Hello, good people. My issue is as stated in the title: I’m doing an analysis on the text of scraped Instagram posts that I’m later feeding to a Topic Extractor (LDA) node and then continue the analysis.
Problem is, I tried with a Stop Word Filter node, I tried adding a custom stop word list, I tried the Dictionary Tagger and Replacer nodes with a custom list, I tried lemmatizing before and after the nodes, but nothing… Some instances of the words I want to see deleted still remain in the text, and they later get picked up by the topic extractor node which creates many redundant words shared by multiple topics.
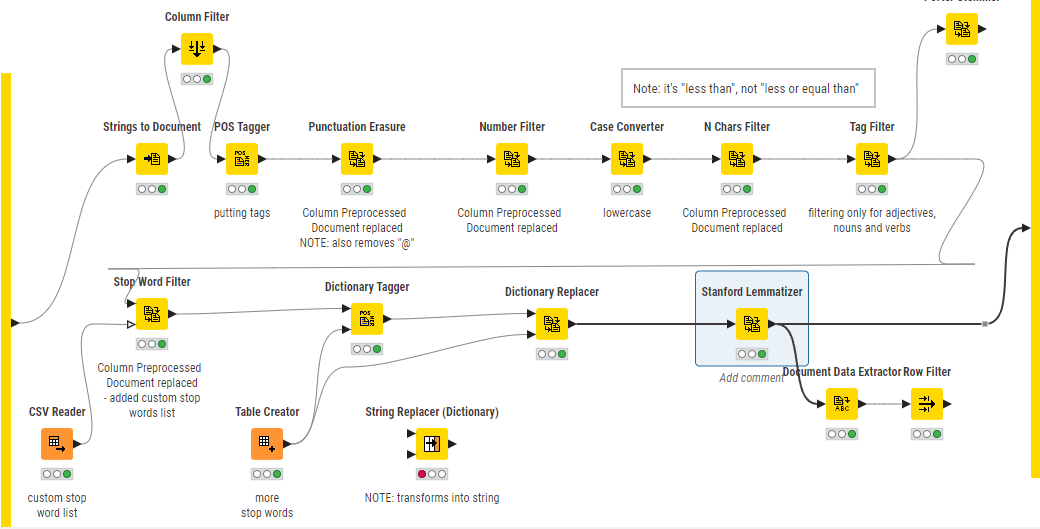
Here’s a snippet of the preprocessing (pardon me for the mess):
I’ve entered not only contractions such as “n’t” inside my list(s) but also full words like “cities”, and yet they’re still present in the output. I don’t know what to do at this point, other than doing a String Manipulation before turning the text into a Document? But that would be pre-lemmatization, so some occurrences could still be missed later on.
Additional note: I left the “replacement” colum of the table creator node empty, because earlier I filled it with a single space for every row but the dictionary replacer node shot back with the following error message: “Execute failed: index -1 out of bounds for length 0”
Fact is, even like this it does erase some of the specifies words as seen in the output… which is why I’m so confused
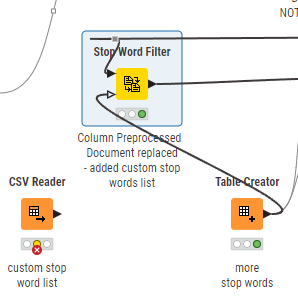
I wasn’t able to use your custom stop word list since you didn’t upload it, so I just used your Table Creator as a quick check. As you can see, it’s definitely filtering stop words:
Maybe you got crossways with your Document and Preprocessed Document columns somewhere in the mix? That’s a common error when dealing the Textprocessing nodes…
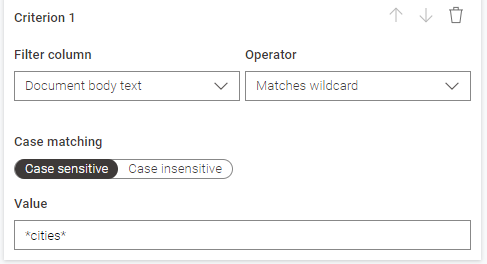
Through the Document Data Extractor inside the metanode I filtered out some rows with “cities” an example, and there are indeed some rows in which it is not deleted.
There was indeed a mixed input between Document and Preprocessed Document in the lemmatizer node (thank you for pointing it out!), but unfortunately the output is the same.
I must confess I’m not seeing the same results you’re seeing. I can’t duplicate the problem.
Having said that, the Dictionary Replacer does seem to be behaving somewhat strangely. Instead, what about using a Tag Filter node after the Dictionary Tagger, where you are currently applying a NE tag with value UNKNOWN? That seemed to work for me: