I am new to use KNIME, I created the workflow with cross Validation workflow, it the workflow I used the parameter Optimization node loop to found a optimize parameter for my decision tree ( min. of of node , threads). But I have a following error in my flow.
"
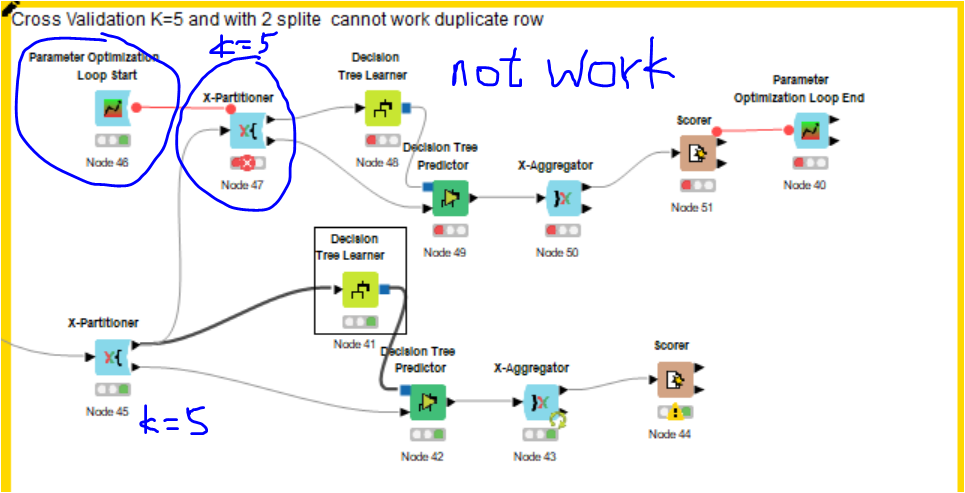
WARN X-Partitioner 3:45 Unable to merge flow object stacks: Conflicting FlowObjects: <Loop Context (Head 3:46, Tail unassigned)> - iteration 0 vs. <Loop Context (Head 3:45, Tail 3:43)> - iteration 4 (loops/scopes not properly nested?)"
Hi,
You cannot have the connection from the first X-Partitioner to the second one. That is because when you track your flow, every loop start must be ended by the corresponding loop end, no matter which branch it goes. But your bottom X-Partitioner’s loop end node (the X-Aggregator on the bottom right) is not in the flow at the top. Why do you have two X-Partitioners anyways?
Kind regards,
Alexander
1 Like
Hi Alexander,
Thank you for your prompt reply. I intend to use the top X-Partitioners for finding the optimize parameter of Decision tree (No. of thread and minimum number record per node). Therefore the upper loop further split the data (80/20) for this purpose . I would like to ask, is there any more material/guideline of how to write a loop workflow ? Thanks
Best Regards,
CK Lau
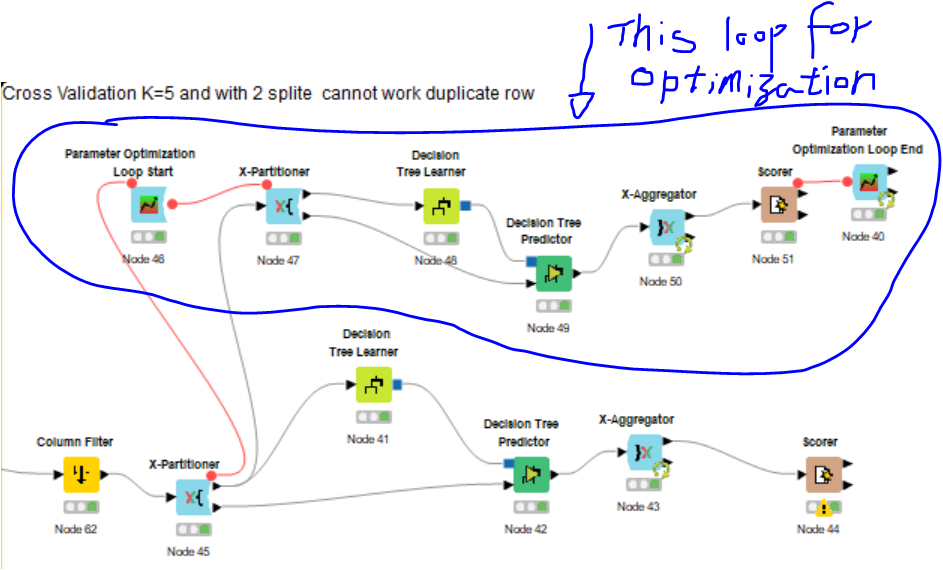
Is any comment on this workflow?
From the Node 40, I get the best parameter then. I will input into the Node 41 (decision tree).
I have a question , why I need to connect the Node 45 (variable) to Node 46( Parameter optimization Loop start). Thanks
Hi,
You can learn more about loops in our self-paced training. I do not think you need nested cross validation. The Parameter Optimization loops through the different hyperparameters and the X-Partitioner splits the data into test and training sets. So just keep the top part and connect the input of the top X-Partitioner to the Column Filter at the bottom left.
By the way: the number of threads is not a hyperparameter of the decision tree. It just tells the algorithm how many threads to use for the computations. It does not matter what you enter there, the tree will always be the same, only the speed with which it is created may change. But trying out different values here does not make any sense in the context of cross validation.
Kind regards,
Alexander
1 Like
Thanks Alexander. For reviewing my workflow. Thank you very much
1 Like
You are very correct
Also , may i ask why you are using the loop start , you dont need that , just use the partitioning node after column filter , remove the x-agrregator in the loop for optimization , remove x-partioning after the loop start. You can further add decition tree Vier node to view your Decision Tree.
Hope that helps
Hi ,
Actually , I want to create a workflow to optimize the min number records per node (In decision tree) hyper parameter by cross validation. therefore , i am using the loop start with X-practitioner and X-aggregator in my flow.
Best Regards,
Lau
Dear all,
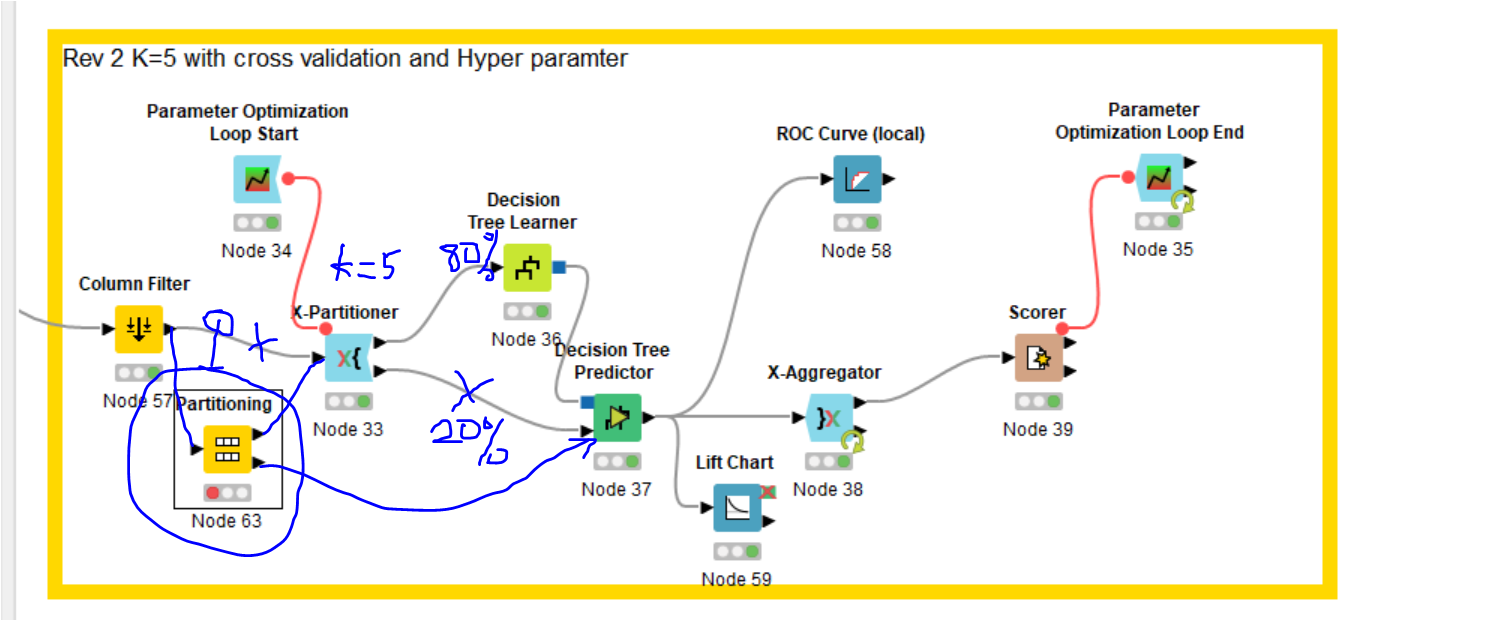
I have further question, I want my raw data (80%) go to the training (decision Tree Learner node 36) and 20% for testing (Node 37), do I need to add partitioning node (Node 63) between column filter node 57 and K-partitioner Node (33) ?
What is the different of K-partitioner and partitioning ?
Thanks
Hi,
You do not need the Partitioning node, because Cross Validation is already doing Partitioning (in the K-Partitioner). In Cross Validation, you split your training data into k partitions. Then you train your model on k-1 partitions and use the other one for testing. In every iteration, another partition is the test set. The K-Partitioner takes care of this for you and outputs a different training and test set in every iteration.
Kind regards,
Alexander
1 Like
Thanks Alexander for the prompt reply
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.