Hi
I am coming from the SQL world, so maybe my thoughts are a bit specific, maybe even useless, but I like to have a look at the SQL KNIME generates, and it is quite cumbersome. There you are. A very simple flow, a group by and a joiner, results in the following (from exercise 2 of L2-DS).
SELECT "tempTable_3090550887201630965"."id" AS "id","tempTable_3090550887201630965"."name" AS "name","tempTable_3090550887201630965"."host_id" AS "host_id","tempTable_3090550887201630965"."host_name" AS "host_name","tempTable_3090550887201630965"."neighbourhood_group" AS "neighbourhood_group","tempTable_3090550887201630965"."neighbourhood" AS "neighbourhood","tempTable_3090550887201630965"."latitude" AS "latitude","tempTable_3090550887201630965"."longitude" AS "longitude","tempTable_3090550887201630965"."room_type" AS "room_type","tempTable_3090550887201630965"."price" AS "price","tempTable_3090550887201630965"."minimum_nights" AS "minimum_nights","tempTable_3090550887201630965"."number_of_reviews" AS "number_of_reviews","tempTable_3090550887201630965"."last_review" AS "last_review","tempTable_3090550887201630965"."reviews_per_month" AS "reviews_per_month","tempTable_3090550887201630965"."calculated_host_listings_count" AS "calculated_host_listings_count","tempTable_3090550887201630965"."availability_365" AS "availability_365","tempTable_7544618374004094193"."AVG(price)" AS "AVG(price)" FROM (SELECT * FROM "AB_NYC_2019"
) "tempTable_3090550887201630965" JOIN (SELECT "neighbourhood_group", AVG("table_1795039804"."price") AS "AVG(price)" FROM (SELECT * FROM "AB_NYC_2019"
) AS "table_1795039804" GROUP BY "neighbourhood_group"
) "tempTable_7544618374004094193" ON "tempTable_3090550887201630965"."neighbourhood_group"="tempTable_7544618374004094193"."neighbourhood_group"
I can understand that it is spaghetti, as the formatting of code is a point of personal style, even though this is no style at all. Usually, one would employ one’s favourite formatter.
select "tempTable_3090550887201630965"."id" as "id",
"tempTable_3090550887201630965"."name" as "name",
"tempTable_3090550887201630965"."host_id" as "host_id",
"tempTable_3090550887201630965"."host_name" as "host_name",
"tempTable_3090550887201630965"."neighbourhood_group" as "neighbourhood_group",
"tempTable_3090550887201630965"."neighbourhood" as "neighbourhood",
"tempTable_3090550887201630965"."latitude" as "latitude",
"tempTable_3090550887201630965"."longitude" as "longitude",
"tempTable_3090550887201630965"."room_type" as "room_type",
"tempTable_3090550887201630965"."price" as "price",
"tempTable_3090550887201630965"."minimum_nights" as "minimum_nights",
"tempTable_3090550887201630965"."number_of_reviews" as "number_of_reviews",
"tempTable_3090550887201630965"."last_review" as "last_review",
"tempTable_3090550887201630965"."reviews_per_month" as "reviews_per_month",
"tempTable_3090550887201630965"."calculated_host_listings_count" as
"calculated_host_listings_count",
"tempTable_3090550887201630965"."availability_365" as "availability_365",
"tempTable_7544618374004094193"."AVG(price)" as "AVG(price)"
from( select
*
from "AB_NYC_2019") "tempTable_3090550887201630965"
join( select
"neighbourhood_group",
avg("table_1795039804"."price") as "AVG(price)"
from( select
*
from "AB_NYC_2019") as "table_1795039804"
group by "neighbourhood_group") "tempTable_7544618374004094193"
on "tempTable_3090550887201630965"."neighbourhood_group" = "tempTable_7544618374004094193"."neighbourhood_group"
I just think that your query might be quite a bit suboptimal. Derived queries “table_1795039804” and “tempTable_3090550887201630965” are identical. In this case, it does not matter, probably, but if you generate identical queries that have heavy lifting inside (aggregations, filtering where no index is being used, …) I am not sure every database optimiser can recognise them and eliminate double work - and redundancy is harder to read for me at least. In my world, those identical queries are not uncommon, thinking of dimension tables being joined to fact tables to, e.g., translate well modelled identifiers with their literal meaning.
I also detected inconsistent use of “as” while aliasing queries - take a look at afore mentioned derived queries. I prefer to have it concise and have hardly ever come across aliasing queries with “as” whereas aliasing attribute names always with it. I am not sure whether it infringed SQL standard not to use “as” in the latter case.
Secondly, I quite understand that the with-construct is not used, suspecting that not every database supports it, and I have been working with people that could not read queries with the with-construct well. I totally do not understand why, but there we are, and after all, I heard about databases sometimes creating a suboptimal execution plan when too many with-constructs were involved. I have a hard time to believe that, though, but I reckon using derived queries can well be the way to go.
select "tempTable_3090550887201630965"."id" as "id",
"tempTable_3090550887201630965"."name" as "name",
"tempTable_3090550887201630965"."host_id" as "host_id",
"tempTable_3090550887201630965"."host_name" as "host_name",
"tempTable_3090550887201630965"."neighbourhood_group" as "neighbourhood_group",
"tempTable_3090550887201630965"."neighbourhood" as "neighbourhood",
"tempTable_3090550887201630965"."latitude" as "latitude",
"tempTable_3090550887201630965"."longitude" as "longitude",
"tempTable_3090550887201630965"."room_type" as "room_type",
"tempTable_3090550887201630965"."price" as "price",
"tempTable_3090550887201630965"."minimum_nights" as "minimum_nights",
"tempTable_3090550887201630965"."number_of_reviews" as "number_of_reviews",
"tempTable_3090550887201630965"."last_review" as "last_review",
"tempTable_3090550887201630965"."reviews_per_month" as "reviews_per_month",
"tempTable_3090550887201630965"."calculated_host_listings_count" as
"calculated_host_listings_count",
"tempTable_3090550887201630965"."availability_365" as "availability_365",
"tempTable_7544618374004094193"."AVG(price)" as "AVG(price)"
from "tempTable_3090550887201630965"
inner join "tempTable_7544618374004094193" -- I am just fond of explicity
on "tempTable_3090550887201630965"."neighbourhood_group" = "tempTable_7544618374004094193"."neighbourhood_group"
Last and the initial point of complaint, if I may say so, is that while I believe that aliases might have constraints applied to their name length, this kind of generation makes it very difficult to make out which part of the query is derived from which node of the flow. I really would welcome if the node label was generated as comment to it.
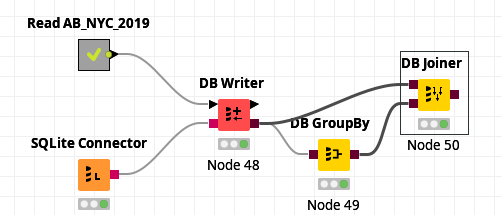
with "tempTable_3090550887201630965" /* Node 48 */ as (select *
from "AB_NYC_2019")
, "tempTable_7544618374004094193" /* Node 49 */ as ( select "neighbourhood_group",
avg("tempTable_3090550887201630965"."price") as "AVG(price)"
from "tempTable_3090550887201630965" /* */
group by "neighbourhood_group")
select "tempTable_3090550887201630965"."id" as "id",
"tempTable_3090550887201630965"."name" as "name",
"tempTable_3090550887201630965"."host_id" as "host_id",
"tempTable_3090550887201630965"."host_name" as "host_name",
"tempTable_3090550887201630965"."neighbourhood_group" as "neighbourhood_group",
"tempTable_3090550887201630965"."neighbourhood" as "neighbourhood",
"tempTable_3090550887201630965"."latitude" as "latitude",
"tempTable_3090550887201630965"."longitude" as "longitude",
"tempTable_3090550887201630965"."room_type" as "room_type",
"tempTable_3090550887201630965"."price" as "price",
"tempTable_3090550887201630965"."minimum_nights" as "minimum_nights",
"tempTable_3090550887201630965"."number_of_reviews" as "number_of_reviews",
"tempTable_3090550887201630965"."last_review" as "last_review",
"tempTable_3090550887201630965"."reviews_per_month" as "reviews_per_month",
"tempTable_3090550887201630965"."calculated_host_listings_count" as
"calculated_host_listings_count",
"tempTable_3090550887201630965"."availability_365" as "availability_365",
"tempTable_7544618374004094193"."AVG(price)" as "AVG(price)"
from "tempTable_3090550887201630965" /* Node 48 */
-- adding "inner" because I am just fond of explicity
inner join "tempTable_7544618374004094193" /* Node 49 */
on "tempTable_3090550887201630965"."neighbourhood_group" = "tempTable_7544618374004094193"."neighbourhood_group"
It has become much longer, this post, than I expected, but hope it is not to daring.
Kind regards
Thiemo