There was a need to process about 75,000 files XML in directories on the local machine.
File sizes from 1 kb to 121 Mb.
From one file can be extracted from one line up to 6.4 million lines.
As a result, the total number of rows in one table was about 225 million lines.
The computer used is a home desktop with the following characteristics:
- AMD Athlon 3000G processor (2 cores, 4 threads)
- RAM 16GB, including 2GB reserved for graphics processing
- no graphics card, all calculations are performed by the processor
- budget motherboard - Gigabyte A520M DS3H
- storage of information on nvme SSD Netac , saving final files on HDD 5400 rpm.
- overclocking of the processor and RAM was not performed
- operating system - Windows .
As you can see, the computer is an ordinary office computer and weak for processing such volumes of data.
On the other hand, no matter how powerful your computer is or a cloud, life always throws up tasks on the verge of the capabilities of existing technology.
And here again the ability to squeeze out of the existing everything possible is relevant.
The task was to: - read files line by line into a table
- process strings (render xml tags and body tags into separate columns, as well as display names in separate columns parameters xml and their meanings).
Purpose: Prepare an array of data from xml for machine learning.
What problems needed to be solved on a low-performance computer:
- process an array of several hundred million rows
- avoid crashes due to memory overflow
- take away some computer resources from Knime, so that without freezes and slowdowns allow you to perform at the computer other work while processing data in Knime.
Now the story of how this was achieved.
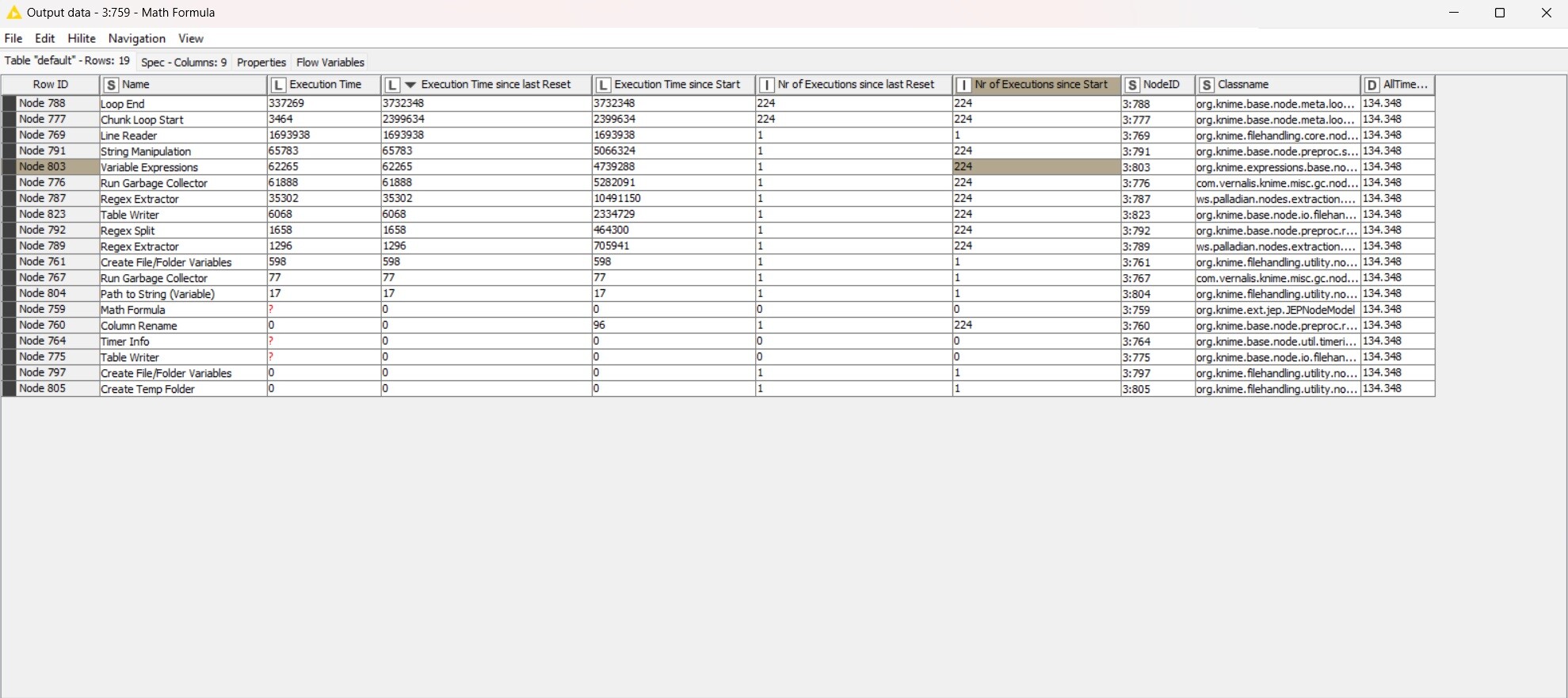
In the picture presented to you, you see the organization workflow in knime-workflow
Manually set directories with source files and a temporary directory for storing results.
When reading files, they are filtered by type and regular expressions applied to path and filenames.
Files are read in the Line Reader node.
Reading and processing of the list of files is carried out in one thread.
File processing line by line is divided into two streams - stream large files (from 1Mb, sorted in descending order) and file stream small size (up to 1Mb, sorted in ascending order).
The file sizes in the two streams are in opposite directions. two streams and multidirectionality gave a performance increase on a single processor more than 2 times compared to single stream processing.
Splitting files into two streams along a 1MB border by me done conditionally on the example of my data. You should try make a split based on the median of the file sizes. The main goal is for multidirectional flows to create a uniform load computer.
Setting Knime Preferences - Maximum Working threads for all nodes on the example of processing about two million rows gives the following layouts of the time spent
3 steps - 1 minute
24 threads - 1.065 minutes
100 threads -0.7 minutes.
In the nodes mode An attempt to enable the Job manager instead of default on streaming resulted in only to worsen performance and lengthen the overall execution time. Apparently the reason is that not all nodes in the line can work in such mode.
In the workflow mode An attempt to include the Table Backend in the Columnar Backend position instead of default only led to performance degradation and lengthening the total execution time. Apparently, the reason is that the Columnar Backend mode is effective in cases where there are many columns and few rows. And my situation is different - in the table there are no more than two tens of columns and hundreds of millions of rows.
Knime.ini parameter
-dknime.compress.io
set to NONE to reduce loss of time for compression of temporary data. 16 GB of memory is already enough.
After reading all the files into the rows of one table, the flow of nodes with large files is looped from nodes the Chunk Loop Start and Loop End , since processing the rows in chunks has shown itself faster than processing one table of 225 million rows in one pass. Win up to about 2x in time.
I recommend trying different chunks on your computers, because chunk reduces the chance of Knime crashing on computers with low memory.
Chunk in 100,000 lines usually yourself justifies, but sometimes chunk in 1 works better million rows, especially on hundreds of millions of rows of data. Apparently because the number of iterations and related operations is reduced.
General guideline when determining chunk size - it is desirable that the loop be executed in several tens of iterations.
If the number of loop iterations reaches several thousand repetitions, then the probability of knocking out Knime increases.
Thus, for millions of rows in the table, is good a chunk of 100,000 rows (with this chunk of 1,000,000 works just as well), but for tables with hundreds of millions of rows - a chunk of 1,000,000 rows is more reliable.
Previously nodes Run Garbage Collector inserted by me on purpose, since their use excluded Knime crashes due to memory overflow. These nodes have already worked on RAM in 16GB and allowed the process to reach the end. successful the process was guaranteed. But it justified itself with examples in millions of lines.
With them, you can on a computer with a running Knime process do other work. With this, Knime can freeze, but do not stop the work, but freezes of the entire computer are rare and brief.
But in examples for hundreds of millions of node lines garbage collection began to lead to regular hangs of K nime and switching between other programs. Apparently, the reason is that node the Run Garbage Collector does not understand very well that there is garbage, but that the temporary data is still needed, and deleted it, because of which K nime wasted computer resources to restore the situation.
Working with nodes Garbage Collector slowed down work process at least 7 times than without them.
In the course of work, the amount of RAM was increased to 80GB. Unfortunately, I did not save the measurements, which resulted in the change performance compared to 16GB. But subjectively, nothing is much better became. Memory Knime still wants more.
A forced heap size limit of up to 8GB has been set (with 16GB memory) and up to 50GB now with 80GB memory. This restriction works constantly. Task Manager Windows also had lowered the priority of the Knime process to “below average”, and in “Set resemblance” reserved for knime only 3 threads out of 4. This limit does not persist across reboots computer. Restrictions are deliberately introduced in order to use the computer without freezes and lags during Knime calculations.
Node The Variable Expression is used to form the names of the weekends files in the loop, inserting the iteration number of the loop into the file name.
Nodes Chunk Loop Start and Loop End take a lot of time time.
Chunk Loop Start seems to be for each chunk creates an empty table for the given number of rows, and then fills it data from the processed table. Seems not very optimal instead of simple cuts from the main table of the desired block.
In node, the Loop End the overall result of the work is glued cycle to the general table. Therefore, it is better to replace it with node the Variable Loop End, since it does not collect the final tables, but only variables.
Earlier, after node the completion cycle, there was a node for writing the result to a file. But at 225 million lines, the size of the final file takes about 8GB and extremely long write times. Therefore, an entry was made result inside the loop into separate smaller files. For further processing it will also have a positive effect on performance.
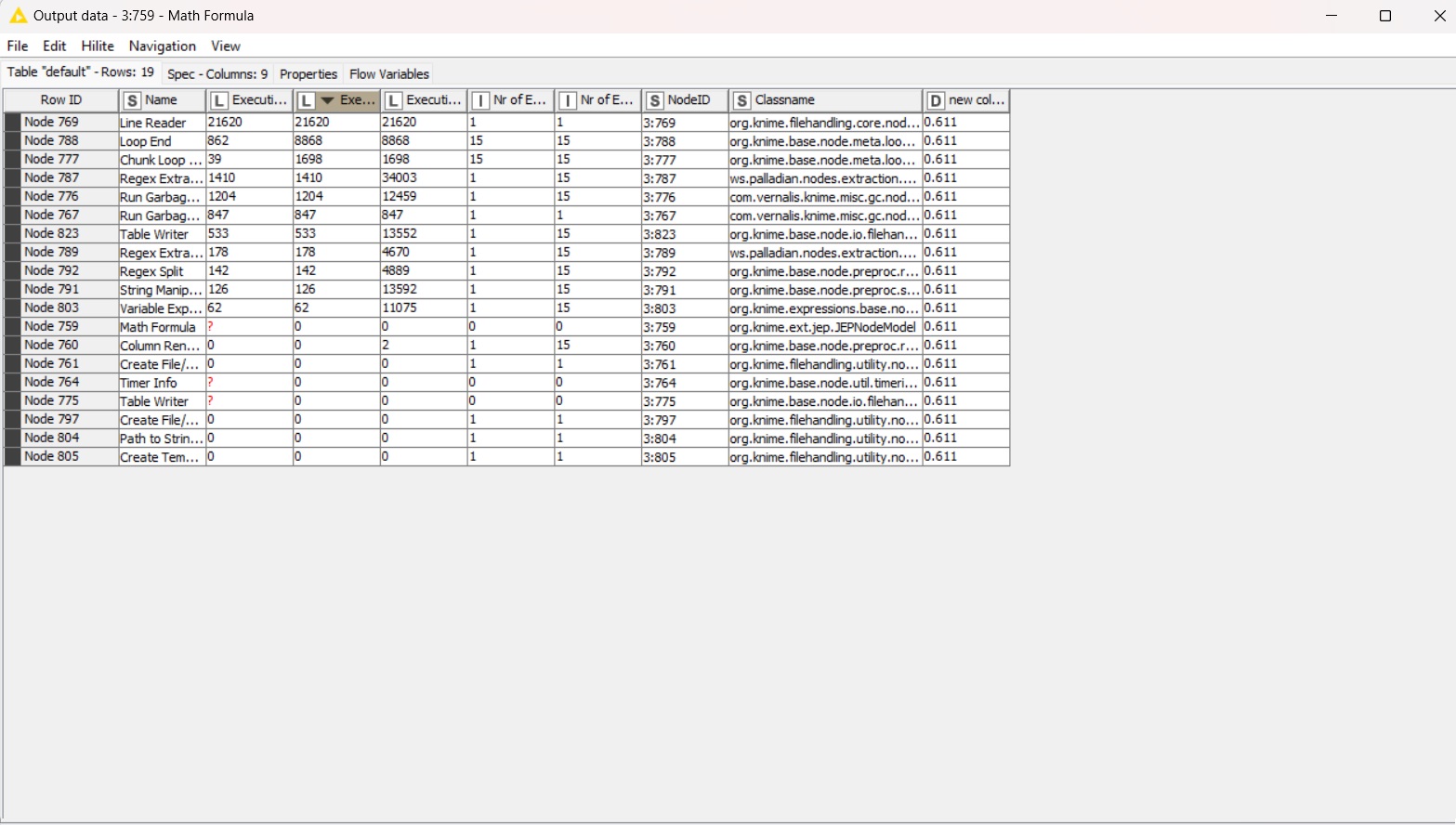
The total processing time of 225 million lines with chunk = 1,000,000 lines takes with the above 11 hours (No! Less! see below). (But it seems that my computer cheated, during a long absence, it went into hibernation and upon awakening, Knime continued as if nothing it happened, but 2 hours must be reduced, a total of 9 hours).
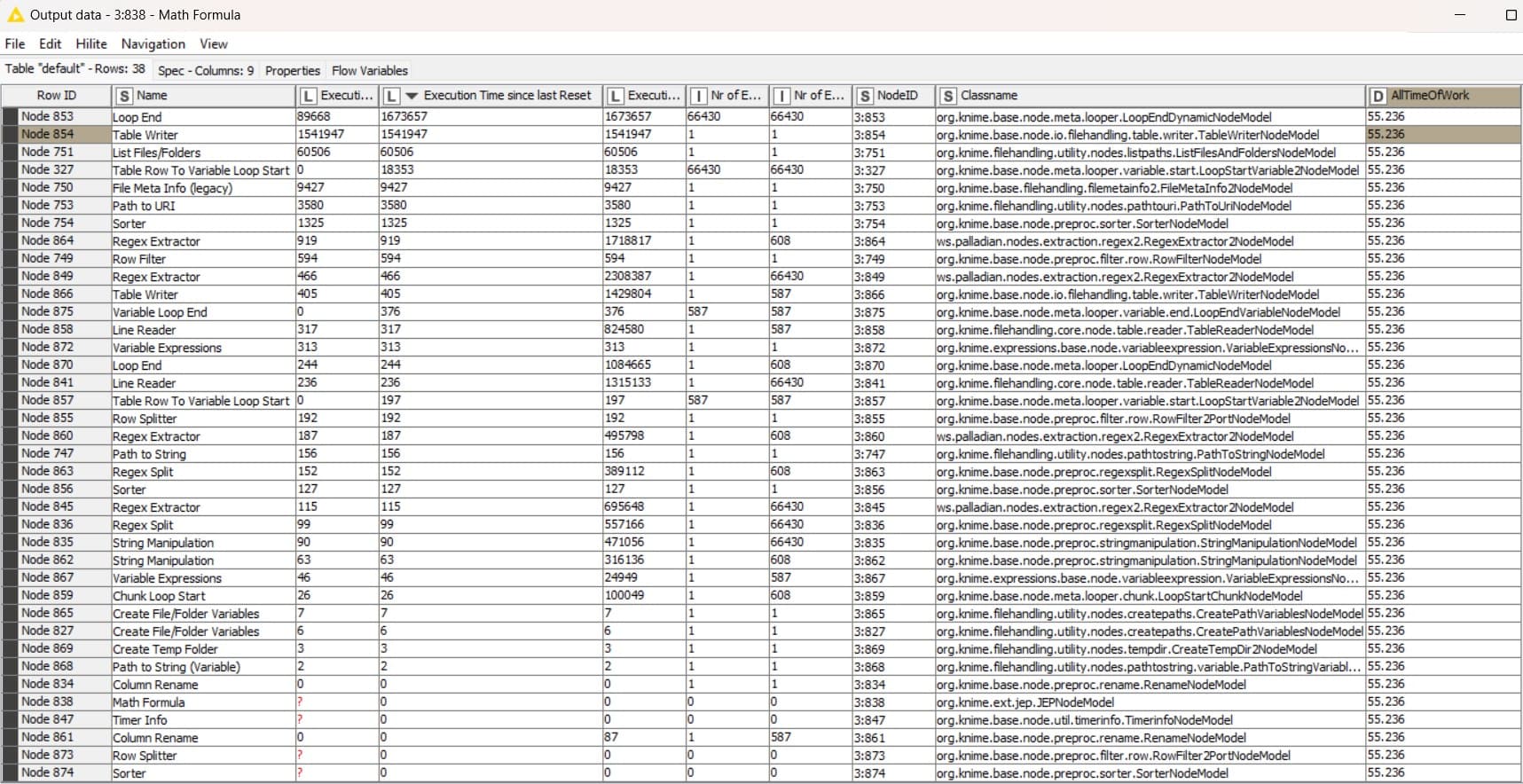
The total processing time is about 2 million lines with chunk = 100,000 lines under the above conditions 0.5 minutes.
The total processing time is about 2 million lines with chunk = 1,000,000 lines takes with the above conditions for 1 minute.
And yes! I found out that Knime sly! It turns out when the computer goes into hibernation (and also, it seems that in sleep) it suspends work. At awakening from hibernation, it instantly starts working and it doesn’t seem to stop.
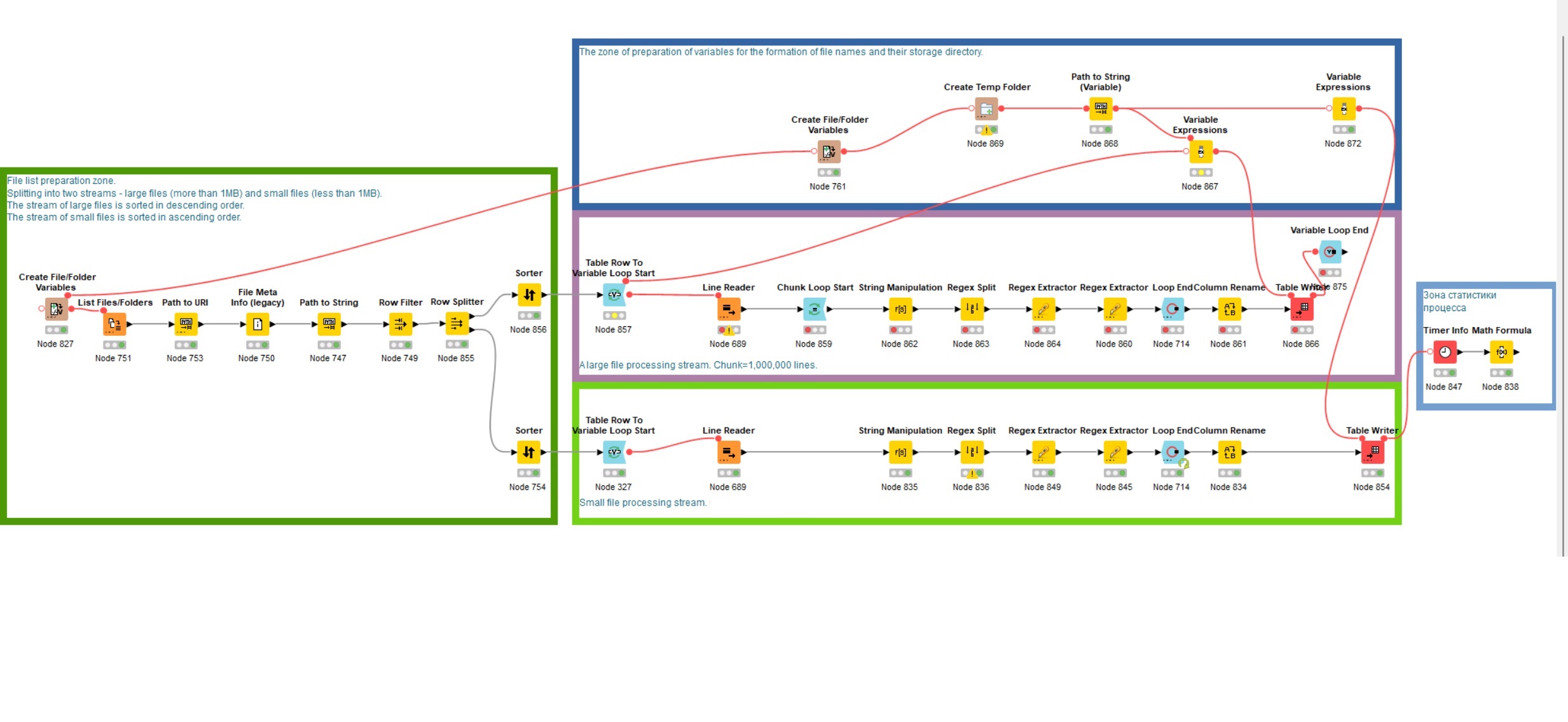
And I wondered where, given the objective time of work at 9-11 hours, K nime statistics showed 4-5 hours of work or less.
Statistics nodes take into account only the time of the actual operation of the node, and not the time from the beginning process.
Process The file of the described Knime , what it turned out to be in the final form , is attached .
Process statistics file for the process Knime also included is a 223M line
There you can see which nodes take up the most time.
As a result, after many attempts and processing options 225 million lines are processed in 2.5 hours (according to Knime measurements, this is 55 minutes).
Knowing what processor I have, you can go to the site Сравнение процессоров or similar and compare with with your processor and benchmarks to estimate in how many times slower or faster your processor will process a similar task.
According to the results of my experience with K nime is more profitable invest in a faster processor than in memory. According to monitoring performance in task manager K nime will eat any memory, even 80GB is not enough for him, so his heap will have to be limited by anyone. But the processor clearly does not keep up with processing even with 16GB of memory.
Memory policy Workflow set to “place in memory”. Attempt set all nodes to “place on disk” It did not give a clear effect and does not particularly affect the overflow of RAM. Writing intermediate output data to disk inside the loop proved to be more efficient.
Practice has shown that writing to the final file of processed results with a file size of more than 1GB (and I got 8GB each) takes an extremely long time. Therefore, if you are going to expose processed data is still further processed, it is better to write to smaller files. Hence the conclusion - chunks should be made in such a way that in a separate file got about 1 million lines, not more. The exact number depends on your computer, the speed of your disk systems.
In the end, I even redid it in the small file processing branch ending the process by fractionally writing the total of the main loop through a loop with chunk .
The whole process is written in Knime without a single line of code. No one python, javuar and R were not affected by this experiment.
Here is such a schedule.
I am new to Knime, first month learning it. I’ll be glad for hints what can be done better in Knime, how to build processes and nodes more efficiently.
I would be especially grateful if someone could tell me how to set up Apache Spark at home local area network under Windows to distribute Knime computing to home computers without a Knime server.
You can quickly contact me in Telegram Telegram: Contact @RomanKlmnsn or in the same chat Telegram: Contact @SPPR_1C
Or write here.
Screenshot with workflow for 2 threads
Statistics on a screenshot with 2 threads
Statistics on 1 thread for 2 million rows and chunk
Statistics on 1 thread for 223 million rows and chunk1 million rows