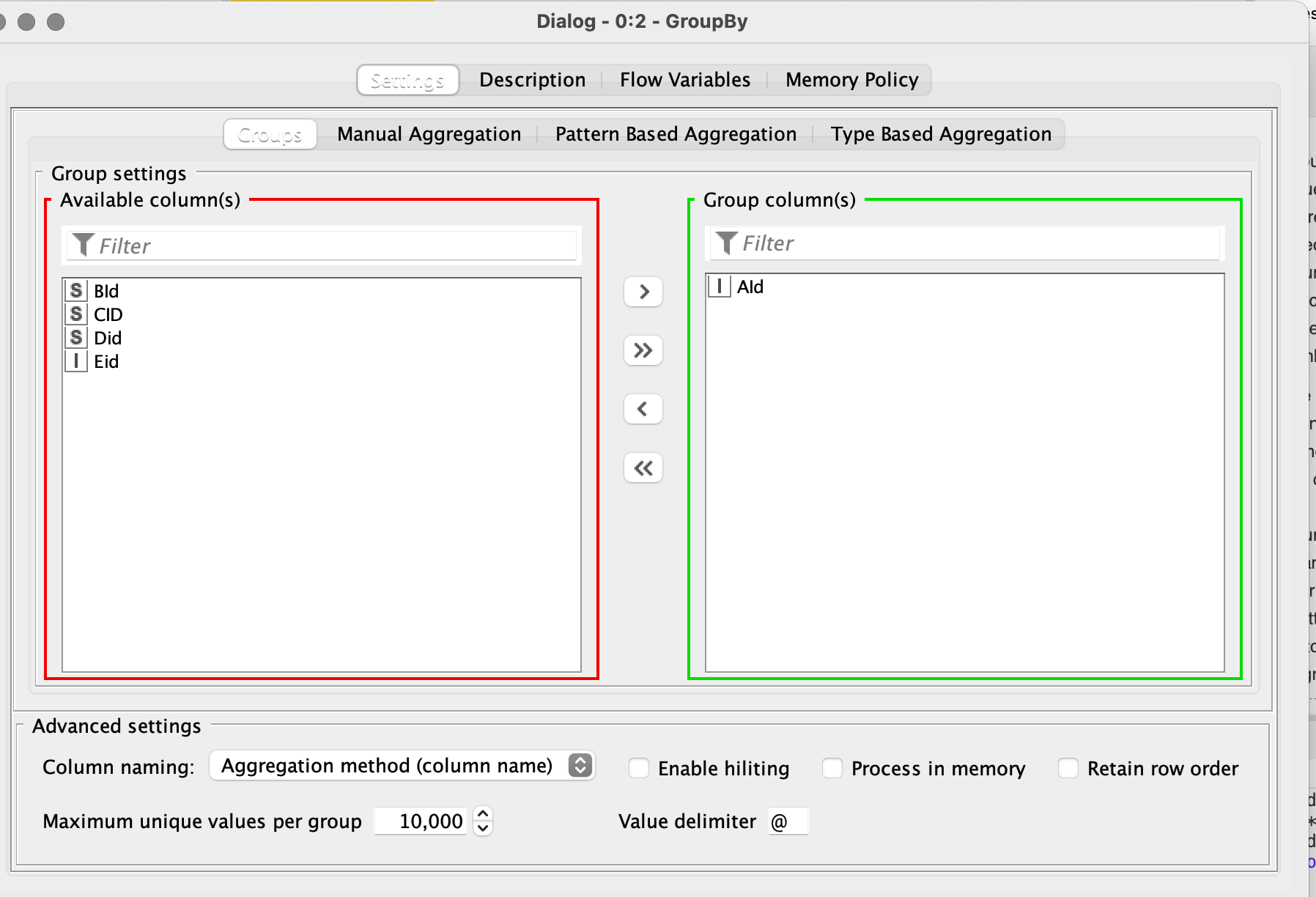
Group Loop Start node is for looping over rows from same group where grouping columns are defined based on your data/logic. From what you have said seems Aid column is your grouping column? If so it will give you in first iteration all rows with Aid = 1, then all rows with Aid = 2 and so on… What you then need to build is logic that will keep only row that you need. I would try sorting rows so that the row you are looking for is always first and then filter that row with Row Filter for example. To close loop you need Loop End node. Additionally you can take a look at this example to better understand how Group Loop works:
Br,
Ivan
Hi @shwetaoza , You could also look at this by grouping first, and then running some rules using Column Expressions on each of the columns.
I don’t particularly like this mechanism because I would rather that rules could be parameterised (or at least be based on standard “zero code” nodes) rather than being written so specifically “in code”, but it’s another approach.
I think this is made challenging in part because you headed the question “get the columnname and value where there is a duplicate”, but that appears to be just part of your proposed solution rather than the actual end goal. It’s generally better to simply state your starting position, your rules, and required result (and of course show what you have already tried). If getting the column names is purely a means to an end, then it isn’t necessarily relevant to any given solution.
The rules that you have (e.g “vj2” is returned in preference to anything else in “CID” if it appears, and likewise with the value “2” in “Eid”), don’t really lend themselves to generic node structures. Maybe for each column you could have data in another table giving some kind of “order of preference” of values, so you could then build something that looks for multiple values in the groupings for each column and then orders those values in a preference order, and uses the first/best it finds?
For example I don’t know from your rules what should be returned if the CID column contains only “vj3” and “vj4”… at the moment it appears to be purely arbitrary.
Here is a sample flow built using a loop with rules coded in a column expression. The column expression itself performs iteration on collections of values returned for each group defined by AId, and has simple rules to determine a value to return if there is more than one available. Where it doesn’t have a fixed rule, it just returns the first one in a given list
Merge rows and filter collisions based on rules.knwf (17.3 KB)
[Edit: it should be noted that this workflow doesn’t persist any specific rows, but actually chooses values from merged rows, so if you always want to keep the entire rows where it is “vj2” in CID , then this solution doesn’t necessarily work. ]
Hi @shwetaoza , I am not sure I am clear on the rules.
The only rule that I am 99% sure is that AId should be unique 
AId, BId, CID, Did, Eid1, shweta, vj, xyz, 21, shweta, vj2, xyz, 3If v2 precedes all other then maybe first split rows to only keep vj2 and drop duplicates there. The other split drop duplicates there as well and then go with some logic to ensure the vjX in second split which already exist as vj2 in the first one do not get concatenated to the first split.
(Not sure whether I understood your requirements correctly however)
I did not thought till that…
I think I need to check the type of column if CID is string then define some rule like fixed value check i.e vj2 eg: CID = string, compare row data vj and vj2 and if string data substring found 2 at end then choose that
eg: EID = number, compare 2 with 3 choose 2 as 2<3 here rule will be less than value
priority will be given to first record.
Hope this helps.
Hi @shwetaoza , another question, what if an AId has several vj* but not vj2, which one should be picked?
For example:
AId, BId, CID, Did, Eid
1, shweta, vj, xyz, 2
1, shweta, vj3, xyz, 2
1, shweta, vj4, xyz, 2
Which vj* should be picked here?
choose vj3
always choose second largest after 2,
here vj2 is not present hence choose vj3
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.