When exporting a sharepoint (cloud) list to excel, I have checked that some values of a specific field, in text format, do not cross with another table that contains a field with the same values. I cross with both Knime and Excel. I have verified by entering directly to the sharepoint list, that the values that Knime is unable to cross have a space prior to the text. I think that this space is automatically generated in Sharepoint by copying the value from another application instead of writing it manually. This space is not seen in the excel download. The curious thing is that if we enter in the cell excel that contains the value and we position at the beginning of the text string and then click once the scroll key to the right we do not advance. When clicking a second time we pass the first character of the text string.
I understand that it is some kind of blank space not visible. I have tried to treat it with different nodes (String Manipulation, String Replacer) and options, but without success.
I attach an example.JOIN TROUBLE.xlsx (10.0 KB)
.
This example will solve your problem:
2 Likes
Great!
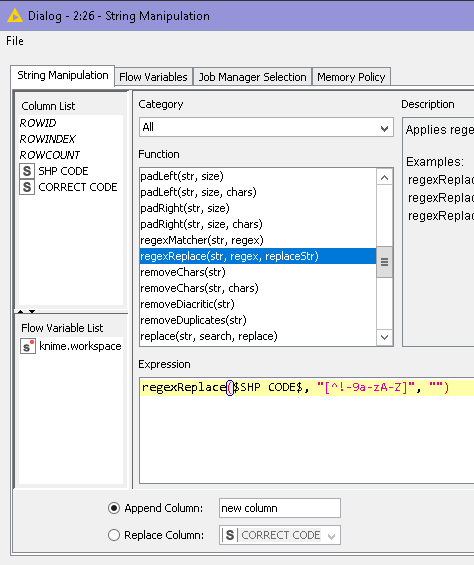
Just about this case as we know the character is “prior to the text” and it’s not a real space, I would prefer to add caret “^” at the beginning of the regex (if we are not sure about the position of the character then we don’t use the caret) and add the space character to the list as well in case we have a real space in the string and we don’t want to remove it.
regexReplace($SHP CODE$, "^[^!-9a-zA-Z ]", "")
In my experience, it is much better to be precise in such cases so that we don’t have any unexpected changes in our data.
Best,
Armin
3 Likes
I don’t know the reason, but it finally worked by adding “^” to the beginning of the expression. I didn’t know the feature of this function. Thank you very much for your help.
The contribution regarding adding “^” was key in solving my problem, Thank you very much!
1 Like
The caret “^” in the brackets is means “not”. But out of the brackets it means “the beginning of the string”.
So the first “^” specify that whatever we are looking for starts from the beginning of the string and the second “^” means any character other than the characters we have mentioned in the brackets.
Best,
Armin
2 Likes