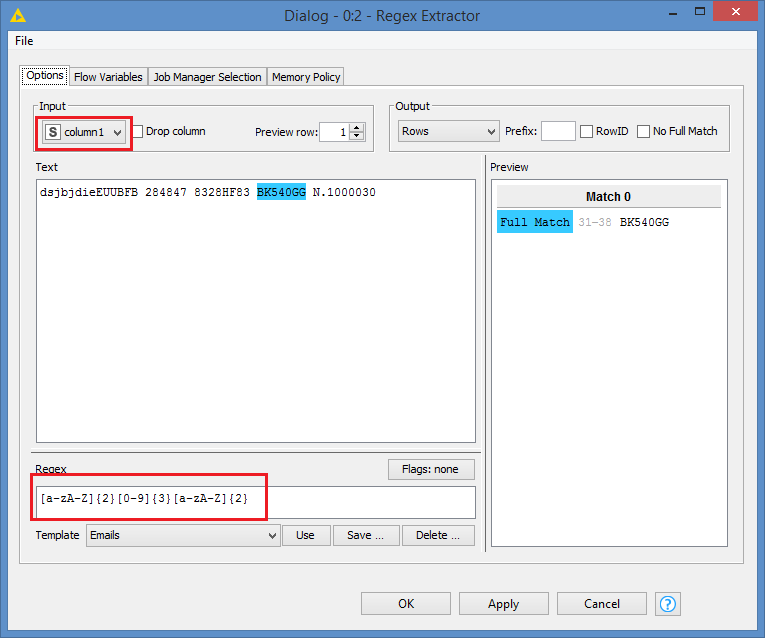
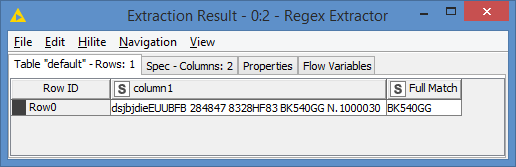
I would like to extract from a column which contains a description, a string only when it is equal to a given combination of character’s type. For example, i want to extract from: “dsjbjdieEUUBFB 284847 8328HF83 BK540GG N.1000030” a string when corresponding to the following combination “LETTER & LETTER & NUMBER & NUMBER & NUMBER & LETTER & LETTER”, that is “BK540GG”.
I’m trying with the “Regex Split” and it doesn’t work. The message displayed is the following: “Input strings did not match the pattern or contained more groups than expected”.
I’m going to try with the node you were sharing. I’ll let you know.
Thank you anyway
Edit: my source is a Excel Reader node. Maybe this could be a problem (?)
@mpoppi it should be possible with the String Manipulation — NodePit
I don’t have a KNIME environment available right now so I cannot add a screenprint for you, so this is from memory.
Use as function regexReplace($yourColumn$, "(.*)([a-zA-Z]{2}[0-9]{3}[a-zA-Z]{2})(.*)", "$2")
You’ll recognise as second group the regex given by @bruno29a. A group in regex is anything between these brackets ( ). Whatever is matched as a group can be used again in the replacement by $1 for the first group, $2 for the second and so on.
In the above formula the first and third groups are simply skipped in the replaced argument, leaving the second part you are looking for.
Hi @JanDuo , it’s exactly what I was looking for. I’m not an expert with Regex. In fact, I’ve only started writing regex on my own a couple of months ago, so I’m not too familiar with what $1, $2, etc are, but you pretty much explain what they are. It’ll take some time for me to get used to how to use them.
I initially tried to use the negate sign (^), thinking I could remove anything NOT matching, but that did not work.