I am trying to process an XML file, but some XPath processing does not work as expected. Sometimes, the result of the very same process of one XPath node is good in places, in other it is not.
I’m not sure if it is a bug, but I cannot see that the behaviour is desirable, and I cannot see a way to avoid what is happening using just a single XPath node.
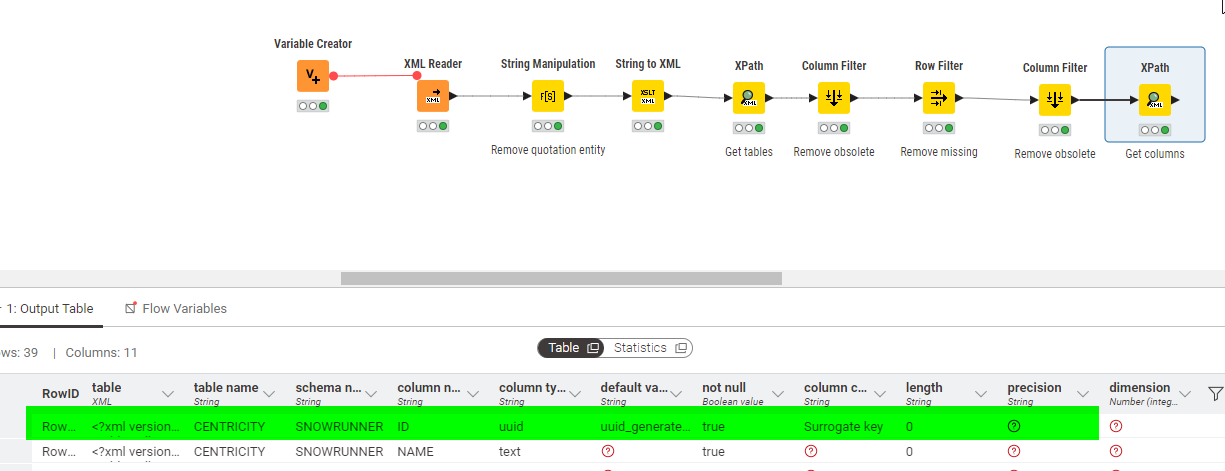
What it looks like is that all of the various attributes are returned , and then they effectively get shifted to the top of the table rather than returning “blanks”.
If, for example, I restrict the XPath to just acting on row 4 of your input data, it returns this:
What is evident to me is that all non-null values have been shifted upwards regardless of which row they should be associated with!
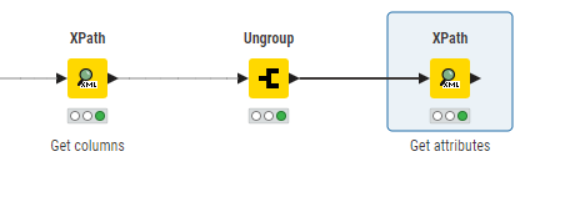
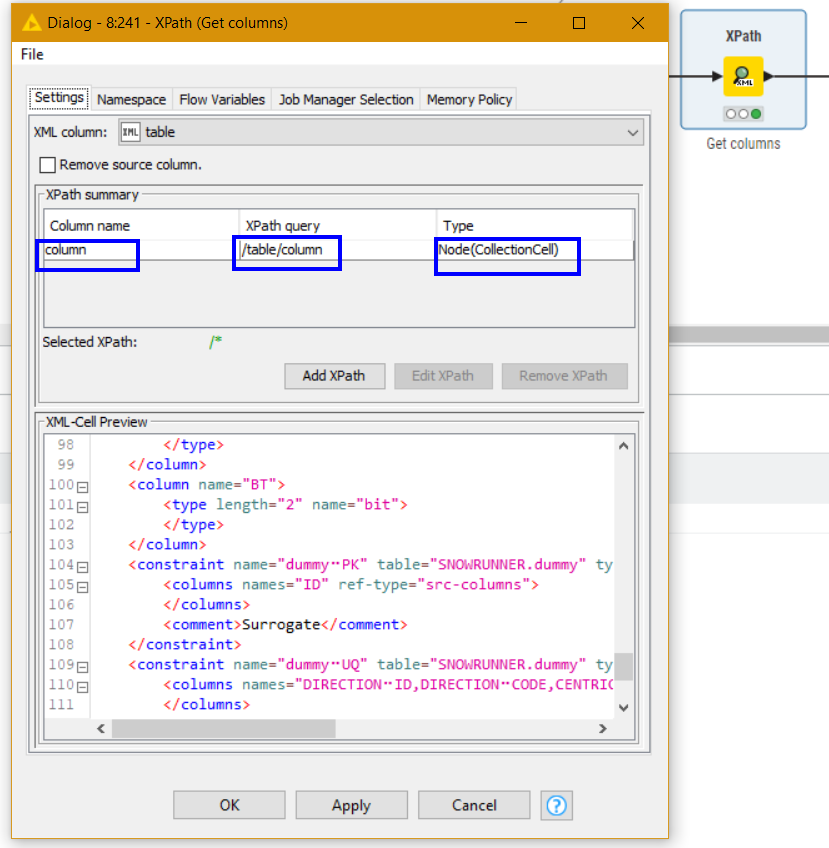
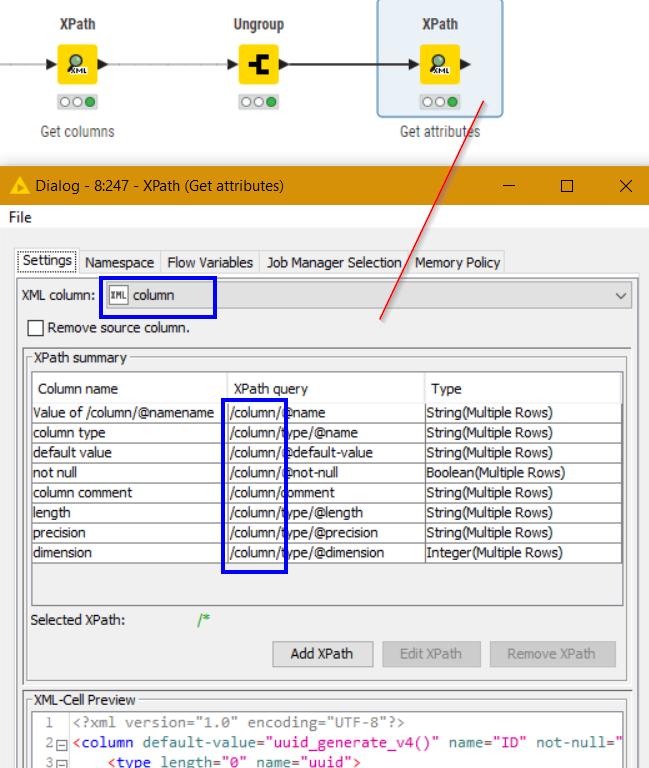
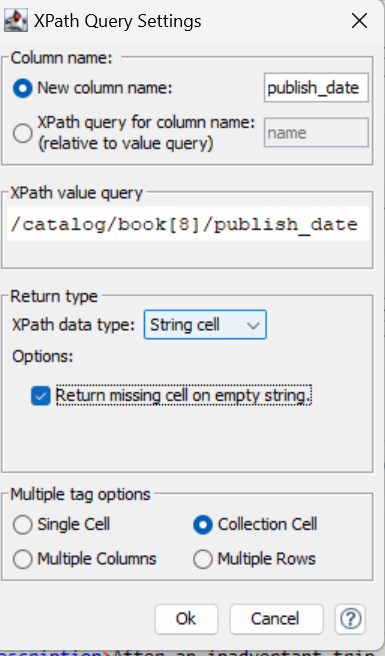
The only way I see at the moment of returning attributes associated with their “Columns” (and I mean the “Column” elements in your xml data) is to first using XPath to return a collection of column and ungroup these. Then do your further XPath on these returned elements:
Note in the following, this is your original xpath but now at the /column/ level rather than /table/column/ level, as it is processing the “column” xml generated by the previous xpath node:
ahh, XML, that brings back some nice memories. What you experienced Thiemo caused me quite some pain until I understood what needs to be done.
Takbb already pointed towards the solution:
I cannot see a way to avoid what is happening using just a single XPath node.
You need to follow the “Divide et impera” principle or in other words, try not to do everything t once. Use one XPath node to extract the first axis / elements as nodes, then another XPath to get their data or again XML-data.
That way you can also parallelize the extraction and ensure data coherency. Another trick would be to extract the data as a collection, always ensuring return missing cell on empty string is checked.
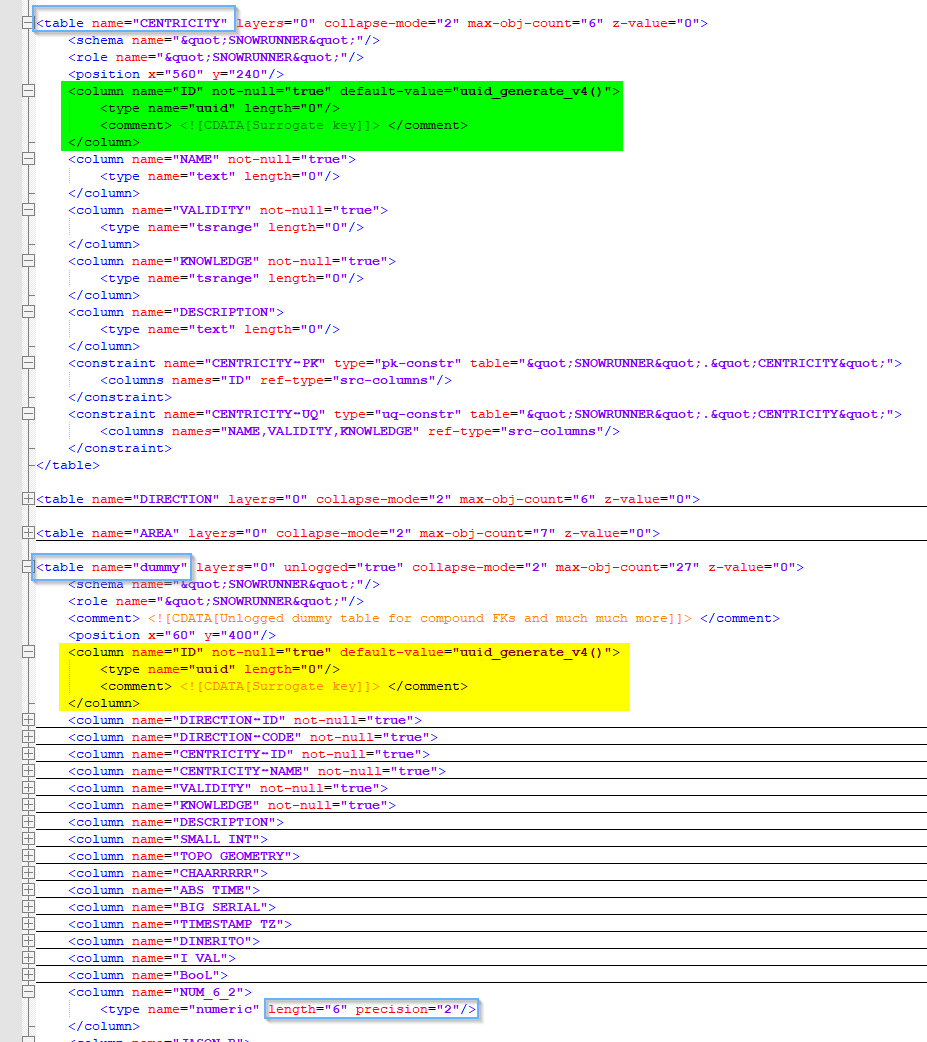
To add a bit more context. If an XPath does not match, it does not give back a result. Hence, causing data disjoints. Here is an example of the issue you experienced:
Thanks for looking into it. Re-association of values to another “object” sounds buggy to me. And why, your suggestions sound quite familiar. As you can imagine, I did not come across the issue out of thin air. It popped up within a forbiddingly vast flow, I will publish when I finished.
I already used a bunch of XPath nodes because of such problems, and I wonder why I could not or did not think of doing this again. I hope to have another go on this in the next couple of days.
What we meant is, after reading the XML, you use multiple XPath nodes to split apart sub-nodes prior to extracting their data. But I believe you got the point, though, might have gotten a setting wrong or so.
Just in case publishing the workflow is not possible, I could offer we both connect via a Hangout, Teams or other means and we have a look at your workflow together.
The following file is the svg of the workflow. As this forum block svg, I put it into a 7zip, and as this is not allowed either, I renamed it to out. A bit of a nuisance. I did not mean anyone to delve into my horrible workflow. I just wanted to illustrate that my problem is a part of a bigger solution. workflow.out (91.1 KB)
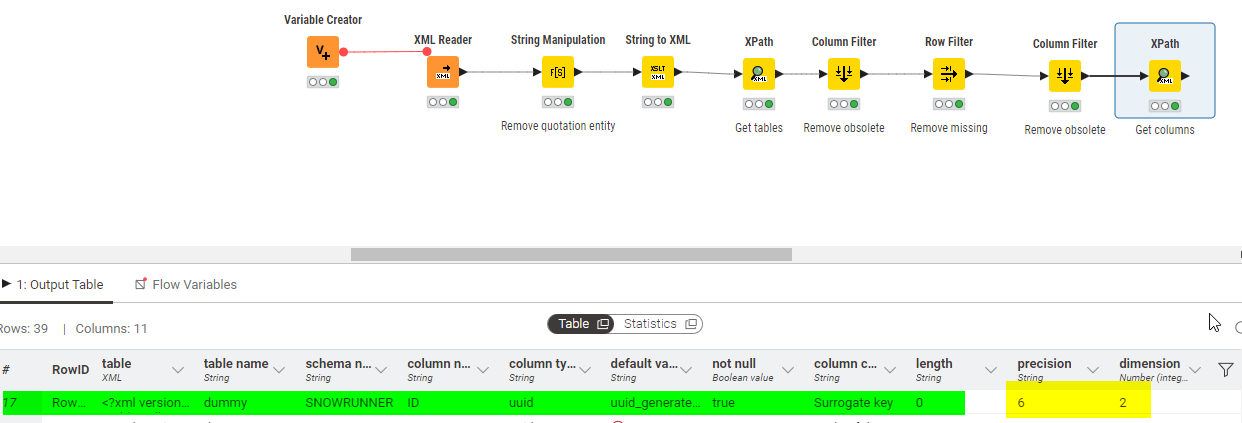
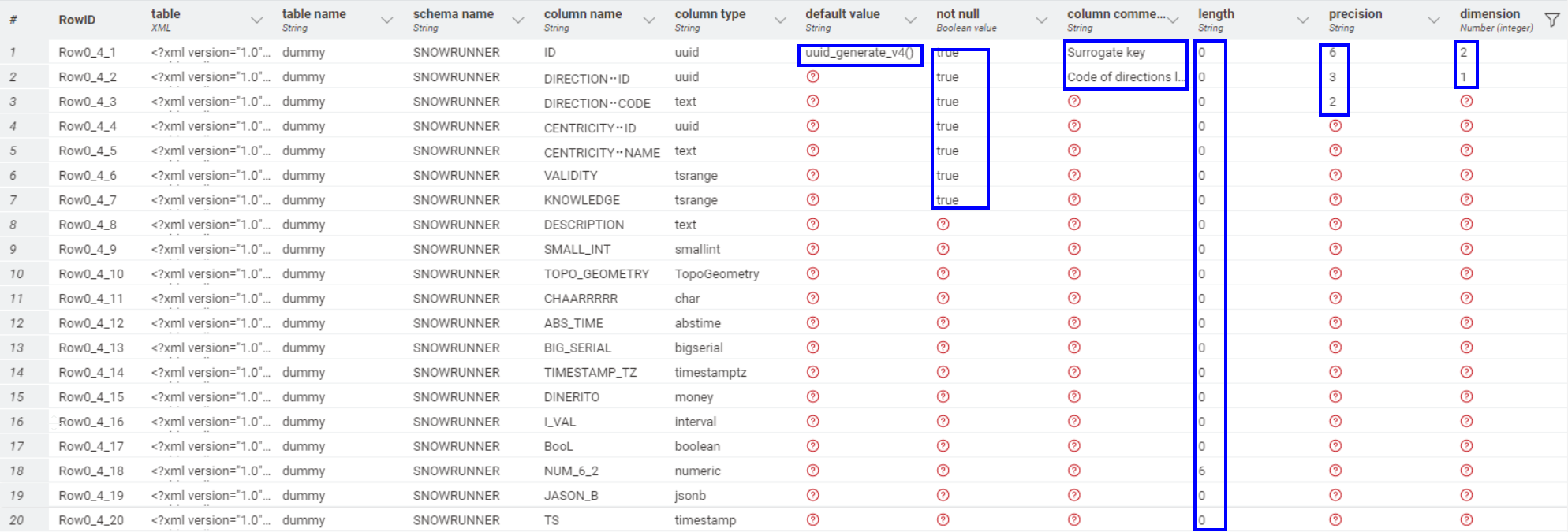
Be it as it may, with re-association I mean that the values of the attributes length and precision belonging to the column with the name NUM_6_2 are associated to a column with name ID. This association does not reflect the XPath in the document.
The expected behaviour for me is either, the information cannot be found because the XPath is wrong in the context of the remaining xml document or the association is correct.
I think I know now why I did not split the XPath processing further. I noticed the strange behaviour. But there I was mixing the tag (element?) levels for the extraction, e.g. some attribute values of the table tag with some values from the column tag. But in this case, I am extracting the information of a single level, being /table/column, thinking that was fine.
So, I suppose, I need to extract the from the table xml a column xml document before feeding in the XPath where I have to reduce the path by /table.
I supposed that KNIME would not invent an XML parser but use a library and I wonder, whether that behaviour is present there too.
Thanks for sharing and explaining what you meant. I can now comprehend it. The scenario described sounds rather complex and without having an actual sight into the workflow and data I am afraid to say it won’t be possible to help you out.
About XML and XPath, I have processed rather complex files where information, i.e. about parent and child SKUs, images and categories, was split into different files with delta processing took place which resulted in not all required information was not always in that file which was processed.
Feel rest assured, there is always a solution. If you want to connect for a remote debugging session, or share the workflow and data privately, send me an email at info@atmedia-marketing.com