Dear Krimmer’s,
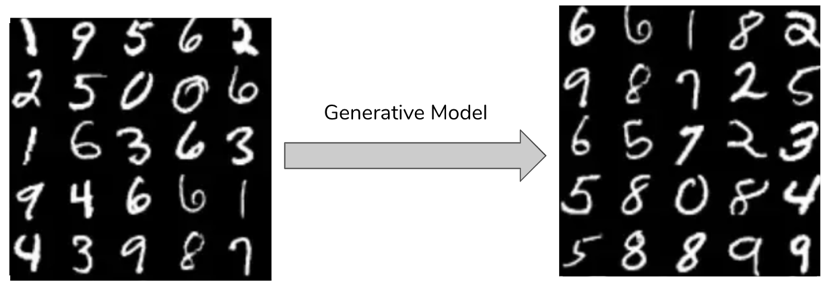
I want to implement a Generative Adversarial Networks (GAN) with MNIST data set. Handwritten numbers and their labels are included in this dataset. Typically, MNIST images are 28x28 grey-scale images that are labeled with integer values from 0 to 9, which correspond to the actual value in the image. It is provided in Pytorch as 28*28 matrices containing numbers ranging from 0 to 255. There are 60000 images and labels in the training data set and 10000 images and labels in the test data set.
Dear @emilio_s ,
Thanks for your grate work flow, I have a MNIST data set data set and I could not understand how to feed it in the workflow. would you please revert your feedback?
I have already extract and save it in the csv format, but it seems to me that it would not correct format for feeding
import torch
from torchvision import datasets, transforms
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm, trange
import time
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
###############################################################################################################
# Define the data transformation
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
print("Step 1: Downloading and loading the data...")
##############################################################################################################
# Load the MNIST training dataset
trainset = datasets.MNIST('data', train=True, download=True, transform=transform)
# Create a dataloader for the training dataset
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
# Load the MNIST test dataset
testset = datasets.MNIST('data', train=False, download=True, transform=transform)
# Create a dataloader for the test dataset
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=True)
print("Data loaded successfully.")
################################################################################################################
# Save the data into a CSV file (Its for my personal analysis)
train_df = pd.DataFrame(trainset.data.view(-1, 784).numpy(), columns=['pixel{}'.format(i) for i in range(784)])
train_df.insert(0, 'label', trainset.targets)
train_df.to_csv('CSV_data/train.csv', index=False)
test_df = pd.DataFrame(testset.data.view(-1, 784).numpy(), columns=['pixel{}'.format(i) for i in range(784)])
test_df.insert(0, 'label', testset.targets)
test_df.to_csv('CSV_data/test.csv', index=False)
print("Data saved to CSV files successfully.")