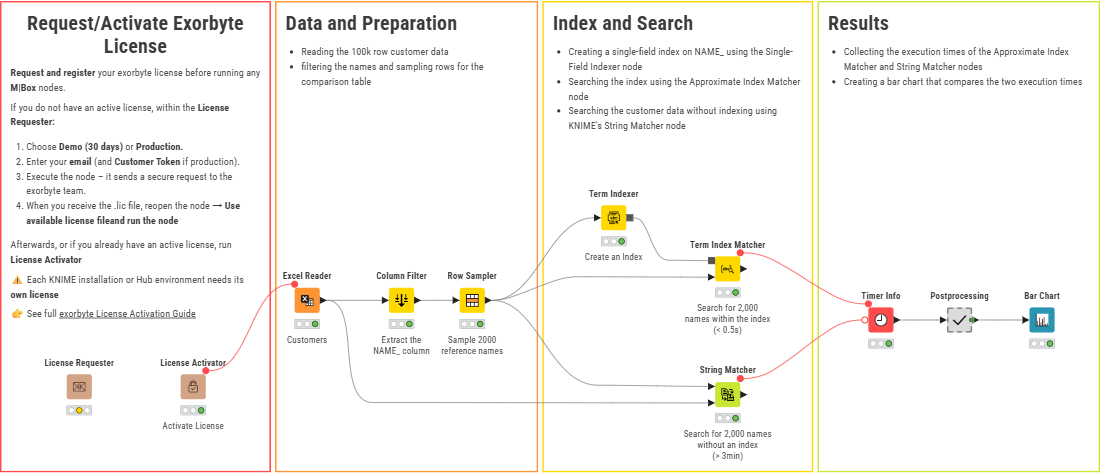
Approximate Matching & Index-based Retrieval in KNIME (exorbyte Nodes)
Exact joins are a bottleneck in many KNIME workflows.
As soon as data becomes even slightly inconsistent (typos, different encodings, missing fields), classical joins and rule-based pipelines start to break down.
We’ve released a set of KNIME nodes that address exactly this layer:
![]() exorbyte matchmaker toolbox (M|BOX)
exorbyte matchmaker toolbox (M|BOX)
What it actually does (technical view):
| Builds an in-memory index over structured or semi-structured data
| Executes approximate queries against the entire index
| Supports multi-attribute matching with configurable weighting
Returns:
| best match
| similarity score
| optional alignment information
𝗡𝗼 𝗯𝗹𝗼𝗰𝗸𝗶𝗻𝗴, 𝗻𝗼 𝗰𝗮𝗻𝗱𝗶𝗱𝗮𝘁𝗲 𝗽𝗿𝗲𝘀𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻, 𝗻𝗼 𝗽𝗿𝘂𝗻𝗶𝗻𝗴.
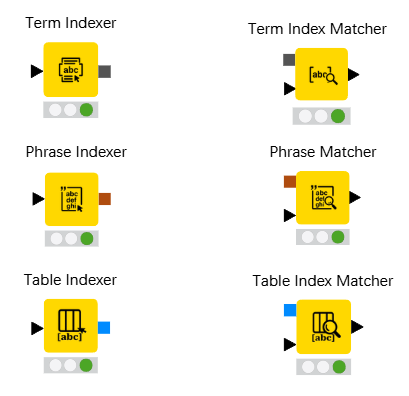
Core nodes:
Table Indexer
→ builds a multi-field index (e.g. name, address, id fragments)
Table Index Matcher
→ queries the index with fuzzy logic across all fields
Approximate String Matcher
→ pairwise similarity (Levenshtein, LCS, positional methods)
Character Mapper
→ normalization layer (diacritics, variants, encoding issues)
What’s different compared to typical KNIME approaches:
Not a join → index-based retrieval problem
Not ML → deterministic, explainable scoring
Not preprocessing-heavy → works on dirty data directly
Where this becomes relevant:
Identity resolution across heterogeneous sources
KYC / sanctions screening pipelines
OCR / ICR post-processing (error-tolerant lookup)
Product or entity matching without stable identifiers
Typical workflow pattern:
Normalize input (optional)
Build index once
Query repeatedly
Post-process matches (thresholding, routing, enrichment)
If you’re working on anything where:
joins are failing
rules are exploding
or preprocessing becomes the main workload
this might be a useful addition to your KNIME setup.
![]() Extension + example workflows:
Extension + example workflows:
https://lnkd.in/eqk8giDa