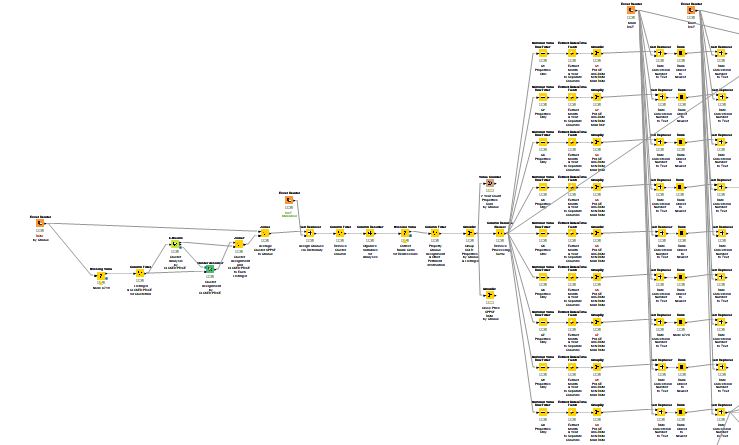
I have a system that creates 9 groups of aggregated data from a single table–so I can further define specific values for each of those 9 groups based on months&years. Works great.
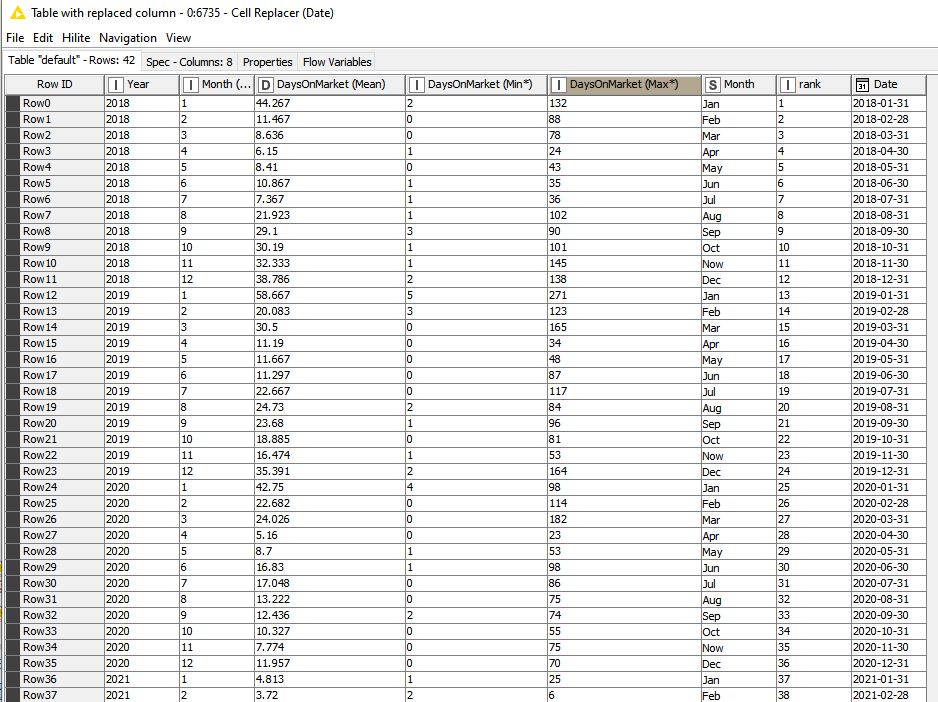
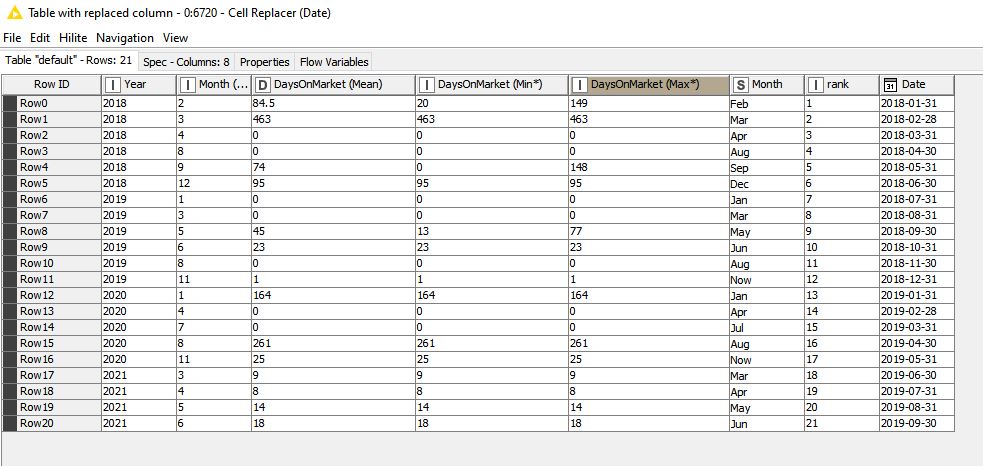
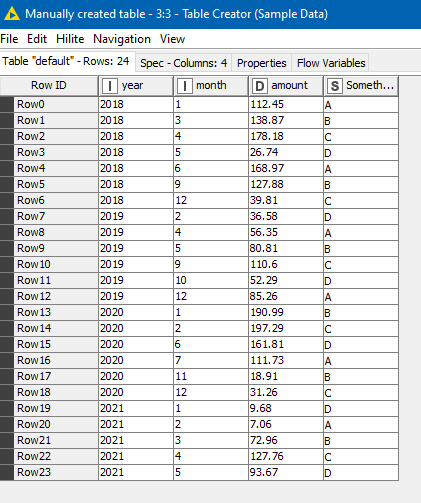
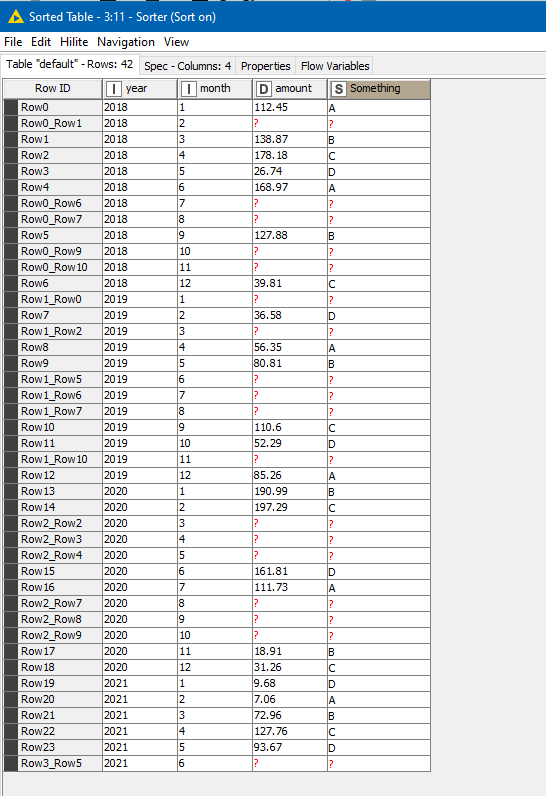
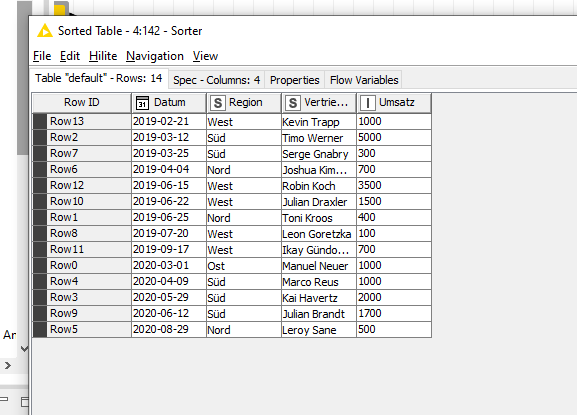
My problem lies in some of the 9 groups not having data for particular months&years, such as seen below. The current max rows are 42, with some data sets having only half that number of rows–since there was no data for the progressive months&years.
What I want to do is “force” all 9 output tables to have the same number of rows (in this example 42) and column headers–within the tables coming up short on months&years blank. But the added rows must be in chronological order, not simply appended at the end of the table using node “add empty rows”. I can then use a node to either use prior values or averaged values to replace the blank data cells within the inserted chronological rows.
I need to force all 9 tables to have the same number of rows and columns and column headers, with any of the 9 sets coming up short of the current maximum of 42 “auto populating” missing rows in the order based on months&years as you see in the output tables.
Hi @smithcreed , if I’m understanding your problem correctly, you have data for years and months (one row per year-month). Some of the months are missing and you need to insert rows for just the missing months.
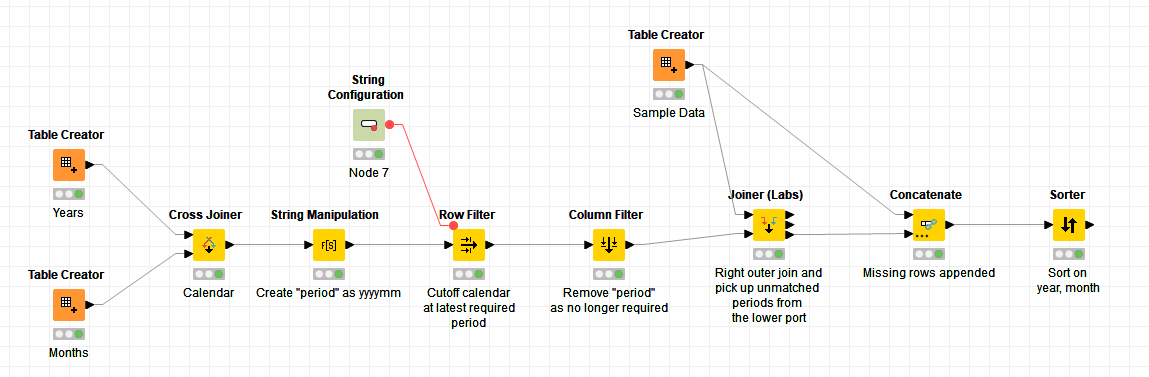
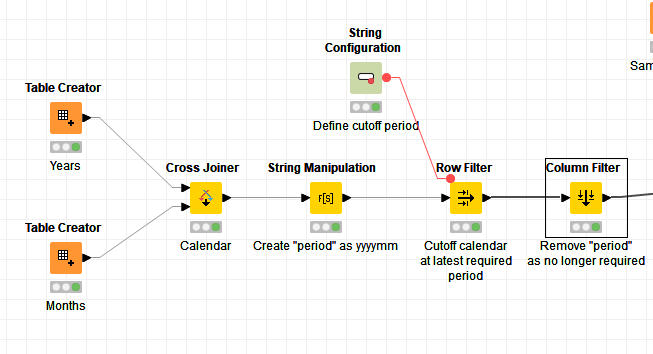
Here I’ve just hand coded a couple of “seed” tables. One for year and the other for months.
These initial tables could be generated, but for this it seems simpler to just provide the initial years.
A cross join gives all months for all years.
I assumed there was some sort of cutoff that would be determined, so I’ve just included that as a manual cutoff but this data could be fed from maybe a “max” derived from your data.
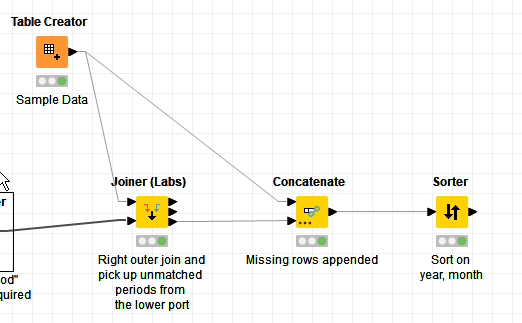
After that, the Joiner (Labs) node is used to join the data to the calendar. Unlike the regular Joiner node, this gives the ability to return us just the rows from the calendar that don’t match, and this data set of “missing periods” is then concatenated with the sample data (you’ll want to make sure the column names for “year” and “month” exactly match those from your data), and then it’s sorted on year,month.
Hi @creedsmtih, You are welcome, and I hope it works for you.
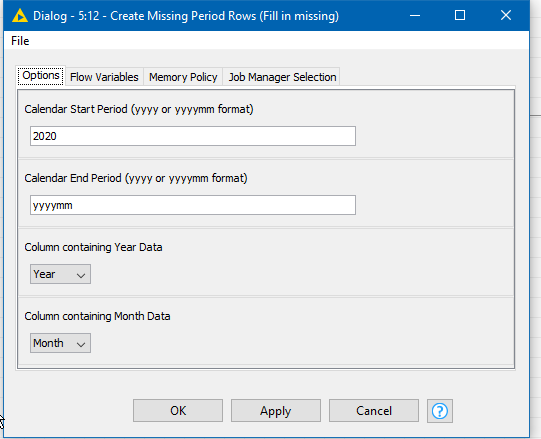
This was one of those cases where I could see a use for a generic solution for in-filling missing periods, or even for creating a “period calendar”, so I packaged the above into a component.
If you are interested, you can find it here, where you can drop it into your workflow, configure the required period and columns (see the help doc on the component)
It is available here, and any feedback or issues, please let me know.
Yes, I adapted your initial solution into my process, removing and/or rearranging my original flow to incorporate your solution, then ended up using node “missing value”/moving average to create data in the table’s empty cells.
I will certainly grab your node and see if it makes things even cleaner.
Just went to look at your new node download–and see 16 downloads already in its first day of existence. So you are correct, the need is certainly there.
Yes, your shiny new node works perfectly, with me getting the exact same results in my end table after replacing the node series below with your single node solution. Nice work!
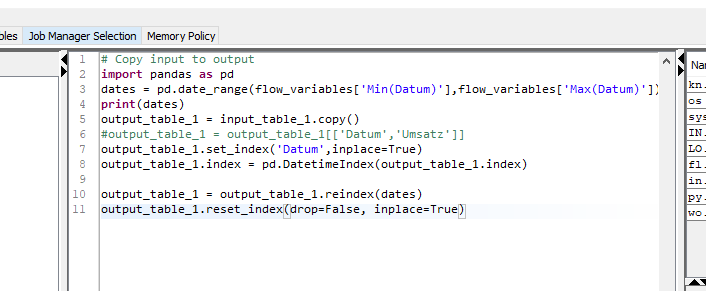
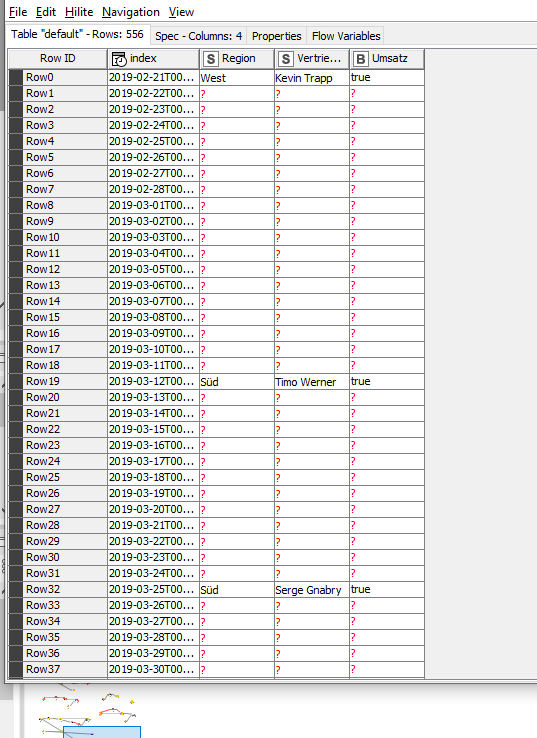
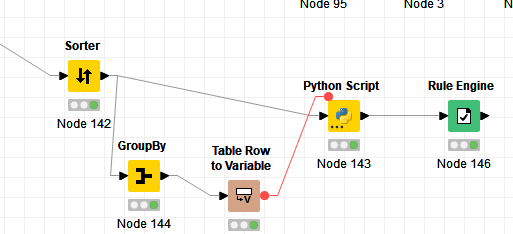
I played around with python and for anyone who looks for a way fill in missing dates in the future and stumbles over this thread might find this helpful too (sorry if I overstepped and misused this topic here)
my flow looked like that.
I’m sure your Python system here will help those smarter than me and know how to actually program . In every situation it’s best to get several options and determine which, or if a combination of multiple options works best. Thanks

 . In every situation it’s best to get several options and determine which, or if a combination of multiple options works best. Thanks
. In every situation it’s best to get several options and determine which, or if a combination of multiple options works best. Thanks