I’ve checked various counter nodes - but I’m afraid I’m still a monkey playing with sticks here.
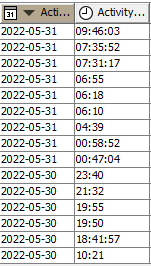
I have a subset of data that looks like this:
There is a column not shown here that holds FedEx tracking numbers. For this subset, the tracking number is the same.
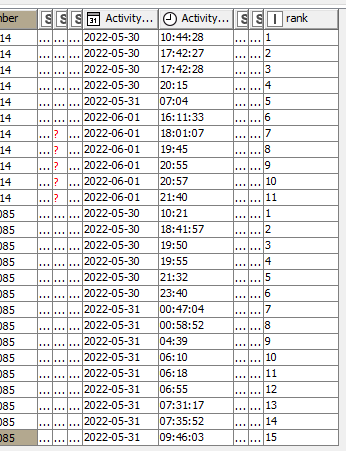
I’d like to be able to count these from 1 for the earliest date and time, up to the last available row before the tracking number (i.e., the 3rd row), changes. In this case, these rows would be counted from 1 to 15, at which point the next row would be a different tracking number and thus would start again from 1.
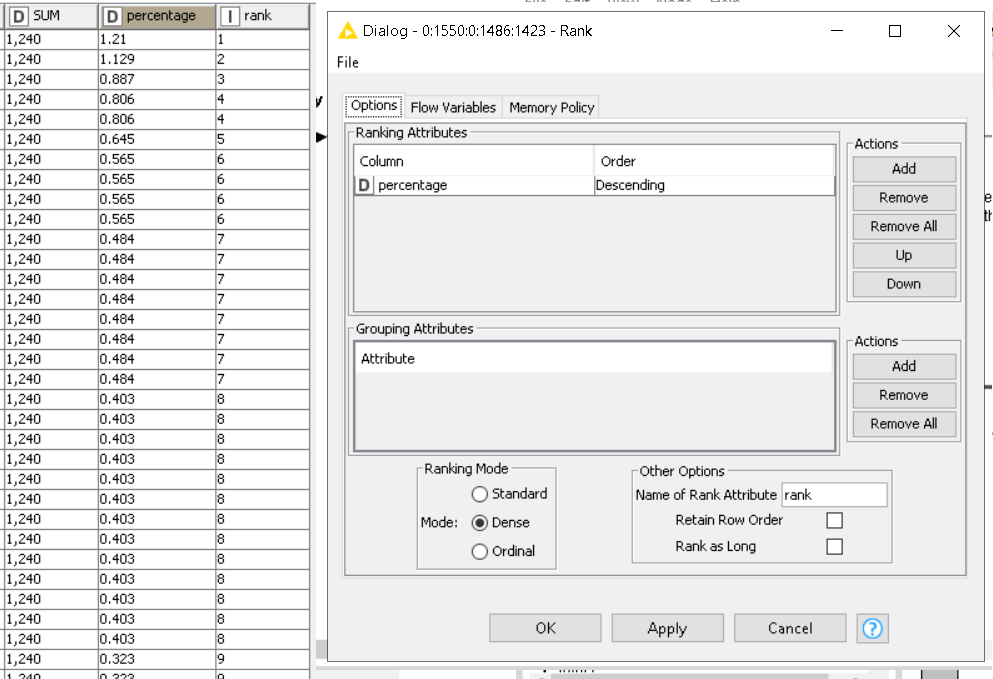
Try to count the rows within a Group Loop. Where the column with FedEx tracking numbers creates the group. Or do it in just one node with the Rank node.
gr. Hans
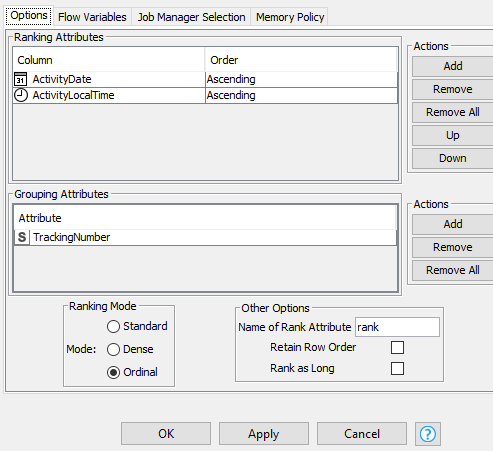
The Rank node worked well using Activity Date and Activity Time as Ascending Ranking Attributes, respectively, Tracking Number as the Grouping Attribute, followed by an Ordinal Ranking Mode.