Hi, I’ve a workflow that runs a python script, and as part of the script it saves the output to a .parquet file, which I store ‘locally’ in EC2 storage on my AWS KNIME Server. When I then run another workflow immediately after to read that same file I get an error. The error varies but is typically either:
There are messages for workflow “SOH_Vans_Latest_v5 2021-11-05 08.51.32”
Parquet Reader 6:1462 - ERROR: Execute failed: nio-wrapper://xxxx/_out_Fact/SOH_Vans_L28D.parquet is not a Parquet file. expected magic number at tail [80, 65, 82, 49] but found [100, 71, 70, 107]
Or:
There are messages for workflow “SOH_Vans_Latest_v5 2021-11-05 10.33.02”
Parquet Reader 5:1462 - ERROR: Execute failed: (“EOFException”): null
When I stop and then restart the KNIME server (as opposed to AWS Instance), however, I can then read the .parquet file without fail.
Is there some behaviour whereby KNIME keeps files open/connected? I’ve tried waiting 5secs between the ‘write’ workflow ending and the ‘read’ workflow starting but to no avail.
Does anyone have any suggestions as stopping/starting the KNIME Server is not what I want to be doing? Thanks, Dom
how odd. Can you reliably read other parquet files that haven’t just been written by the python script?
The python code runs mostly outside our control. I can imagine that the script may not finish correctly and it only terminates once the KNIME server is restarted (as python was probably launched as a sub-process). Maybe it also takes a while to flush a buffer to disk. I guess 5 seconds should suffice, but for testing purposes, could you try waiting a while longer, specifically a few minutes?
What KNIME version are you running and what python library are you using to write out the files?
@dpowyslybbe I recently also have seen this error but would have to search where and what I did. It was in some example I created.
You might try different compressions like uncompressed, snappy or gzip and see if that does make a difference.
Also you might provide us with the exact version numbers of KNIME python and pyarrow. I just yesterday had a strange problem with a fresh python 3.9 version installed via miniconda and conda-forge repository (under Windows 10) where suddenly snappy would not be ‘supported’ - ‘solved’ this by switching to gzip. So unfortunately there are sometimes compatibility issues between various python versions, packages, operating systems and even repositories …
Then you could try and use ORC as a workaround to transfer the file if this does not disrupt your workflow to much.
Another workaround could be to use SQLite to transfer the data:
Hi, yes I can read parquet files written by other means without the same problem. But FYI there are a couple of reasons I use python to write the .parquet files, in part due to speed: It actually takes less time for python to write as a .parquet than it does to output the data from the python script node to, say, a parquet writer node.
It doesn’t seem to be a time related thing, as I’ve waited a fair few minutes. I’ve also tried writing a second smaller parquet file in the hope this ‘closes’ the first but it doesn’t seem to work.
Regarding setup, I’m using KNIME Server 4.13 on AWS, with pyarrow 5.0.0 and pandas 1.3.3 on python 3.9.7 to write the parquet files, and my executor preferences are as follows:
thanks for the updates. I so far haven’t been able to reproduce the issue, but I do have two thoughts:
Jobs (or python scripts) aren’t properly finishing.
Since you can solve the issue by restarting the KNIME server, it still sounds like something isn’t properly writing out a buffer. Would it be possible to check whether jobs that create parquet files actually finish (WebPortal → Monitoring → Jobs)?
Version difference (python/pyarrow) between client and server.
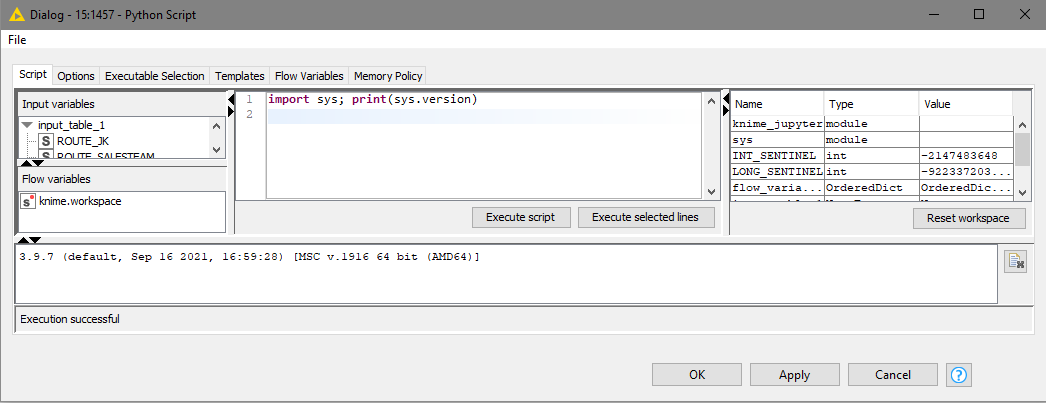
The executor configuration names a py3_knime conda environment, which is our default name. If it is a default installation, it will probably pack python 3.6.13 (see import sys; print(sys.version)). An older python/library version probably isn’t the sole cause for the issue, but may help reproducing the issue.
Is it possible for you to share two very simple workflows that cause the issue? The data written can of course be completely meaningless (use e.g. Data Generator – KNIME Hub).
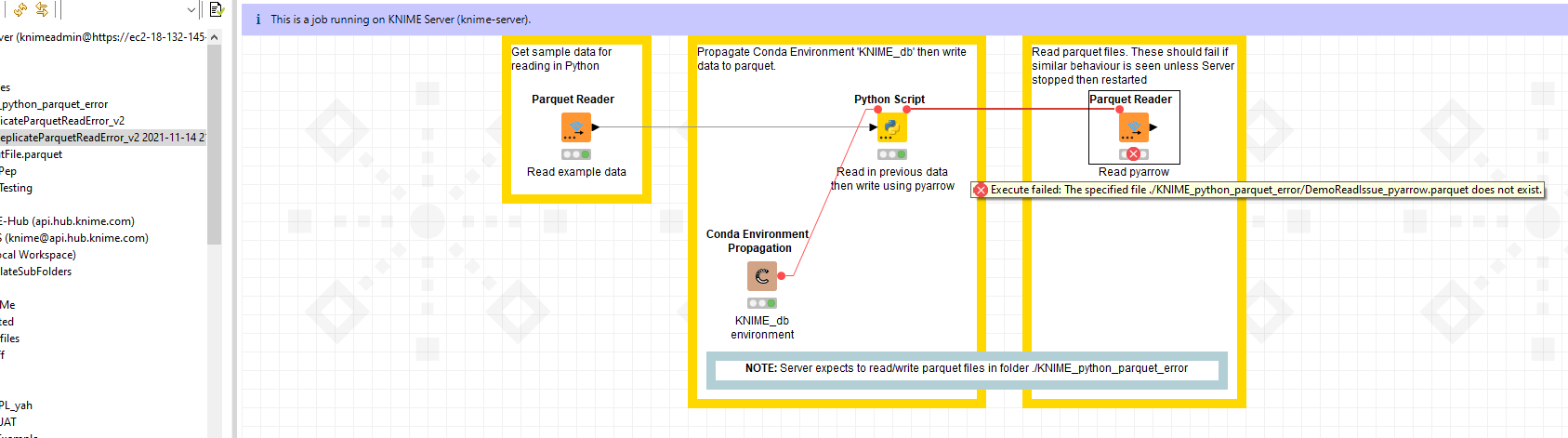
Attached is a single workflow that reads in an example version of the data (same column types) then writes it to .parquet using python, with a separate node to read the newly created file. KNIME_python_parquet_error.knar (112.7 KB)
You’ll note in this case I get the ‘File does not exist’ error, but I’ve also seen ‘EOFException’ and ‘expected magic number’ errors as previously explained.
thanks for the follow-up and your tests. I played around a bit with your workflow, but could not reproduce the error.
The missing file may be a slight misconfiguration. However, the other issues look like they may be caused by the location we are writing to[1]. Could you try a different location on the server, e.g. /tmp/ (see my workflow version: KNIME_python_parquet_error.knar (20.1 KB)).
Additionally, the Python configuration window will run evaluations locally (even in the remote workflow editor), so the Python version we see here is your local version. Likely the server has the same version (as it is specified in the environment propagation), but if you want to test that, run the script in the RWE and set your console level to INFO, so that it will display the Python stdout (File → Preferences → KNIME → (click on) KNIME GUI → Console View Log Level).
Kind regards
Marvin
[1] Writing files to the workflow location:
We assume that server (including the repository) and the executor(s) (which run workflows) may be on different machines. Therefore, we copy workflows to the executor at execution and sync back results after execution.
If a workflow now directly saves to the workflow area on the server, this can cause issues when syncing between executor and server.
were you able to try saving the data to another location? In case your executor isn’t configured to access the local file system, you can enable it as an executor preference (see here).
I’m coming back to this a very long time later (as I had found a non-KNIME workround) but I’ve now found a solution that was more-or-less along the lines of what marvin.kickuth mentioned.
Details are as follows:
Issue: KNIME struggles to read .parquet files created by python when attempting to use the .parquet read node in the same session (see above posts)
Solution - part A: Enable knime server to access the local file system by modifying the preferences file as mentioned in the post above.
Solution - part B: Read the .parquet file using the Local File System path (as for some reason this works whereas the Relative To Current Mountpoint path doesn’t).
For info I initially managed to read parquet files from a folder in a different location to the server. Whilst this worked it was not ideal as for simplicity I wanted to be able to see the files in the KNIME explorer. I therefore decided to keep the files within the mountpoint but built a component to determine the local path to the files depending on whether I was running the workflow on a local machine or server. And it was once this worked that it became obvious that the issue was due to the parquet reader node not working properly using the Relative to Current Mountpoint path, whereas it did work using a local path.