I am a beginner to knime. So, I didn’t know much, so I signed up here. (I am using a translator in a non-English speaking country. Please understand if the English is awkward)
What I want to ask here is, is it possible to insert a variable in the #table# part of the SQL statement, and how to do it if possible?
If you look at the SQL Statement menu in the Database Reader Configuration, it says’Select * from #table#’. I know that if the table name in DB is put in #table#, the selected data goes up in memory.
I want to automatically insert the data read from another Database Reader into #table# without entering it directly in the #table# part.
For example, I want to use Table_name read from All_tables of Oracle as a variable and insert it into #table# part of SQL Statement of Database Reader.
Hi,
the #table# part is the placeholder for the incoming query and not meant to be replaced by the user. I would suggest to use the variable with the table name in a DB Table Selector node instead. That will automatically produce the "SELECT * FROM ". That can then be followed by other in-database processing nodes such as the DB Row Filter. In the end, you can get your data into KNIME with a DB Reader.
Kind regards,
Alexander
The last thing I want is to migrate data from Oracle to another DB using Knime. To do this, the work order I thought of is as follows.
Step 1. Obtain all Table_name from All_tables of Oracle DB
Step 2. Using a Loop Node (just like a for or while function), each Table_name is a variable, and when one loop runs from the Database Reader to Select * from [table_name], data from one table is received.
Step 3. Before the loop ends, insert the database writer node and insert the data just received from the reader into an empty table in another DB.
Step 4. Loop continues until all table data is migrated, and when finished, the operation ends with Loop End Node.
For the above work I thought, I want the #table# part of the SQL Statement to change every time the Loop runs with the Table_name received in Step 1 as a variable.
Is there any way I can do it my way? Or should I change the work step I think or the node I use?
Please ask for a lot of advice. I will humbly accept it.
Thanks for the advice. Through your advice, I have completed Step 3. However, Loop generates an error and does not work properly. Do you know how to do this?
First, it is a node structure diagram currently designed.
Two things: why would you download the data from the database. Maybe it is better to use a Variable Loop End that would not try to collect all data.
Of course it is possible to download the data and upload it to the DB. The example of Tobias would use streaming so the data would not have to touch the disk. You would have to try if this gives you a good performance.
I solved that part using Variable Loop End Node. The loop works fine for most data.
However, a memory error occurred while migrating over 200 million data. The Database Reader Node was fine, but it occurred while the Database Writer Node was about 60% in progress and the operation failed.
The contents of the error are as follows.
ERROR DB Writer 4:18 Execute failed: Error while adding rows #-1000-#0, reason: No more available memory in PSF. Try again later.
WARN DB Writer 4:18 Node configuration was aborted after 3 seconds. To change the timeout parameter’Retrieve in configure timeout’ go to the’Advanced’ tab of the database connector node.
Is this error only needed to change the Advanced Tab-Retrieve in configure of Database Connector node? If it is correct, I want to know how many numbers to write. If you need more configuration changes, I’d like to know that too.
Perhaps if you solve this problem, everything will work fine.
You could try and increase the timeout setting as mentioned. Maybe 5 or 10 seconds. And you might have to see how large a chunk you would stream.
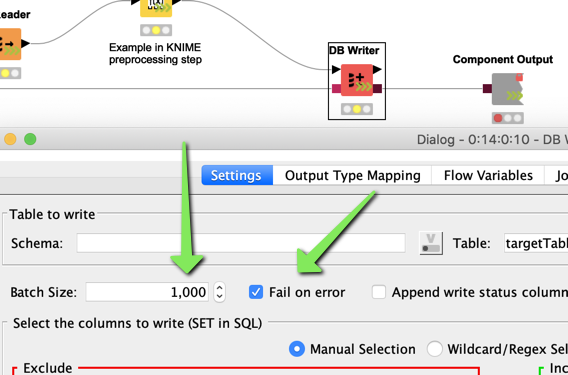
Also you could try and reduce the chunk size. Also you could disable fail on error which carries the risk that errors might get unnoticed.
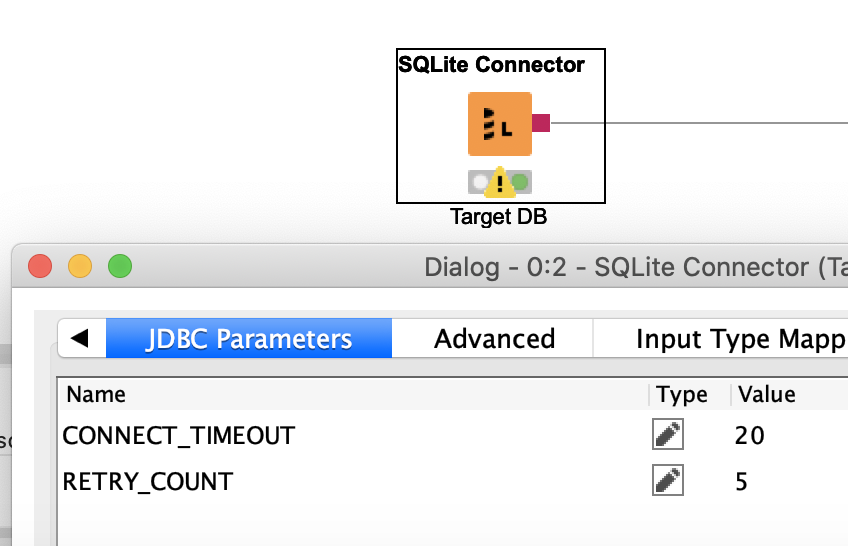
Also you could check with your database if you could adapt the CONNECT_TIMEOUT and RETRY_COUNT (or a similar parameter) that could make the connection more stable.
I tried to put GroupBy Node between DB Reader and DB Writer in my workflow. However, after reading the first table in DB Reader, after reading a table with a different column configuration (column name, number of columns) from the previous table, the Group Column Filter of GroupBy Node did not work properly. Is there a way to do this automatically?
then you could extract the structure of each table and construct a SQL string and insert that via Flowvariable - so you have an individual group by that would adapt to your data structure
You could have a ‘standard’ part like every table hold a no_of_purchases variable that you would have as: SUM(no_of_purchases) as sum_no_of_purchases
Question is if this would go along with the streaming - because group by would need to know about the whole database in order to do its thing (or might just handle the streamed portion which would not be good).
Depending on what you want to do it might makes sense to do the transformations (grouping) in your original database and then just stream the result - since this topic was (originally) about transfer performance.