Hi! I was wondering if there’s a way to identify overlapped values on two different columns.
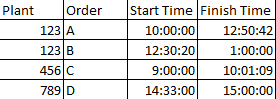
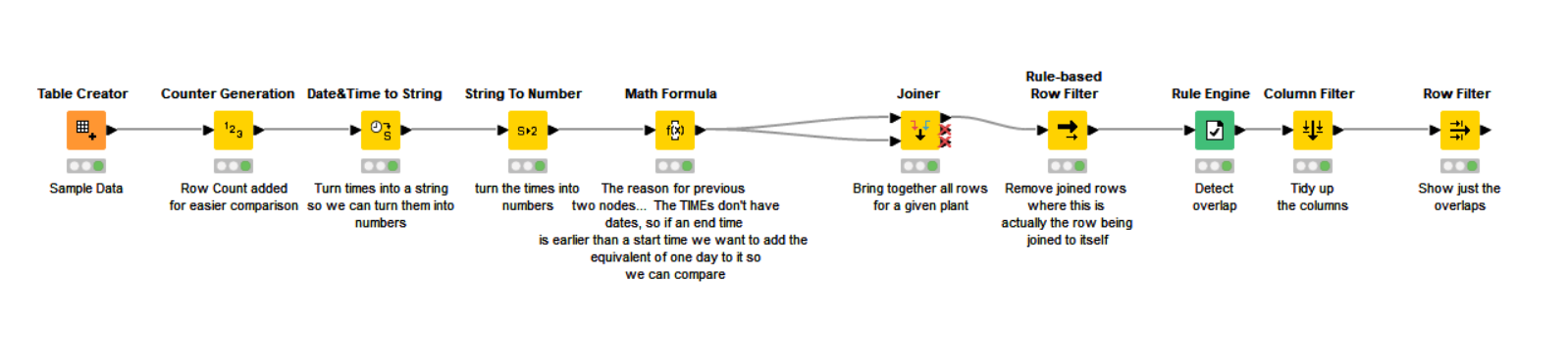
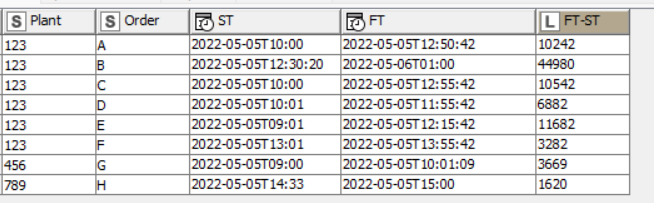
To give a bit of context, I have a table that looks somewhat like this
So, the thing is that for plant 123 the order B starts before the order A finishes and that type of overlapping is what I’m tryng to identify, but the data is huge and it would take my forever. Is there a way to make this easier?
Hi @LuisMP
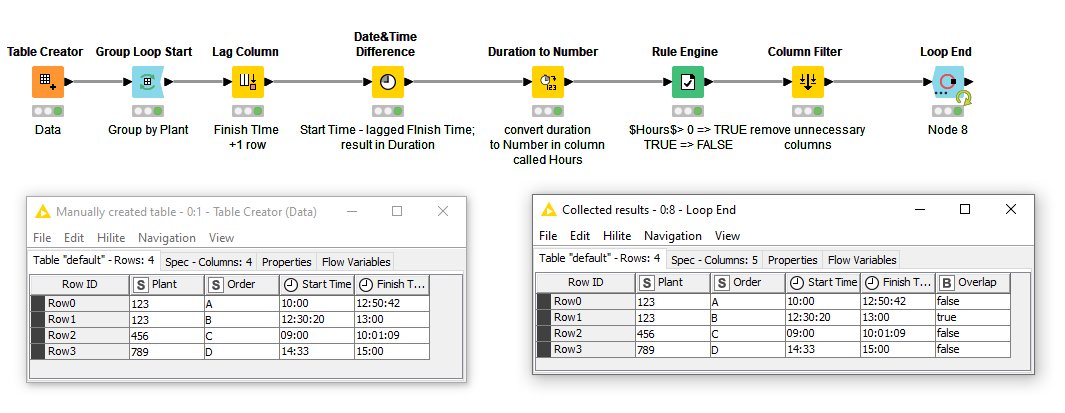
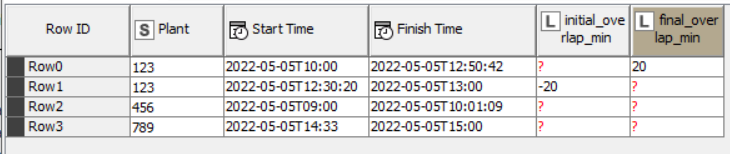
I did a different approach, identifying overlapping time in minutes. Negative overlaps stand for overlapping at the beginning of the interval, in the other hand, positive overlaps happen at the end of the interval.
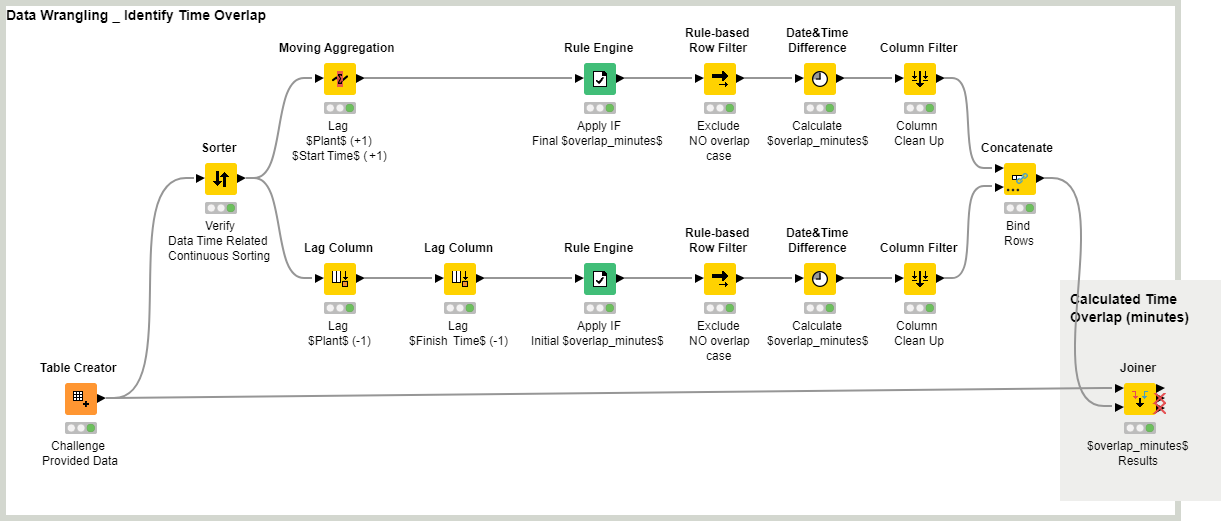
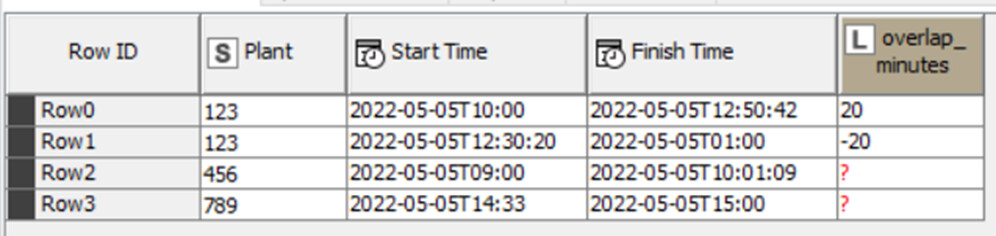
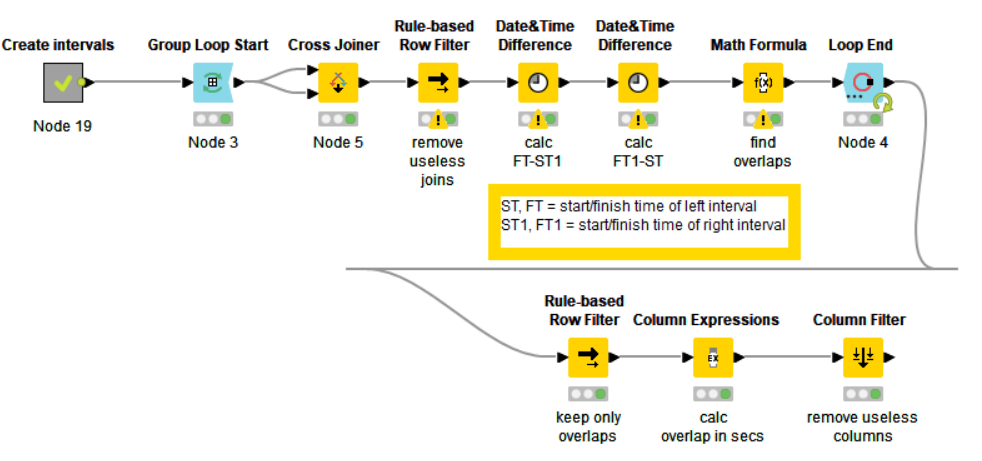
Demonstrating that KNIME often provides multiple solutions, here is another take on it. As your times don’t include dates, my initial stab produced incorrect results where an end time crosses midnight and so appears to be earlier than the start time. So I chose to turn the times into numbers so that I could adjust end times upwards if they were earlier. Of course if a process takes more than 24 hours this could still pose a problem!
Based on your example, I assumed you were looking only for overlaps within a plant. If that was not a valid assumption, the workflow would require tweaking.
Of note to me… I think this was the first time I’d made use of “logical arithmetic” in the math formula node. That node isn’t well known for it’s ability to do conditions, but for basic logic returning 1 or 0, it can conditionally add to the end time if the end time < start time:
But to be honest, if I think about all the causalities coming with real data… what if an item interval is included in other one? what if several item intervals overlap the same time period?
I am starting to have doubts about that this is the needed approach, or at least the whole scope of it. Extended comments on this subject will be appreciated.
Yeah… first of all, I would’ve liked some pens. Game was boring up until the 85th minute.
Second of all, perhaps I didn’t give the full story and that’s my bad. So, apart from having the start time and finish time columns, I’ve also got start date and finish date on separate columns each one. I’ve checked most of the data and there seems to not be any overlap between dates, like there’s no order starting on a day and finishing the next day.
So far, the approach you gave me works fine. Sent the preliminar data for review and feedback, so I’m waiting for that to see if the approach is enough or if it’s missing something.
This is the table with the start/finish times and the duration in seconds
This is the (hopefully correct) output table, with the overlapping items. The rightmost two columns contain the overlap in seconds and one of the 4 possible “patterns” of the overlap.