Hi,
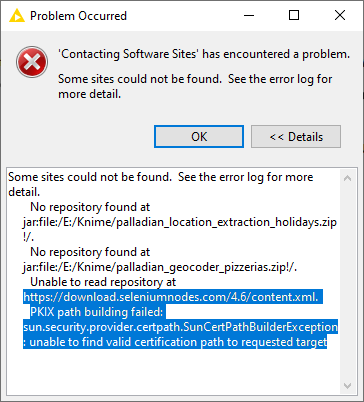
I have KNIME 4.6.3 and I’m not able to install Selenium node as it’s describde on Selenium Nodes — Download.
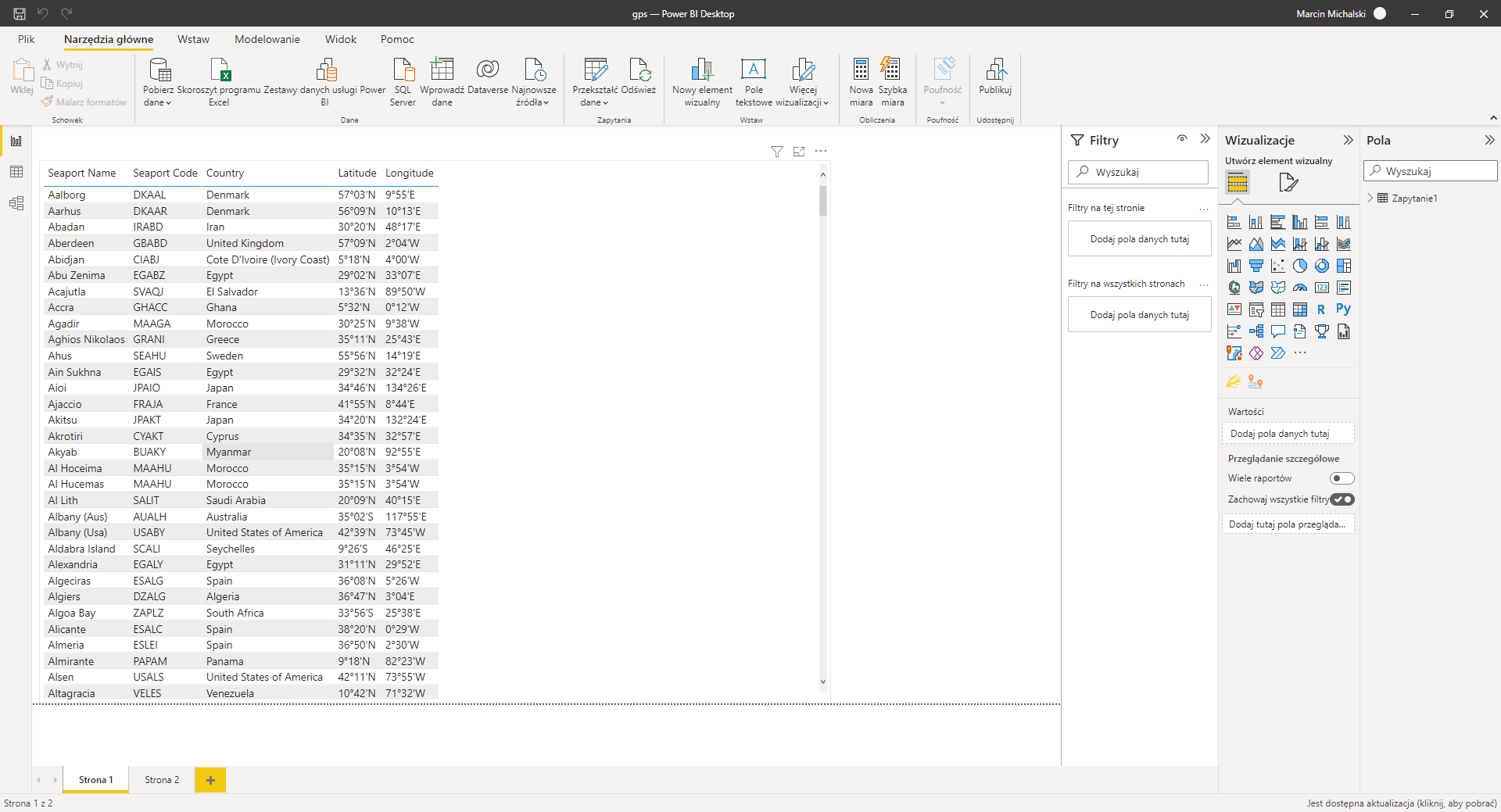
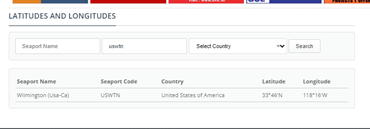
I need to import tables form GCC Ports.
I did it in Power BI but I need to do the same in Knime.
Hi,
I can’t close this topic.
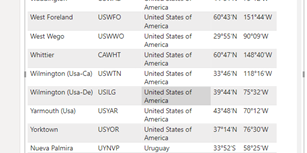
On the site www.gccports.com there are doubled information which I removed.
There is another problem. I am not able to receive all the information which I received in Power BI
The main overview page is selective in what it shows and thus not complete. Hence you’re missing records.
I would suggest starting an outer loop based on the search parameters that you can pass along in the url and then a dynamic inner loop to go through all the pages.
These are the parameters from the search whereby c is the country id and per_page is the page number. For example:
Hi,
I have encountered another problem.
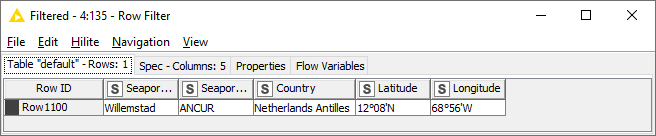
I have created table containing all country numbers.
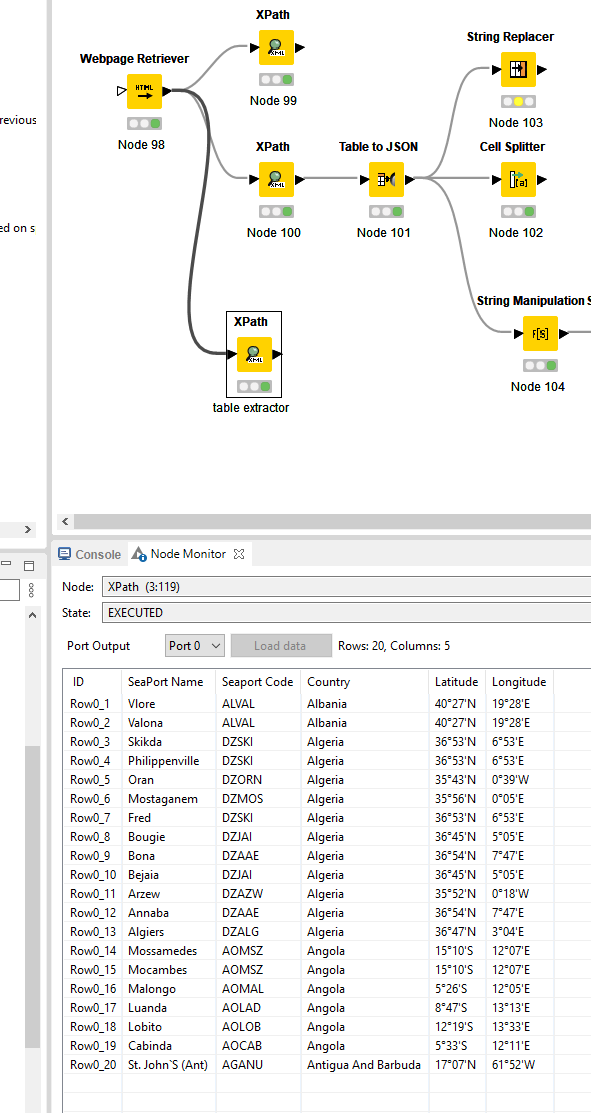
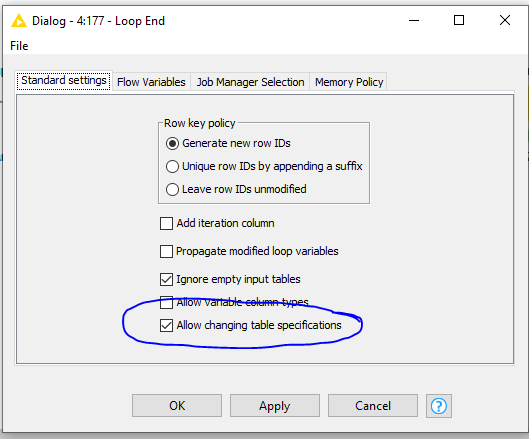
During functioning Loop node I encounter problem “Execute failed: Input table’s structure differs from reference (first iteration) table: Column 6 [body (Binary object)] vs. [body (String)]”.
In the vast majority of cases this can be solved with this option in the loop end. And otherwise some more manipulation within the loop to normalize whenever it exits the loop.
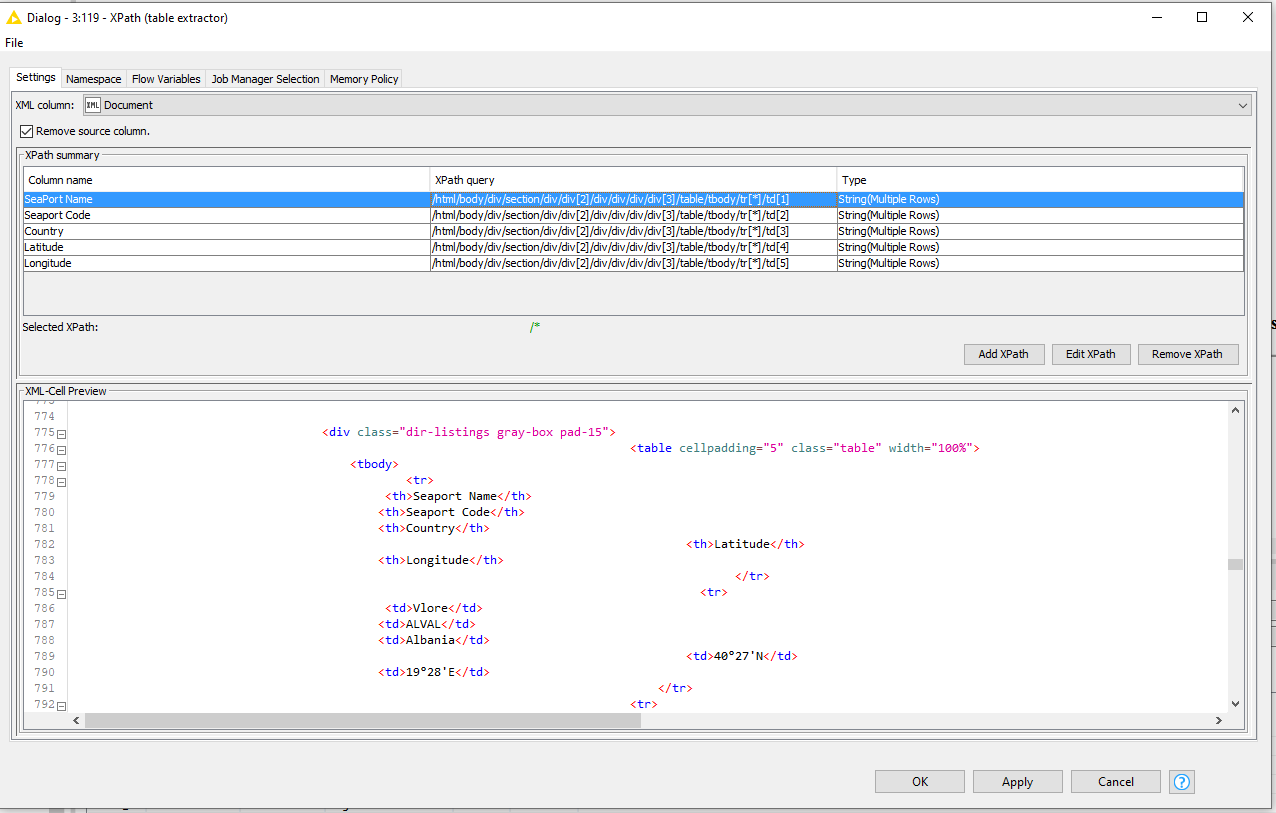
I had a look at your workflow and it’s running quite inefficient. Mainly because your grouping and use of loops is a bit off which makes it extract the page each port 98 times while the most number of pages I found is 9.
Moreover, the GET request and the webpage retriever both do the same and are therefore not both required.