Hello,
I have been trying to create a workflow that does image classification through transfer learning using the Kaggle dataset malignant vs benign skin cancer classification. Link: Skin Cancer: Malignant vs. Benign | Kaggle
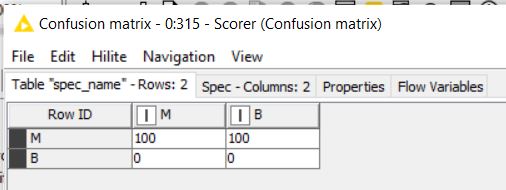
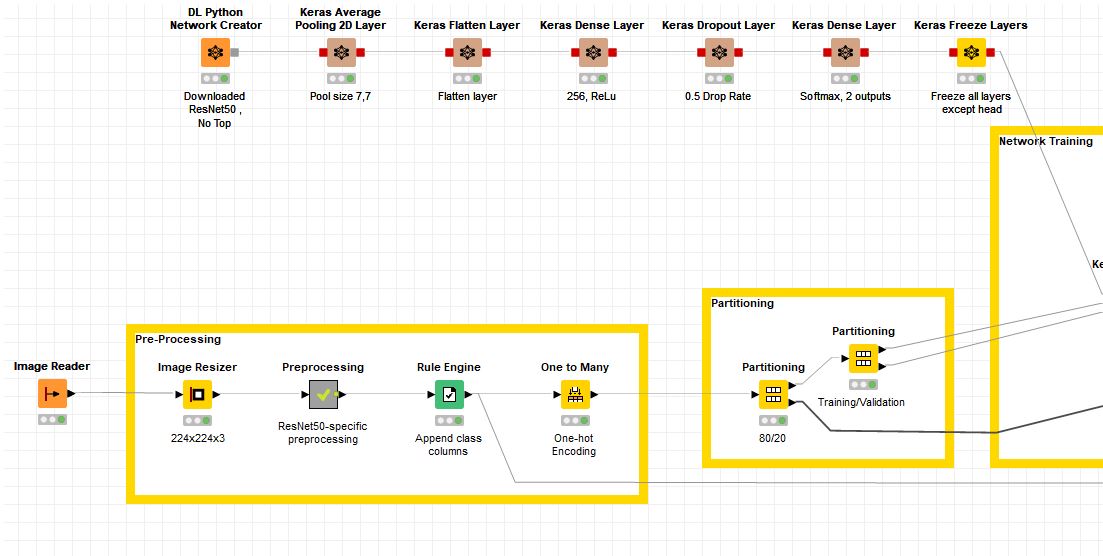
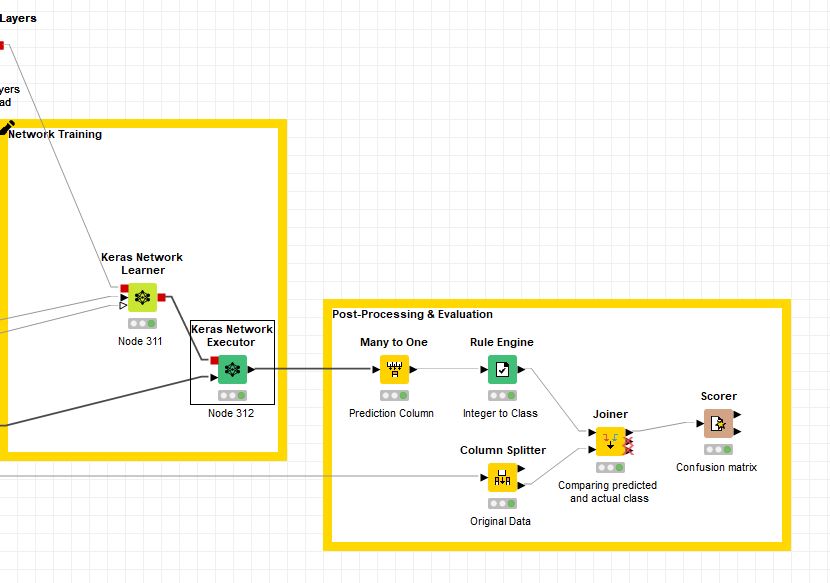
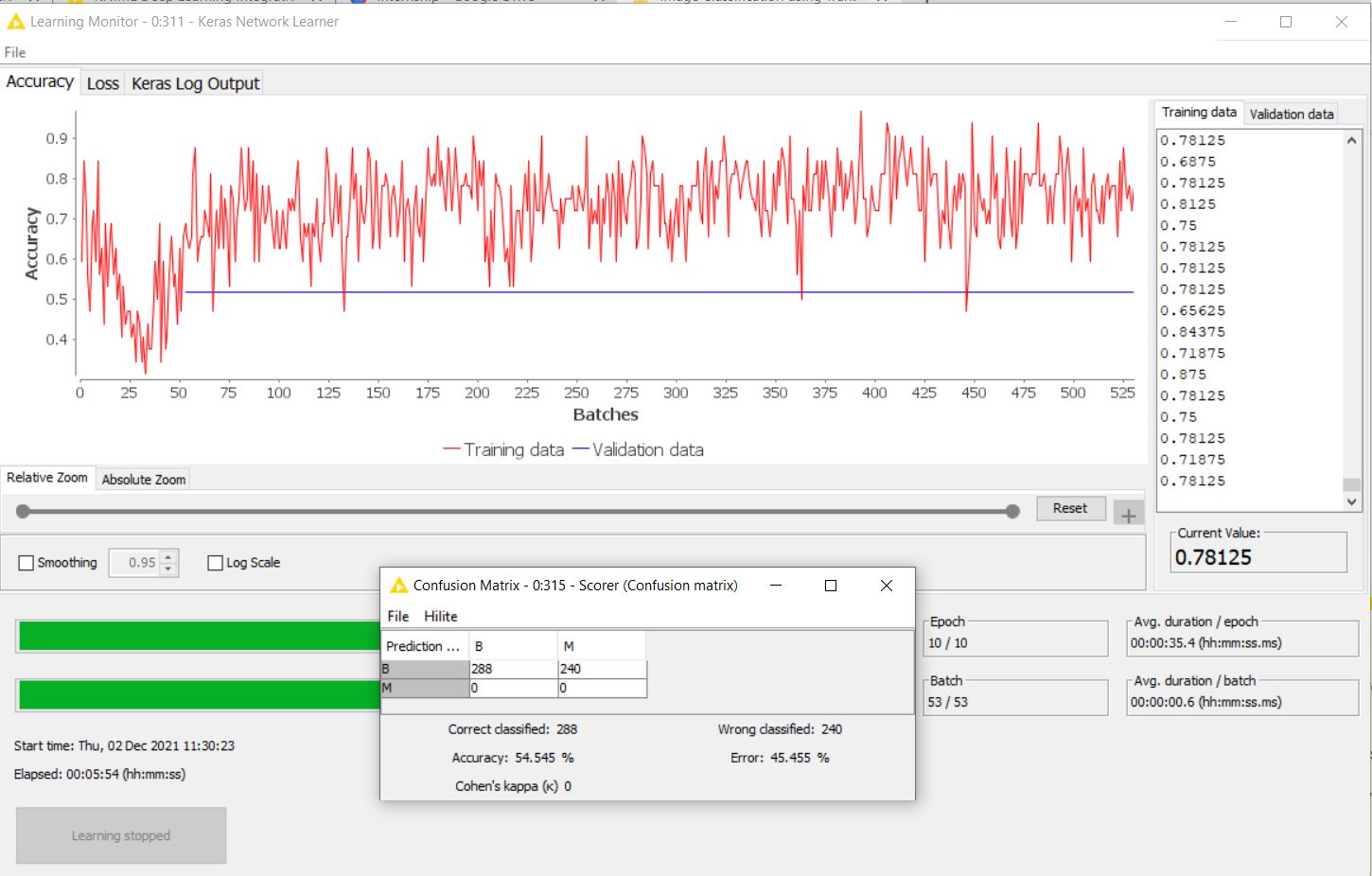
I used ResNet50 and did not include the top, added some Keras layer nodes instead and could use the Keras Network Learner and Network Executor Node. However, the confusion matrix output shows that every picture in the test set is classified only as one class (malignant) and the Learning monitor looks slightly off as well. I used 1000 images, equal classes, and partitioned them using stratified sampling. The DL Network also posed no issues.
Welcome to the KNIME Forum!
In the learning monitor, it looks like there are first all examples of one class and later all examples of the second class. Maybe the model refuses to learn to output the second class after it learned for some time that everything is of the first class. Could you try to shuffle the training data? The “Keras Network Learner” has an option to shuffle the data before each epoch.
Thank you! That did help and I also fixed another error I found at the Image Reader where I should’ve specified the pixel type as FLOATTYPE instead of the other options. The learning monitor now looks a lot more like what I expected,
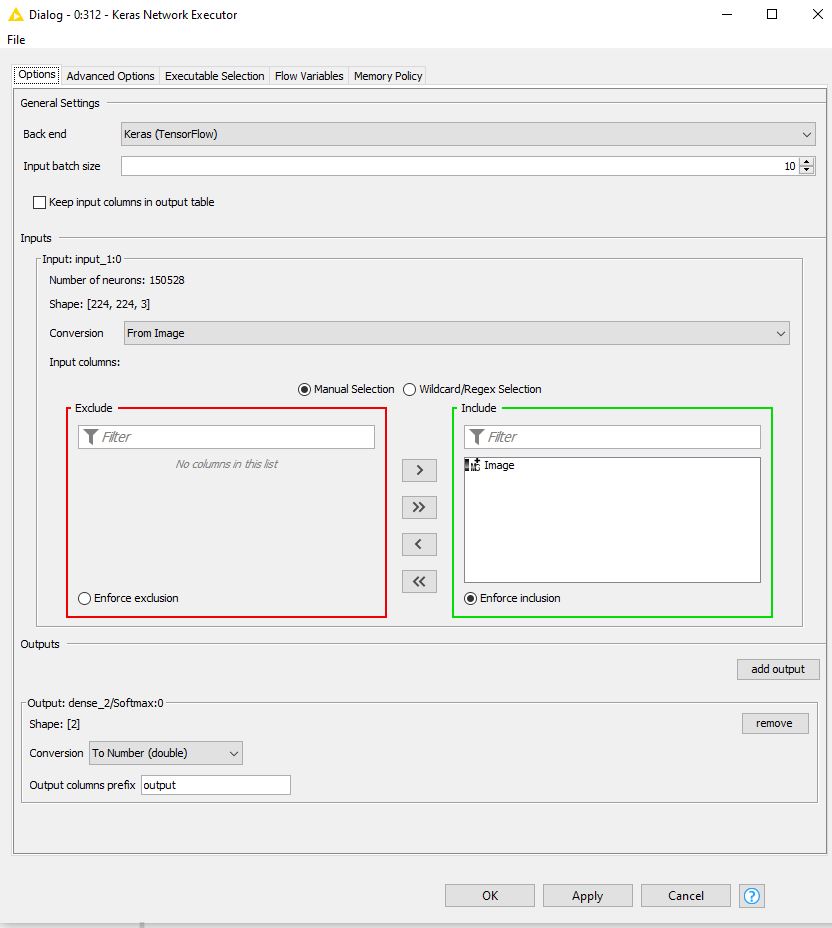
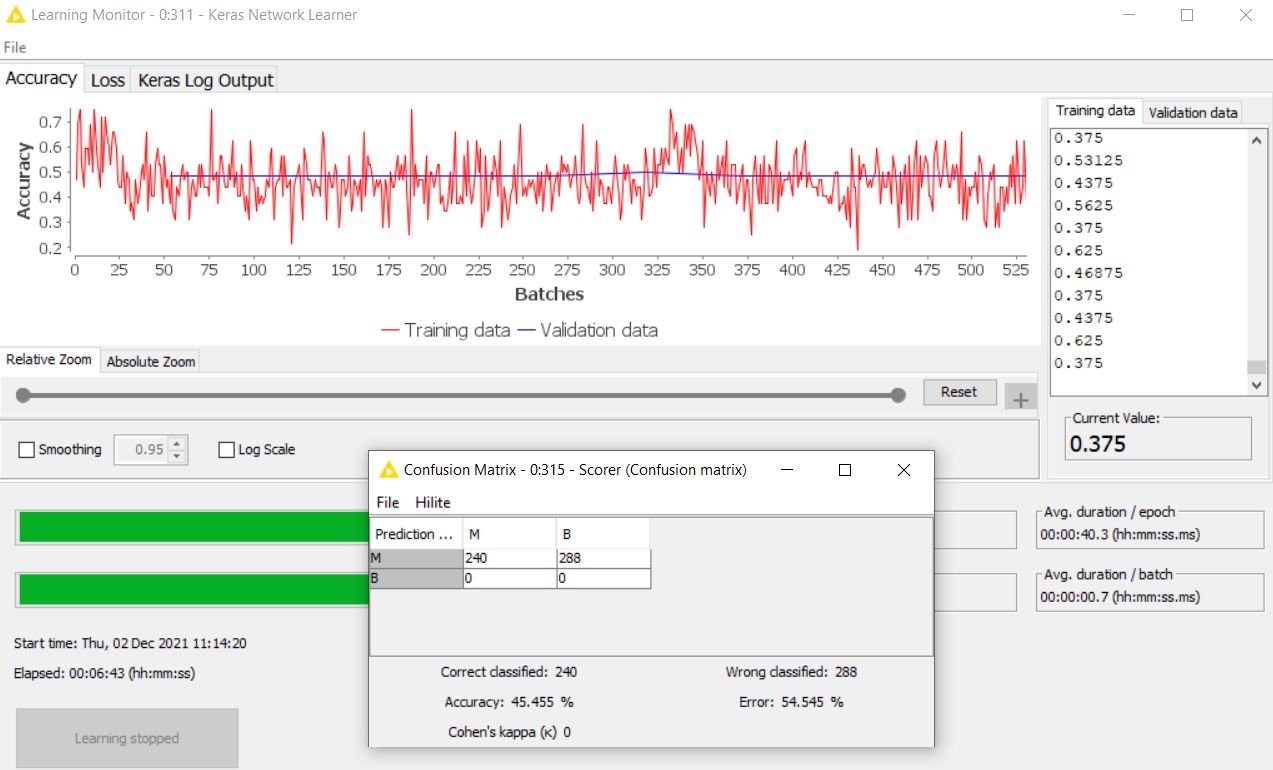
However, the confusion matrix still shows that all the images are classified as one class only. Is there anything else I might be doing wrong? Below is the configuration I have for the executor, the batch size is a bit low due to the lack of computational power of my current device.
It does not look like your model is leaning anything. I have the following ideas:
Could the normalization of the image values be wrong? If you use pre-trained weights the normalization should fit. Otherwise normalizing between 0 and 1 usually works fine.
Do you use pre-trained weights? They could help to speed up the training but they could also hinder training if the features are not useful for the task (especially if they are not fine-tuned).
I was using the ResNet50 preprocessing node that I got from the workflow "Preprocessing (ResNet50-specific). Whether I included this node or not it seems that the output is still the same, the accuracy is always in that 50-60% range. The same goes for the normalizer, placing it in makes no difference.
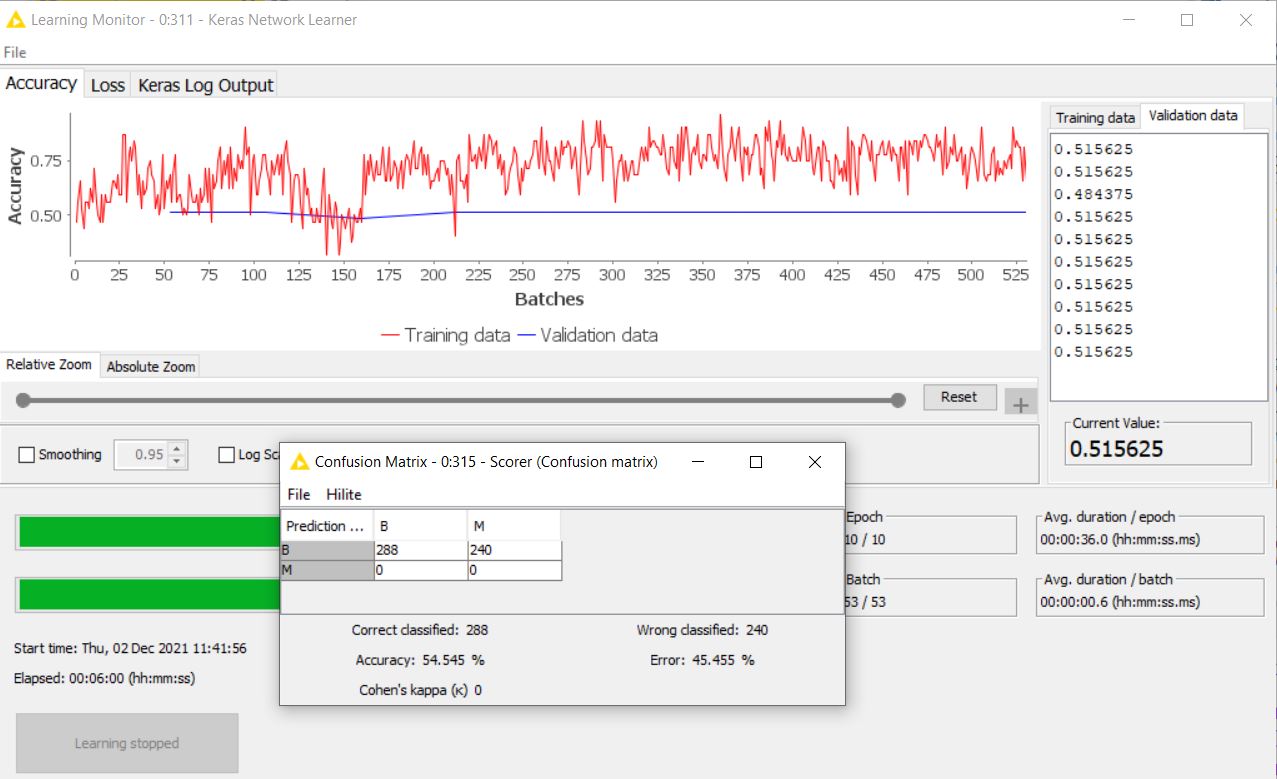
I do notice that now it seems like the validation acc/loss does not get much improvement… I am currently using a bigger data set with 2600 images now, so I’m not sure why its happening. The training acc/loss seems fine…
Sorry for the late reply.
The training loss looks better now. I remember some problems with freezing the batch normalization layers when fine-tuning a ResNet. The training would work but the batch-norm layers would end up with wrong weights and the validation/testing would not work. Note the “Keras Freeze Layers” node in this example on the hub (ignore the name of the workflow).
Hi, do you mean for me to freeze all the ResNet50 layers or only the non-batch norm ones? Often times I receive a OOM Error message when playing with the freezing layers, so that’s where my confusion lies.