Hi @Thiemo.Kellner and @takbb,
ahh, XML, that brings back some nice memories. What you experienced Thiemo caused me quite some pain until I understood what needs to be done.
Takbb already pointed towards the solution:
I cannot see a way to avoid what is happening using just a single XPath node.
You need to follow the “Divide et impera” principle or in other words, try not to do everything t once. Use one XPath node to extract the first axis / elements as nodes, then another XPath to get their data or again XML-data.
That way you can also parallelize the extraction and ensure data coherency. Another trick would be to extract the data as a collection, always ensuring return missing cell on empty string is checked.
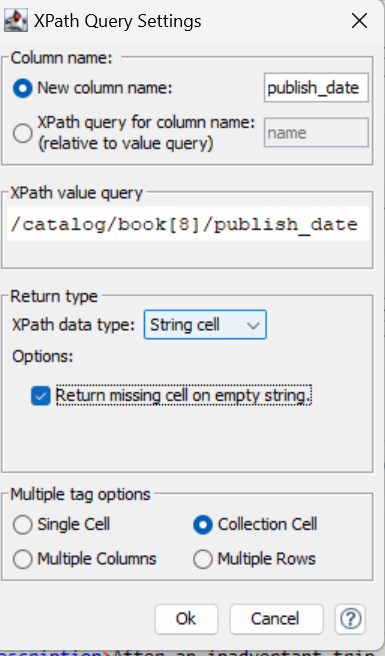
To add a bit more context. If an XPath does not match, it does not give back a result. Hence, causing data disjoints. Here is an example of the issue you experienced:

Here is the example workflow:
Cheers
Mike