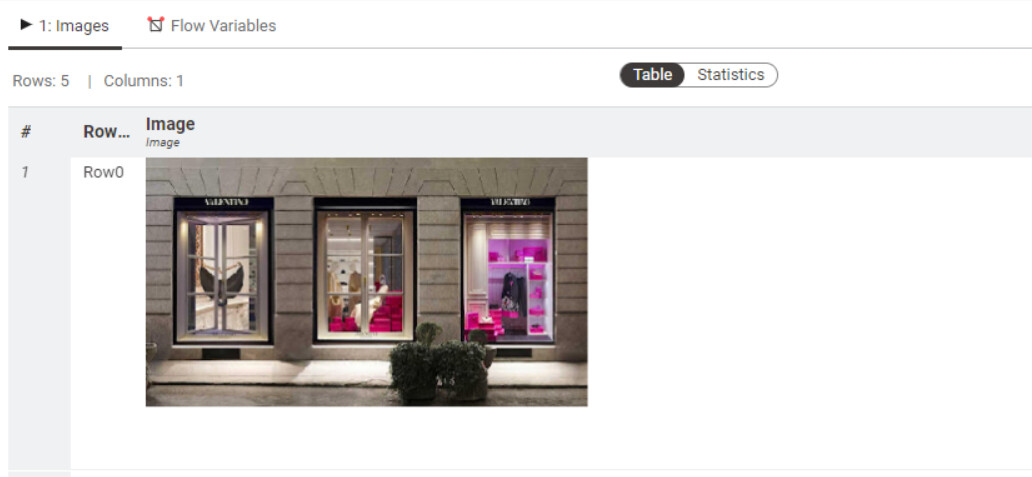
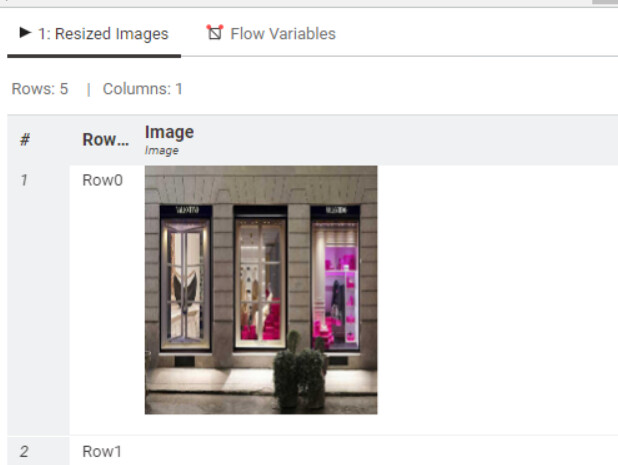
Hi, I want to thank you for the suggestions and your help. I haven’t had time to look at these proposals yet because my research has focused on how to create a CNN model with images of different sizes without having to resize the images.
One proposed solution i have founded was to create a model by specifying the dimensions of the images like this:
1 - Change Flatten to GlobalMaxPool2D
2- Change input shape to (None, None, channels) - repeat None according to the number of image dimensions and the number of channels is mandatory.
So my model is as follows:
variable name of the output network: output_network
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, GlobalAveragePooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
"Create the model
model = Sequential()
model.add(Conv2D(3, (3, 3), activation="relu", input_shape=(None, None, 3)))
model.add(Conv2D(32, (3, 3), activation="relu"))
model.add(Conv2D(16, (3, 3), activation="relu"))
model.add(Conv2D(8, (3, 3), activation="relu"))
#Replace Flatten with GlobalMaxPooling2D
model.add(GlobalAveragePooling2D())
#Add the output layer with softmax activation
model.add(Dense(2, activation="softmax"))
output_network = model
The node executes correctly.
However, things get complicated at the DL python Learner node level, especially when manipulating the data.
Here is some code that I took from one of your workflows and I tried to adapt to my case :
steps = 50
epochs = 25
image_column = input_table['Image']
x_train = []
for i, img in enumerate(image_column):
img_array = img.array
img_array = np.transpose(img_array, (1, 2, 0))
x_train.append(img_array)
x_train = np.array(x_train)
y_train = input_table['ClassIndex']
y_train = np.array(y_train)
y_train_encoded = to_categorical(y_train, num_classes=2)
# I comment this, to test if it's work without
#train_datagen = ImageDataGenerator(shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
#gen = train_datagen.flow(x_train, y_train)
input_network.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
input_network.fit(x_train, y_train_encoded, epochs=epochs)
# Output
output_network = input_network
So after execution the Learner Node I have got this error
Error when checking input: expected conv2d_1_input to have 4 dimensions, but got array with shape (11, 3).'
I’ve tried manipulating the data in every way possible to get the right format, whether by adding a column or specifying each dimension of the image. But handling numpy arrays, especially on Knime, is complicated for me.
I’m not sure if it’s possible to apply this method with Knime, I had hope when the node executed at a certain point. But then my workflow crashed without able to save it.
So I lost the code that seemed to work and I’m unable to reproduce it, so many manipulations have been made.
I would like to know your opinion on the matter, maybe you know how to train the model.
Thank you very much.