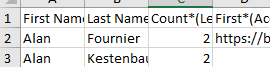
I’m new knime and built a workflow to identify duplicates and incorporate fuzzy match. Since I’ll be running this flow frequently is there a node or way where let’s say for fuzzy match John Doe vs Johnn Doe shows similarities but I have identified them as different people? Is there a way I can keep a record of this and when we rerun the flow it won’t identify the names mentioned above? As a result, I don’t have to re-research them again. The same goes for duplicates if I have I identify them to not be duplicated and re-run the flow I don’t want them showing me it again.