hhkim
May 21, 2025, 2:38am
1
Hello.
I’m trying to use a spark cluster in databricks connected to a knime pyspark source node.
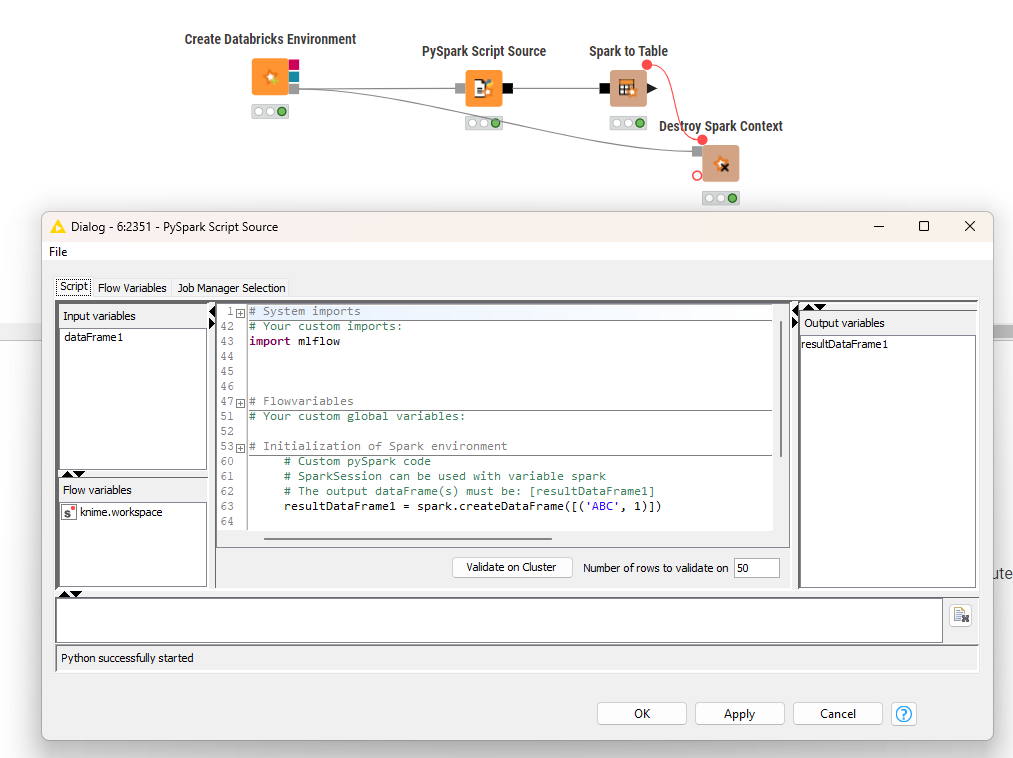
So I connected this cluster using the Create Databricks Environment node and it works fine.
I also installed the “mlflow” library on this cluster in databricks, and when I ran the python code with the mlflow library, it ran fine.
But when I ran the same python code on the pyspark source node in knime, it failed.
So I’m wondering how I can control the python library in this case.
I’d appreciate if someone can help me
Hello @hhkim ,
If the Python library like mlflow is installed directly on your Databricks cluster but not working in KNIME’s PySpark Script node, it might be because the Spark job runs in a different environment (not the notebook one).
I tried using suggestions from ChatGPT:
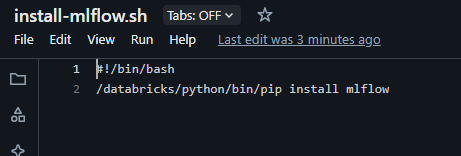
#!/bin/bash
/databricks/python/bin/pip install mlflow
(What are init scripts? | Databricks Documentation )
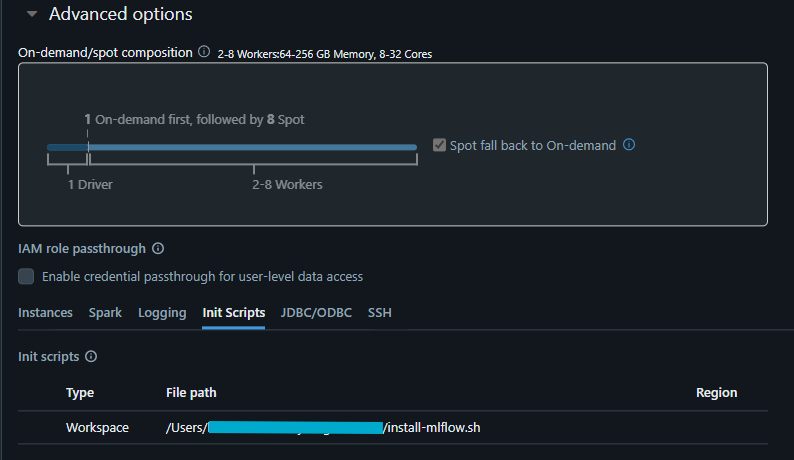
Upload it under your workspace path and add it in the cluster’s init scripts.
Then restart the cluster and try again.
I was able to import mlflow in the pyspark script source node, I haven’t tried logging runs but the import worked fine
Alternatively Use Databricks Runtime ML version (11.3 LTS ML ), which includes mlflow and other common ML libraries by default.
Hope this helps.
Best,
1 Like
hhkim
June 19, 2025, 9:54am
3
Thank you for your help!
Best Regards,
system
September 17, 2025, 9:55am
4
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.