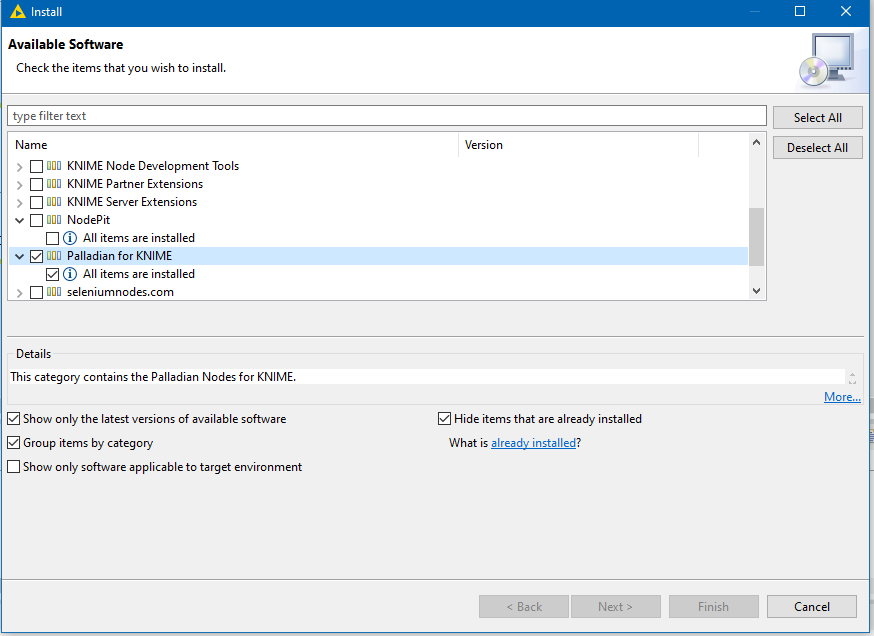
Hi @B074534 , I remember about 5 years ago being presented with a data migration to a new system that required addresses to be practically perfect even though the old system had similar data entry issues that you are facing. The end result was me sitting with a spreadsheet, plus google, painstakingly trying to manually fix (with a little automation) a few thousand records. Luckily it wasn’t more.
The trouble is, that addresses can be typed in so many ways that it is almost impossible to fix perfectly so I am sure you realise the best you can achieve is an improvement in what you already had.
I have been thinking over this for the past day and had thought up one plan involving downloading global town/partial postcode information that I found at geonames.org, with the idea being that if you could determine the country that the address belonged to, you could better gain an understanding of the standard address format for that country and then maybe pull other information out. I actually put together the start of that flow, and it successfully identified the countries for each of your sample addresses, but it was probably going to take a long time to run over a large data set.
So I set about thinking of something more simple that would probably be about the same effectiveness in a greatly reduced timespan.
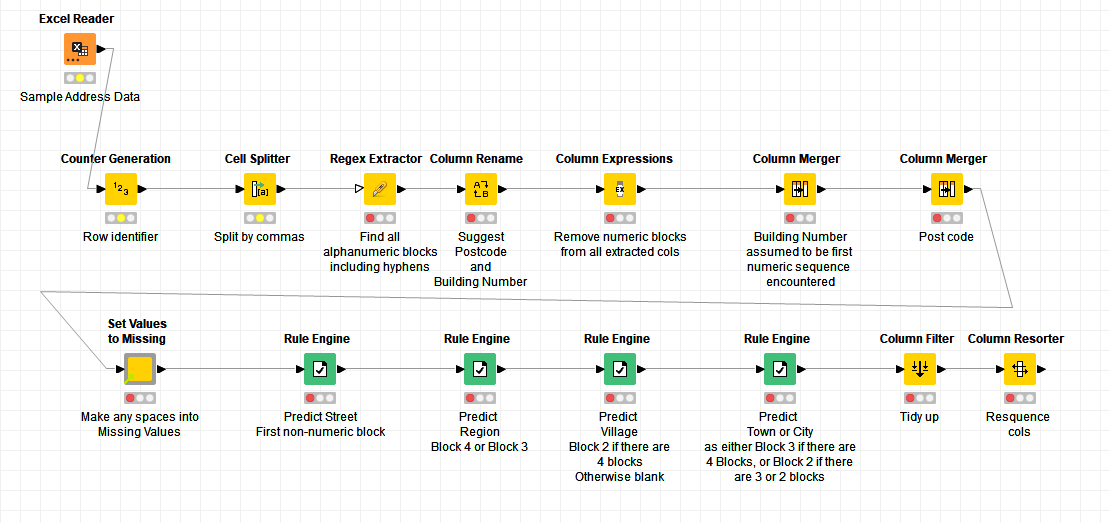
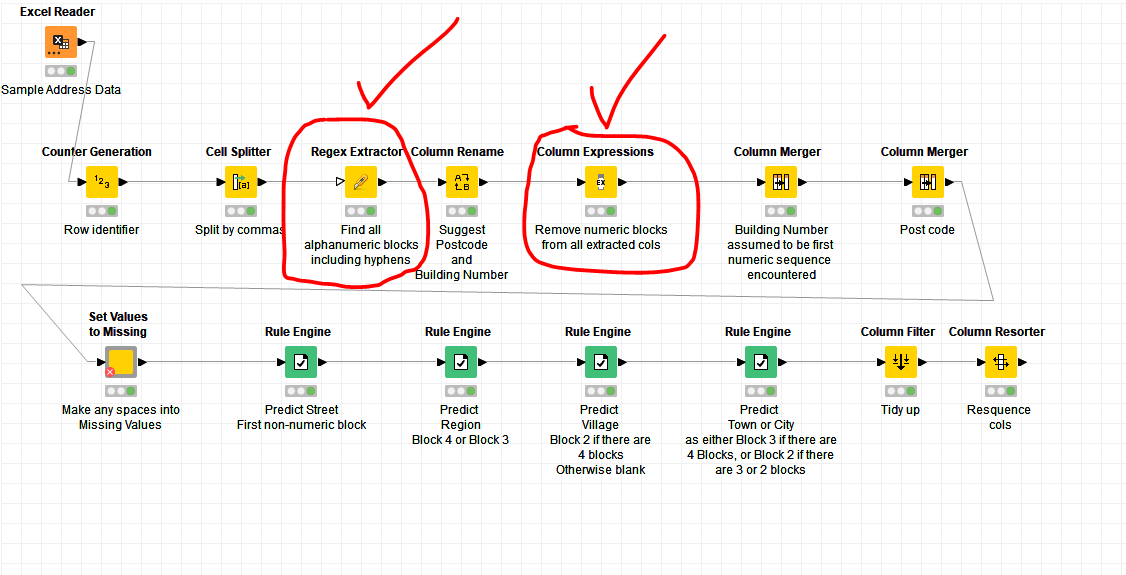
This cannot be perfect, but for a good many cases, looking at a standard street address in whichever format, the first numeric sequence encountered is the building number, and the next numeric encountered is the postcode.
I also assumed that the address will always be divided by commas, but I know that in reality this isn’t always true. I don’t know a good answer to that part.
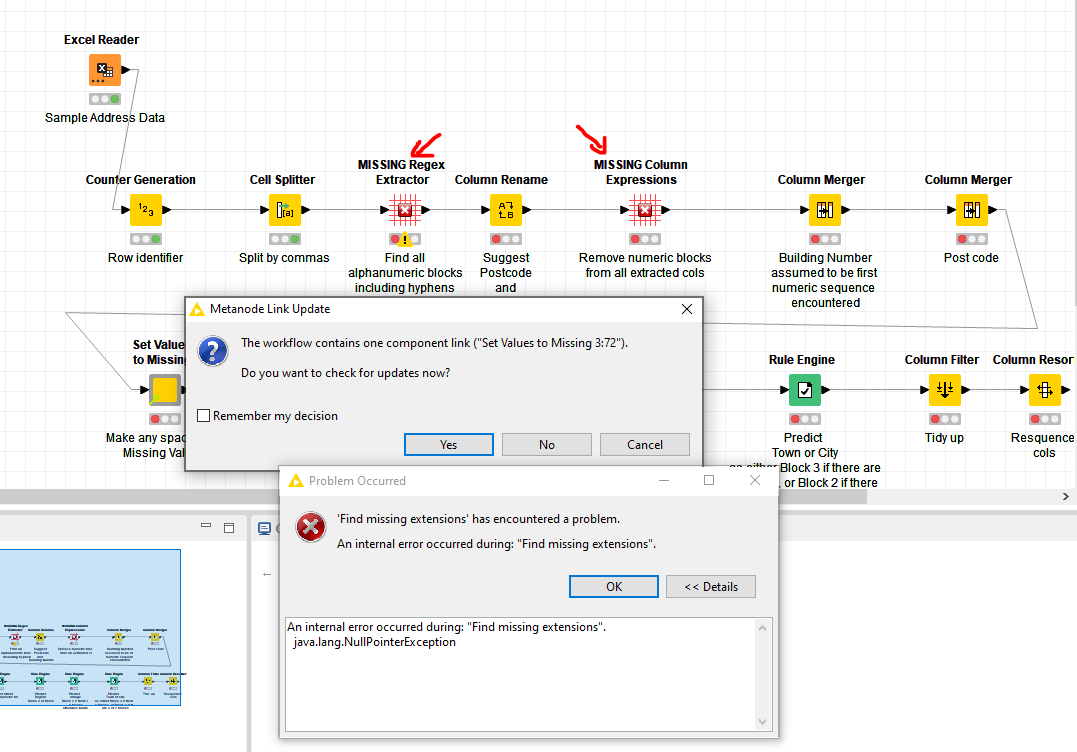
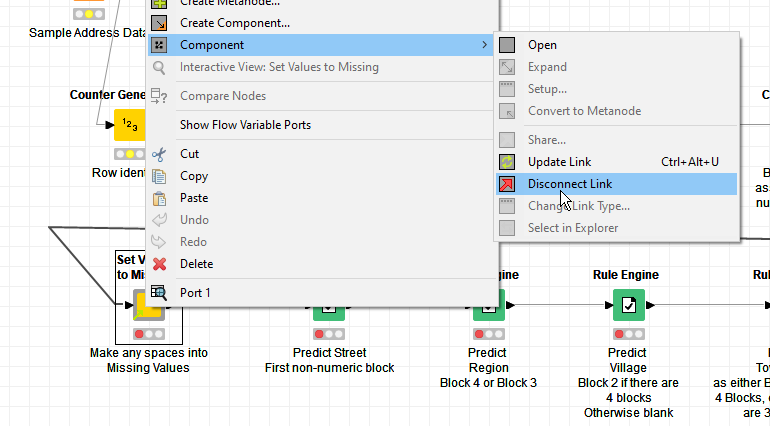
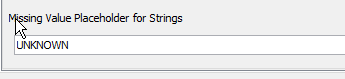
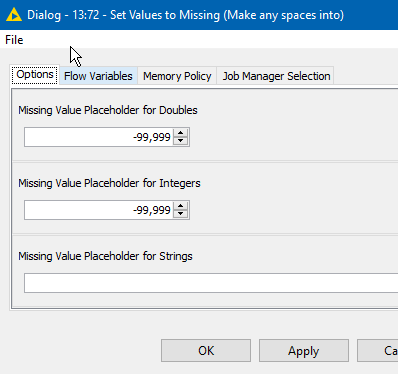
Anyway so I worked on the basis of these certain assumptions and attached is the workflow I produced. Maybe it can give some ideas on how to improve, or maybe you can think of some other refinements for specific cases that you can identify.
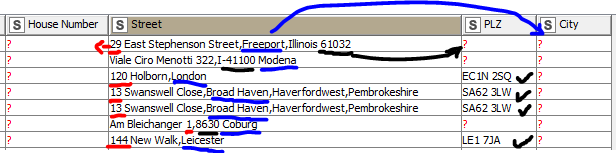
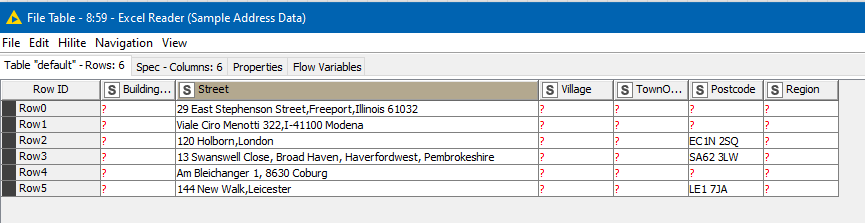
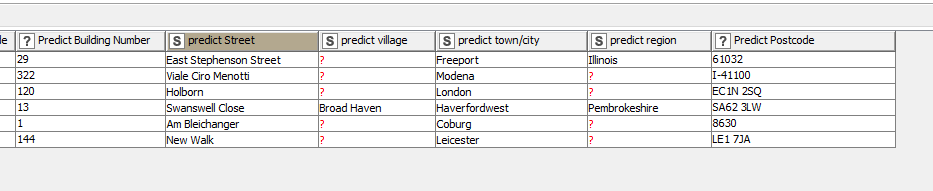
I made a spreadsheet based on your sample data
And it takes this and produces new columns predicting the address components:
KNIME_infer_addresses.knwf (78.6 KB)
If the UK postcodes had been embedded only within the Street address, rather than already isolated, then these would have to have been detected separately (probably some first stage regex looking for UK postcode patterns and pulling those out first.
Anyway, I hope it helps, or at least gives some ideas.