12345678 A
12345678 B
12345678 C
12345678 D
12345678 E
12345678 F
22222222 D
33333333 E
44444444 F
I want a java snippet code for extracting those ucn’s which meets the following condition:
IF UCN is same with attribute A and C the ucn with a attribute will be selected
If ucn is same with attribute B and D then ucn with B attribute will be selected
If ucn is same with attribute C and E then ucn with c attribute will be selected
else if ucn is not same then it will be selected as is.
so we will select ucn with C attribute only when it is not same as any other atrribute, same for attribute D and E.
In above example output will be:
12345678 A
12345678 B
12345678 C
22222222 D
33333333 E
44444444 F
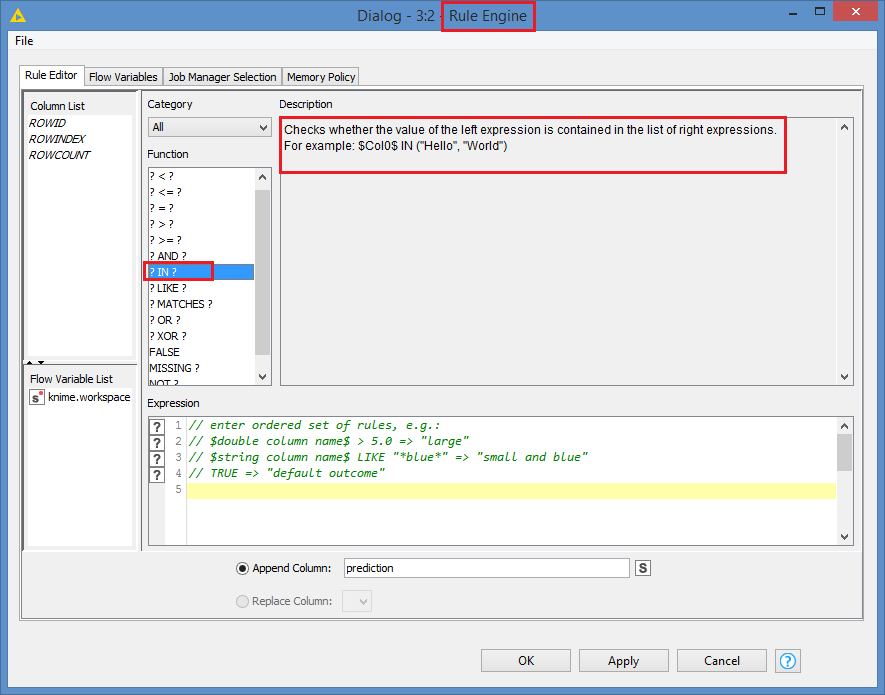
Would we write a java snippet for this? because there is no function like “IN” in knime
Hi @hansa,
Is it correct that you basically look for every row at the row 2 steps ahead? In that case, you can sort your table in reverse so that F is first and A is last (see Sorter node). Then you can use the Lag Column node with a lag step of 2 and count 1 to get the row 2 steps behind. Then you can use the Rule Engine to determine what to output and finally you can sort it back to the original order. Does that make sense?
Kind regards,
Alexander
I am sorry, I can’t understand what you said.
I think you didn’t understand the question!
I need all the ucn in the given data set, only when there is a comparison between 2 similar types of ucn with attribute a and f I will keep the row with ucn with attribute a
and if similarily, same ucn has attribute b and e then I will keep the row with attribute b, similarily same ucn has attribute c and f then I will keep only row with ucn which has attribute c. But I will not completely ignore ucn’s with attribute d,e,f! They will be in the output table if their ucn’s are not duplicated with ucn’s of attributes written above(a,b,c) in that order.
Condition is only when ucn is same, otherwise all ucn’s are extracted.
With “IN” function it can be easily achieved : For e.g. If UCN IN Attribute(A) = UCN IN Attribute(C) then select UCN with Attribute(A).
Is there a similar function in knime or a java snippet code that might help?
I tried column expression but its not meeting the exact criteria, also pivoting didn’t help much.
Hi,
I don’t get it. A, B, and C also have the same UCN, so why are they all included in the output? Is there a difference between the groups A, B, C and D, E, F? You also write
I need all the ucn in the given data set, only when there is a comparison between 2 similar types of ucn with attribute a and f I will keep the row with ucn with attribute a
but below in your example with IN, you compare A and C. In your example in your first post, A and C are still both there, though.
Or can it be formulated like this: “Every attribute must occur in the output exactly once. If there are multiple occurrences, keep the one that has no duplicate UCN.”? I have added a workflow that outputs what you need based on your example, but I am not sure if this is the logic you want.
Alexander
I am sorry!
My mistake in the first example: conditions are:
a UCN with A attribute should not also have D attribute
UCN with B attribute should not also have E attribute
UCN with C attribute should not also have an F attribute
Only except these above condition duplication(of ucn) is allowed, For e.g if a similar UCN has A and B attribute, then both should be kept, comparison is between A and D not A and B in that case.
I hope I am more clear now.
I will attach my workflow as I tried a java snippet code for this condition. testucn.knwf (10.4 KB)
I added a sort before the groupby node to make sure that the Attributes always fell in alphabetical order for the later formulas. It wasn’t necessary for your sample data, but might be for your real life use case.
I’m just not sure how you would use it though. Unless your “IN” is something different? (The one I showed you is quite commonly used as it’s explained in the description. Most DB systems use IN like this also).
Hi,
Please find attached another try at this. Is this what you need? It does not use any Java Script node, to make the workflow easier to understand.
Kind regards,
Alexander
Hii @iCFO Thank you soo much for taking the time to solve this. However I did not quite understand the concept of unpivoting and adding column values to it. I didn’t understand the logic behind it, as we could have simply achieved that from coulmn expression and rule based row filter, do you mind explaining that part?
The unpivoting was to take the list of row level “counter” values and pivot them back down into a column so that they could be included in the join. Using the Counter Generation node for unique ID and pivoting it back to match the left side of the join enables the join to only match up values that fall at the same row level. There are always several ways to accomplish the same task in KNIME. This was just my first instinct on a quick solution build.
I tend to “overbuild” things for safety sake. The row level match up was mostly a safety precaution in this situation to ensure proper alignment / error avoidance at the join. It also allows for easier sorting post join. The rule based row filter just removed missing values from the row “counter”.
I am probably a much heavier user of the “Counter Generation” node for temporary process IDs than most users. Feel free to delete it out if you think it is excessive.
There was also no need to split the Unique concatenate(Attribute) column either. I could have just as easily used a contains expression or regex matcher to check for letters within the same column. Seeing all of the different approaches are what I love so much about this forum!
For my part, I’m still not understanding what the rules are…
I mean for the newer rules:
a UCN with A attribute should not also have D attribute
UCN with B attribute should not also have E attribute
UCN with C attribute should not also have an F attribute
So… what’s supposed to happen in these cases? For #1 for example, does this mean we take attribute A? If not, then which attribute to take?
Does this also mean that we have 6 rules instead of 3?
I hope this does not turn into the other case where we spent over 120 posts just to clarify the rules before coming up with a solution - and then, after the thread the closed since it was solved, the requester came back with more added rules…