I do have one question. More statistics than how to use KNIME.
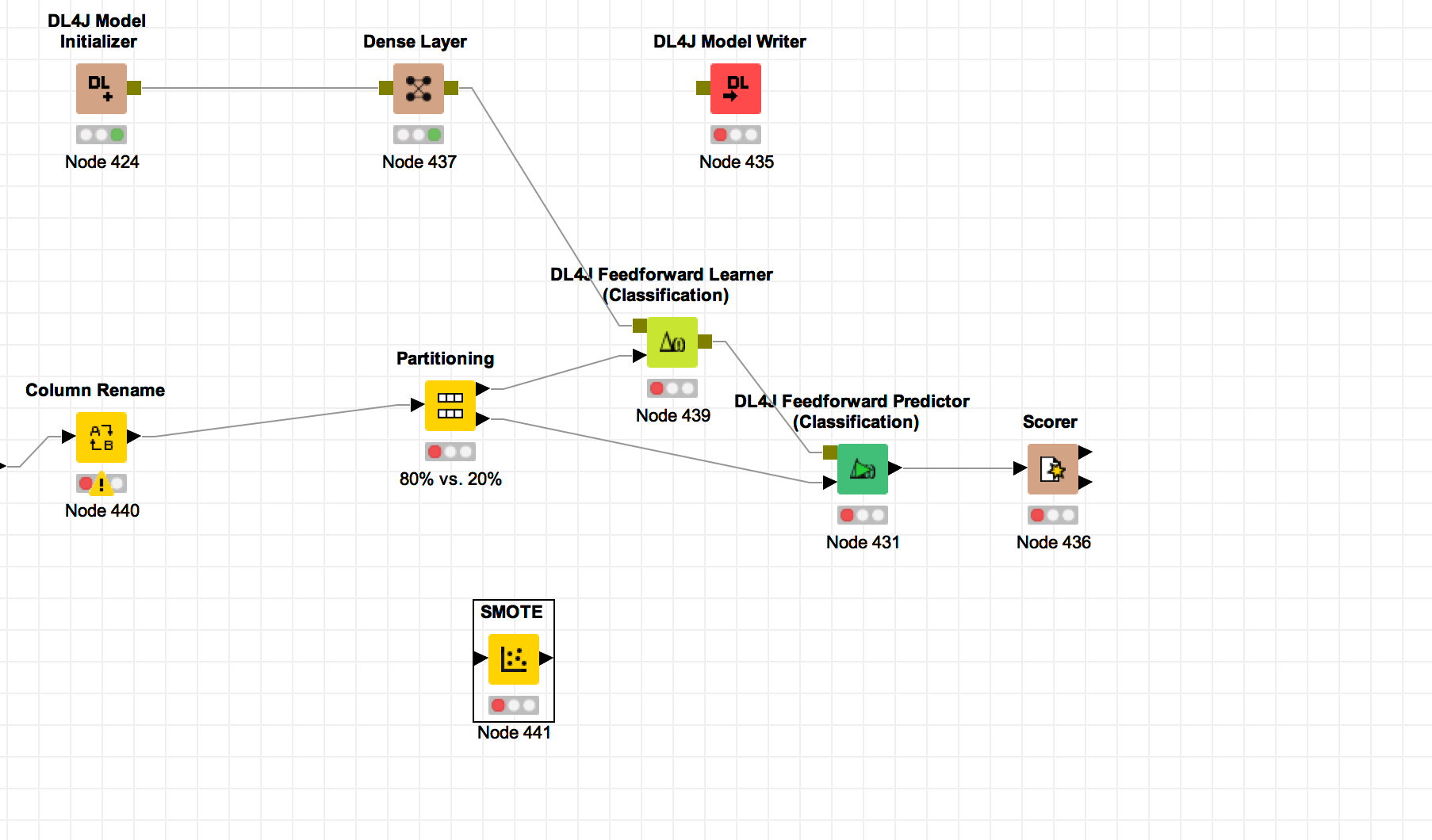
I have some data with lots of rows … maybe 62,000 rows but may only have about 913 rows that have a dependent variable (class = 1). Rest of the data have class = 0.
When I use deep learning training and test model I can get a very good model with accuracy of about 90 percent … BUT the models look at the data and cleverly decide that the best thing to do is to always predict “Class-1” and achieve high accuracy.
Problem is that when I use a subset (with maybe 16 dependent (with class = 1) the all 16 come out with a prediction of 0.
All actual class 1 come come out with a 0 for a prediction and thus all have a false negative result.
I have been doing some research and maybe I need to use the Equal Size Sampling node such as in the 50.18.01 churn prediction example?
Can you suggest anything else if you have a very large data set but only a few rows (10-15%) with very few rows where Class = 1. Other 85-90% of the rows have class = 0.
Thank you for any suggestions.
- Note I have tried the SMOTE node but it did not result in a better prediction model … or maybe I did not set it up right!!!
Where does the SMOTE node go … before or after partitioning?
- Also, I have looked at: This blogpost is a pretty good guideline when it comes to handling unbalanced class data: https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
The below is exactly what is happening?!?!?!
Model has good % when put everything on 0 but then 182 are predicted wrong?!?
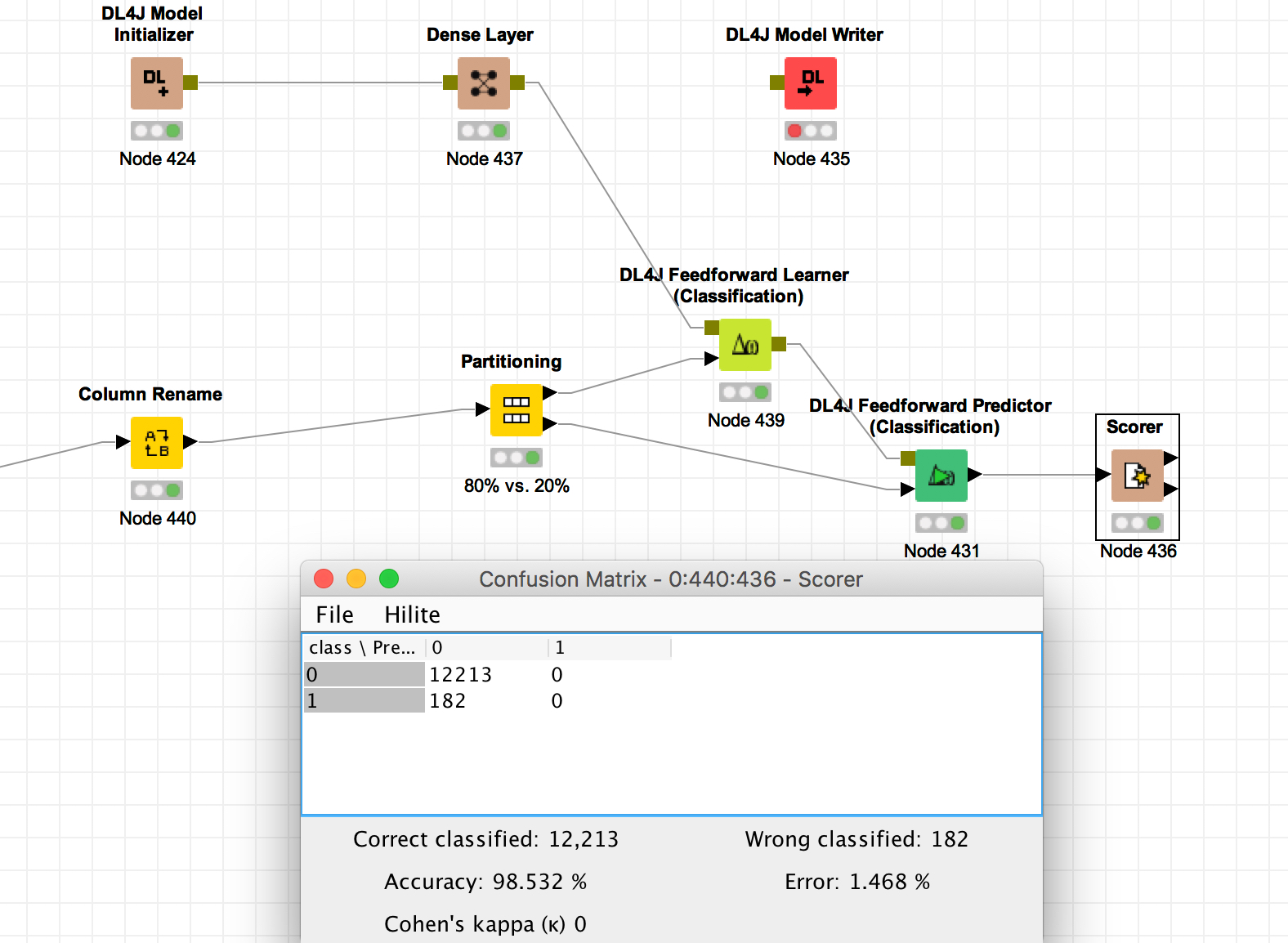
Put it All On Red!
What is going on in our models when we train on an imbalanced dataset?
As you might have guessed, the reason we get 90% accuracy on an imbalanced data (with 90% of the instances in Class-1) is because our models look at the data and cleverly decide that the best thing to do is to always predict “Class-1” and achieve high accuracy.
This is best seen when using a simple rule based algorithm. If you print out the rule in the final model you will see that it is very likely predicting one class regardless of the data it is asked to predict.