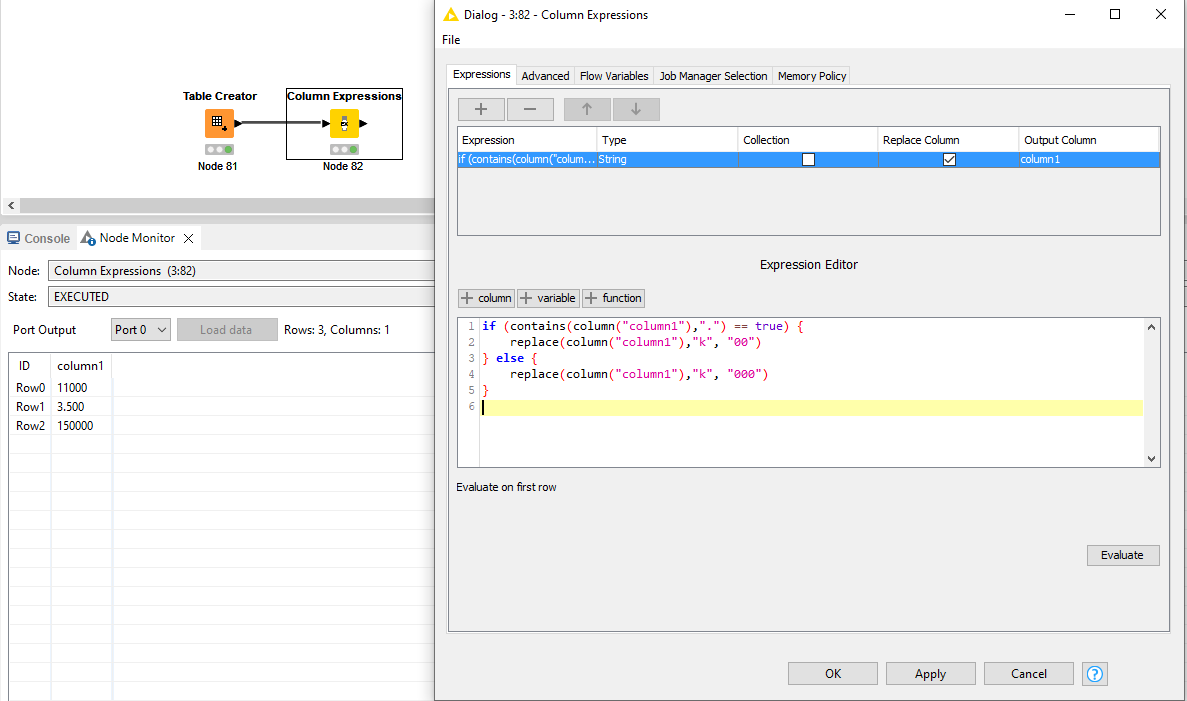
I have multiple columns from a web scrape with cells that have thousands abbreviated with a “K”
If it was only something like “11k” i could just replace “k” with “000” and call it, but there is a mix of “11k”, “3.5k” and normal cells below 1000 with no “k”
How can I clean this data in KNIME?
“11k” would need “000”
“3.5k” would need “00”
Anything below 1000 needs nothing changed.
My (not so elegant) solution is to use String manipulation to replace all instances of “k” with “000”, Use the Cell Splitter node to split the cells with “.” as the delimiter, then in the new column, replace all instances of “000” with “00”, then I am using the String Manipulation node to Join the two columns back together.